MySQL查询优化:索引、Extra与效率解析
需积分: 0 53 浏览量
更新于2024-08-04
收藏 133KB DOCX 举报
在MySQL查询优化中,分号的使用和查询执行计划的解读至关重要。首先,查询语句中的分号通常表示逻辑分隔,但在某些情况下,如`Usingwhere;Usingindex`,它可能表明查询执行时的两个阶段。`Usingwhere`表明查询没有利用索引来优化,而`Usingindex`则意味着至少部分查询是通过索引进行的,这被称为“覆盖索引”。
案例4.1中,如果`Extra`列出现了三次分号,可能是因为额外的排序操作导致,这会影响查询性能。当`Usingwhere`与`Usingindex`同时存在,可能是因为虽然某个条件没有使用索引(如c5字段),但其他部分使用了。
`key_len`,即键的长度,反映了索引的效率。一般来说,较短的`key_len`意味着更优的索引,因为它占用空间较少且查询速度更快。然而,这并不意味着越短越好,要综合考虑索引设计、查询需求等因素。
在表连接中,如`LEFT JOIN`,如果连接条件是`in`或`exists`,通常不会遵循小表驱动大表的原则,但必须确保连接字段有适当的索引来提高性能。联合索引在表数据量大且需要多条件组合查询时非常有用,因为它们能减少查询所需的I/O操作。
MySQL的`FILESORT`通常涉及排序操作,分为单路和双路,具体实现取决于数据量和硬件配置。它可能导致额外的I/O,但通过合理设计索引,可以最小化这种情况。
当涉及到索引使用时,并非所有查询都仅依赖内存缓存,如果没有将所有索引加载到内存,数据库系统可能会进行磁盘I/O。然而,现代数据库设计倾向于减少I/O,提升查询速度。
SQL查询效率的问题在于查询顺序对表扫描的影响。例如,如果外层表(A)的大小远大于内层表(B),即使外层查询次数较多(如`A.id=1000`),由于关联操作后结果集较小,整体执行效率仍可能较高。这与Java中的循环相似,但SQL优化器根据表的大小和关联策略调整了查询顺序,从而达到更高的性能。因此,SQL语句的比对次数并不是简单的乘法关系,而是取决于查询的执行计划和数据分布。
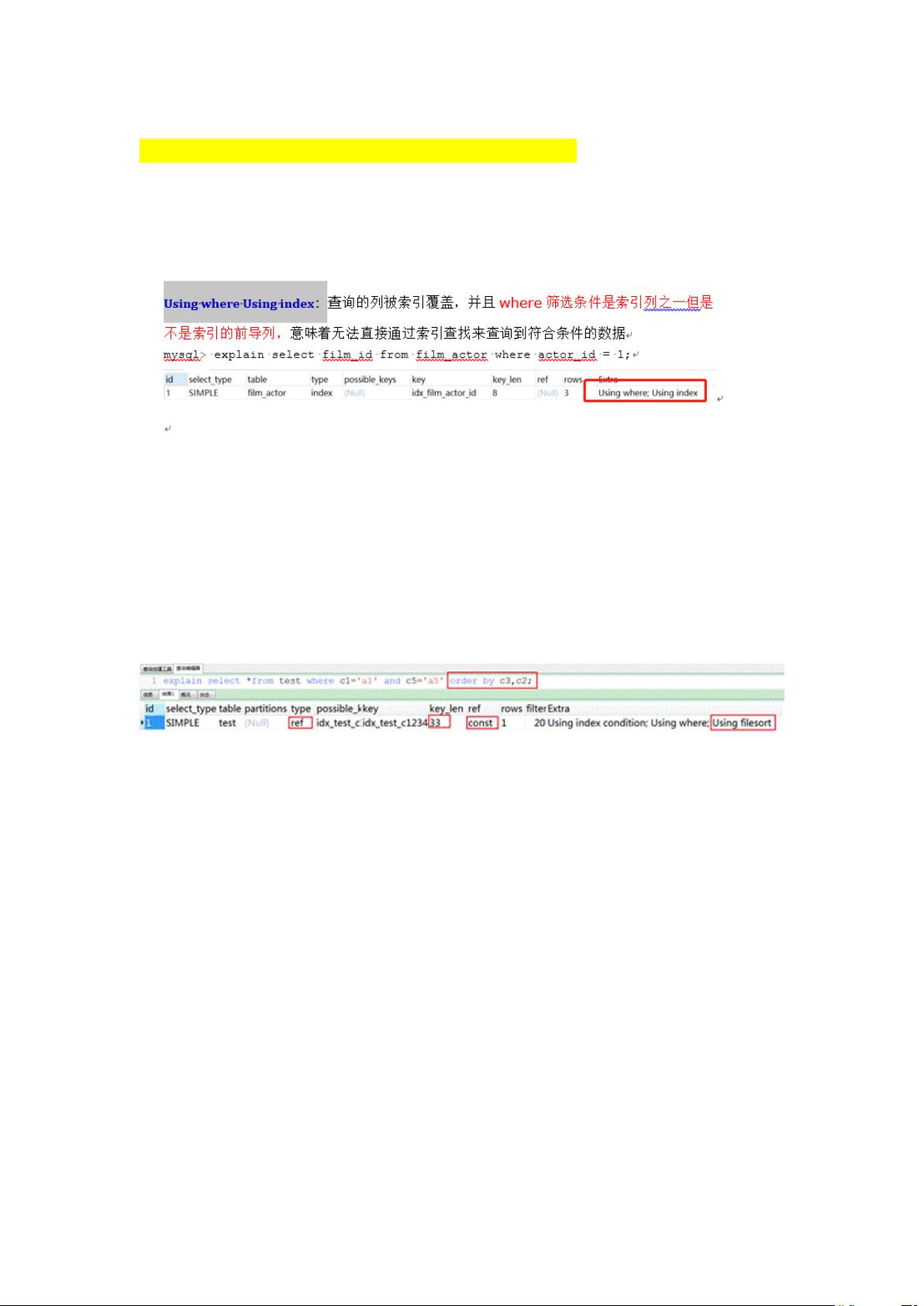
总的来说,不太明白一个查询,会有几个分号(H36)
1 Using where Using index:
这里面为什么显示为 Using where;Using index
诸葛:Extra 是附加信息列,可以有多个值的,Using where; Using index 中的
Using where 代表查询语句没用用到索引, Using index 代表 select 用到了覆盖索引
2
Case4.1:
这里面为什么出现三次,是两个分号。
诸葛:同上面解释,这里 extra 里多了文件排序
3 不知道这个地方为什么多了个 using where
下载后可阅读完整内容,剩余3页未读,立即下载
2017-06-02 上传
184 浏览量
105 浏览量
108 浏览量
2023-03-05 上传
122 浏览量
134 浏览量
2019-08-02 上传
2021-06-30 上传

滕扬Lance
- 粉丝: 28
- 资源: 304
 我的内容管理
展开
我的内容管理
展开







最新资源
- arhaica:古代Web的Milti-Domain内容发布系统
- MeetingAppointment.zip_.net mvc_C#_bootstrap .net_mvc_预约
- grao:PoC Stara Zagora GRAO个人数据泄露
- 数字图像处理知识点总结.zip
- 网钛远程桌面管理助手 v3.10
- estimo:评估浏览器执行您JavaScript代码的时间
- NLP4SocialGood_Papers:有关NLP for Social Good的最新论文的阅读清单
- 影刀RPA系列公开课5:手机操作自动化.rar
- 毕加索用于光刻的图像加载组件-Android开发
- PGAT-开源
- fruit-recognition-master.zip_QT图像识别_opencv_qt 图像处理_qt 图像识别_水果种类识
- 影刀RPA系列公开课5:手机操作自动化.rar
- 74项环流指数读取软件
- kosa:知识组织系统(KOS)的轻量级聚合器
- 最新版面试宝典最终版.zip
- Shibboleth-Multi-Context-Broker:Shibboleth多上下文代理
