Spark MLib算法详解:各类模型的代码实现与应用
版权申诉
133 浏览量
更新于2024-06-27
收藏 2.23MB DOCX 举报
本文档详细介绍了Apache Spark MLlib库中的多种机器学习算法及其应用,分为三个主要章节:分类与回归、协同过滤以及聚类。以下是每个部分的主要知识点:
1. **分类与回归**:
- **支持向量机 (SVM)**: 一种监督学习算法,通过构造最优超平面进行分类。输入参数包括核函数类型、惩罚参数等。代码展示了如何在Spark MLlib中实现SVM,并给出了实际应用场景,如文本分类或异常检测。
- **逻辑回归**: 用于预测二分类或多分类问题的线性模型。输入参数涉及截距项、正则化系数等。代码演示了如何构建和训练逻辑回归模型。
- **线性回归**: 基于最小二乘法的连续值预测模型。输入参数可能有特征权重、正则化参数等。代码展示了如何在Spark中使用线性回归。
- **朴素贝叶斯**: 基于贝叶斯定理的简单概率分类方法,假设特征独立。输入包括特征条件概率等。代码例程展示了朴素贝叶斯分类器的使用。
- **决策树**: 分裂数据集形成树状结构的模型,可以做分类或回归。输入包括树的最大深度、节点分裂策略等。代码展示了决策树的构建和应用。
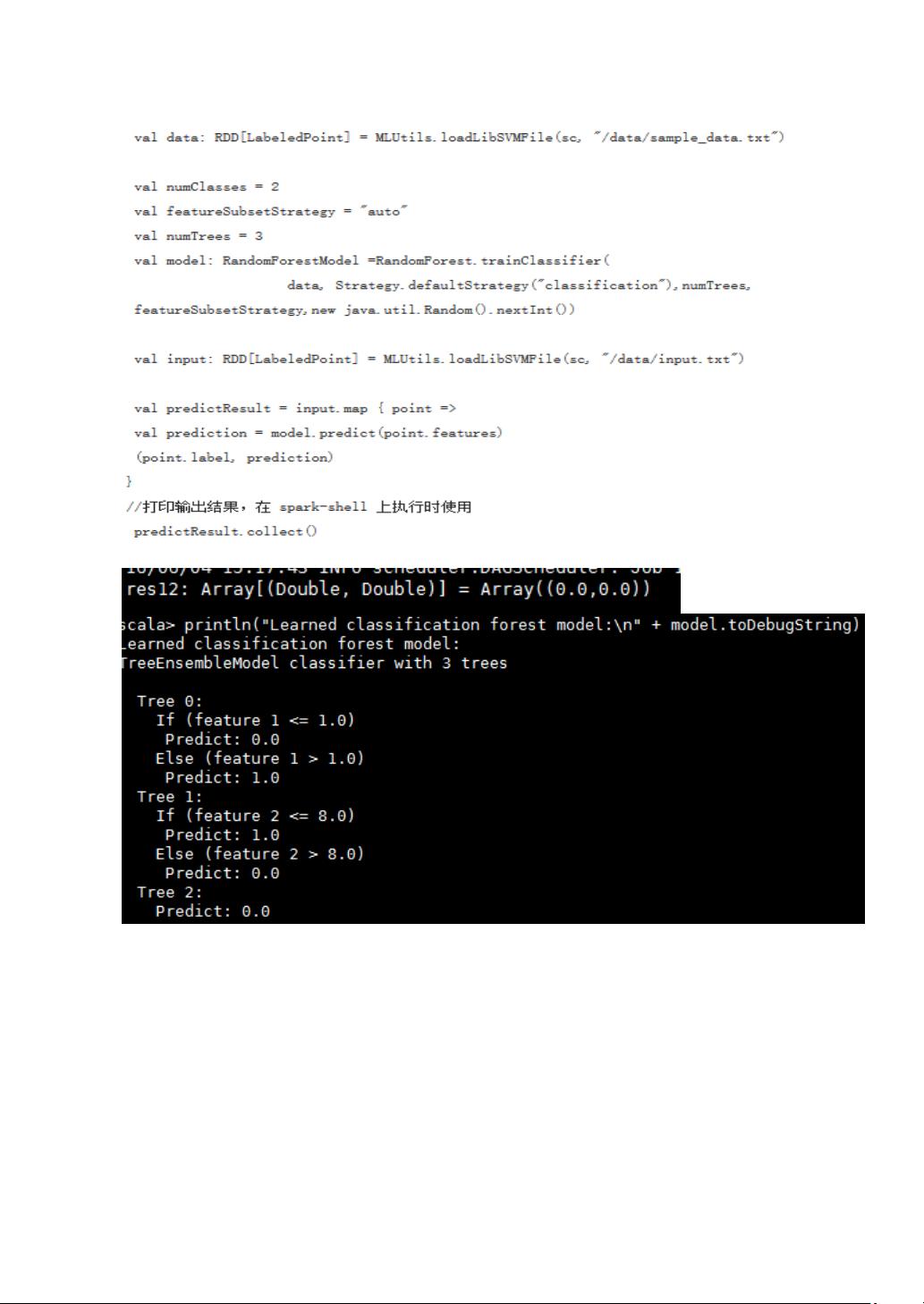
- **随机森林**: 集成多个决策树的模型,用于提高预测准确性和鲁棒性。输入涉及树的数量、特征子集选择等。
- **梯度提升树**: 逐步增强弱分类器的集成方法,适用于回归和分类。输入参数有学习率、树的数量等。
- **保序回归**: 保持输出变量顺序的回归算法,常用于排序任务。输入包括正则化参数等。
2. **协同过滤**:
- **协同过滤算法**: 基于用户或物品的历史行为进行推荐,分为用户-用户和物品-物品两种。输入涉及相似度计算方法和推荐阈值等。
- 示例代码展示了如何利用Spark MLlib进行协同过滤,以及其实用场景,如电影推荐系统。
3. **聚类**:
- **K-means**: 基于距离的硬聚类算法,将数据分为固定数量的簇。输入有初始聚类中心、迭代次数等。
- **高斯混合模型 (GMM)**: 混合多个高斯分布来建模数据,可处理非凸形状的簇。输入包括混合成分数量等。
- **快速迭代聚类 (FIC)**: 一种改进的聚类算法,适用于大数据集。输入涉及到迭代次数和收敛条件。
- **三层贝叶斯概率模型**: 可能是一种特定类型的聚类算法,利用贝叶斯网络进行分类。
- **二分K-means**: 对K-means的一种优化,通过递归划分减少计算复杂性。输入涉及分割策略等。
整个文档提供了一套全面的Spark MLlib算法指南,包括每种算法的工作原理、关键参数解读以及在实际项目中的应用场景和代码示例,适合数据科学家和工程师深入理解和实践使用。



2024-08-25 上传
2021-12-15 上传

猫一样的女子245
- 粉丝: 231
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- myeclipse关于JDK,TOMCAT部署,环境变量的配置
- Linux操作系统下C语言编程入门.pdf
- oracle传输表空间实例.doc
- IBM-PC汇编语言程序设计答案
- GCC 中文手册,gcc的中文文档
- Programming Microsoft Windows CE .NET, Third Edition(中文教材)
- ASP.NET 程式设计基础篇
- Spring-Eclipse
- Microsoft编写优质无错C程序秘诀
- 罗克露老师-组成原理样题试卷
- Spring OSGi 入门
- rc026-010d-spring_annotations.pdf
- Programming with Equinox
- Programming.Firefox
- Spring OSGi规范(v0.7)中文版
- JavaScript高级教程
