动态网站爬虫实践:Python抓取视频URL并合并
76 浏览量
更新于2024-08-30
2
收藏 940KB PDF 举报
在这个教程中,作者分享了如何使用Python爬虫技术从一个动态加载的视频资源网站下载视频的经历。首先,作者提到遇到的挑战是网站采用动态加载方式,常规的源代码分析无法直接获取视频链接。动态网页爬取通常涉及到两种方法:一是解析JavaScript返回的JSON数据,二是利用Selenium进行模拟浏览器行为。
1. **网站分析**:
- 作者通过F12开发者工具检查网页,注意到每次刷新出现大量JavaScript文件,且响应内容与源代码不同,表明网站采用了动态加载策略。
- 动态加载可能导致源代码中不包含直接的视频链接,而是通过AJAX或类似技术获取。
2. **动态加载策略**:
- 作者尝试通过抓包工具(如Chrome的Network功能)来追踪视频链接,发现在HXR(XMLHttpRequest)响应中找到.m3u8文件,以及后续的.ts文件。
- m3u8是一个MPEG-DASH(动态 Adaptive Streaming over HTTP)的播放列表,由多个ts(Transport Stream)文件组成,需下载并合并才能播放。
3. **视频URL解码**:
- 面对.m3u8链接,直接访问并未得到视频,而是ts片段,说明需要进一步处理。
- 时间戳在URL中的存在提示可能是一种防止爬虫的反爬策略,需要被考虑在内。
4. **数据抓取与整合**:
- 通过抓包发现,首页的视频信息存储在一个包含分类ID(tagid)和图片地址的API中,但没有直接的分类链接。
- 对不同分类进行抓包后,作者识别出URL结构中有特定的模式(`https://xxxxxxx&c=video&m=categories`),tagid对应不同的分类,且URL尾部附加了时间戳。
5. **爬取策略**:
- 为了获取完整的视频列表,作者需要根据抓取到的规律,构建一个能动态获取不同分类视频的爬虫,包括遍历tagid和时间戳,以获取每个分类的完整视频资源。
总结起来,Python爬取动态视频资源的关键在于解析动态内容、跟踪HTTP请求和响应头、理解网站的反爬策略,并利用这些信息动态构建请求以获取所需视频。同时,对于.m3u8和ts文件的处理也是爬虫过程中的重要环节,需要对MPEG-DASH标准有所了解。这个过程不仅考验了编程技能,还涉及到对网络协议和Web开发技术的理解。
Python爬取某视频并下载爬取某视频并下载
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法。
下面说说流程:
一、网站分析一、网站分析
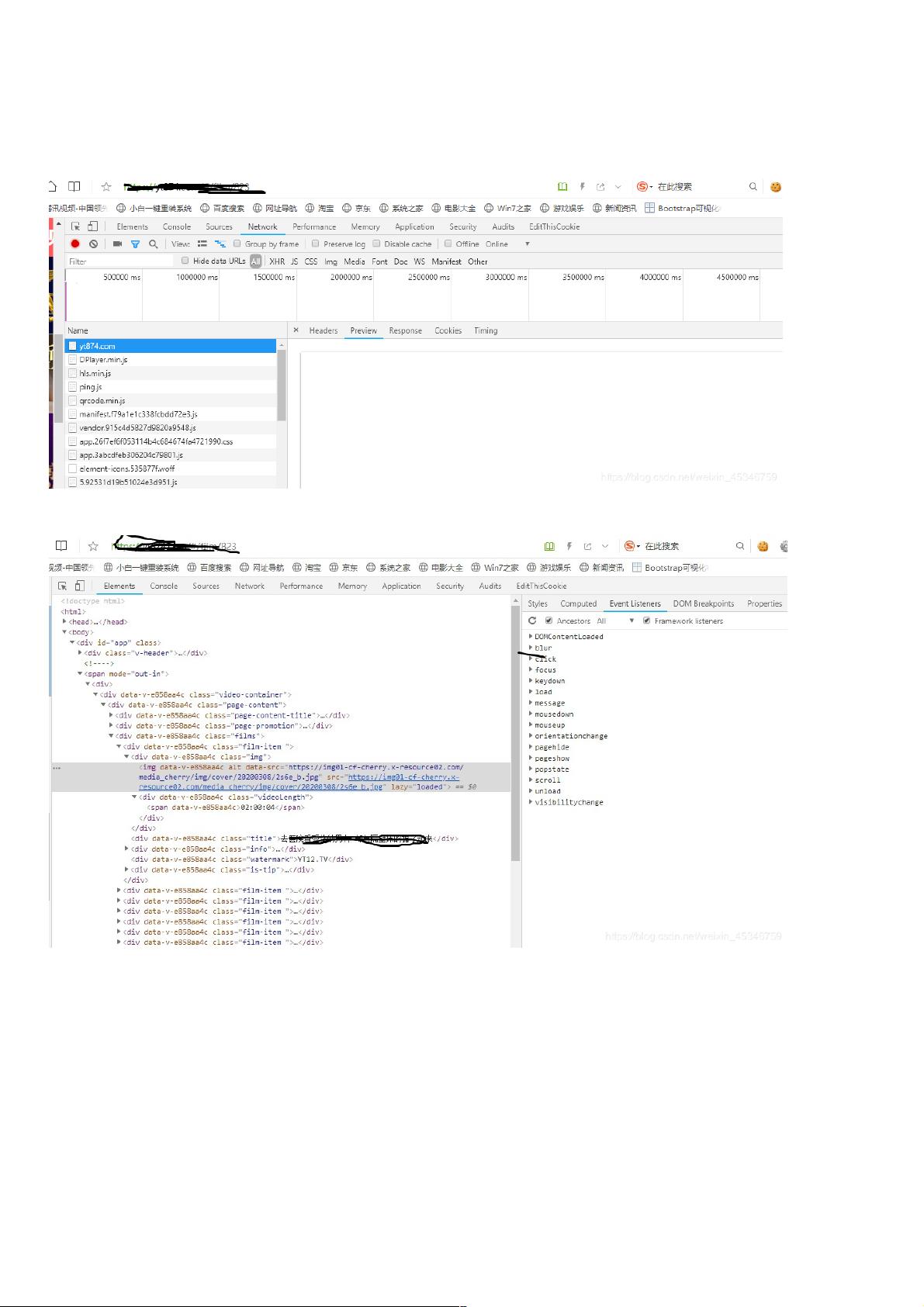
首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主。可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜
到这个网站是动态加载页面。
目前我知道的动态网页爬取的方法只有这两种:1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium对网页进行模拟访问。源代码问题好解决,重要的是我获取的源代
码中有没有我需要的东西。我再一次进入网站进行F12检查源代码,点击左上角然后在页面点击一个视频获取一个元素的代码,结果里面没有嵌入的原视频链接(看来我真的是把别
人想的太笨了)。
没办法只有进行抓包,去找js请求的接口。再一次F12打开网页调试工具,点击单独的一个视频进行播放,然后在Network中筛选一下,只看HXR响应(HXR全称是
XMLHTTPRequest,HMLHTTP是AJAX网页开发技术的重要组成部分。除XML之外,XMLHTTP还能用于获取其它格式的数据,如JSON或者甚至纯文本。)。
下载后可阅读完整内容,剩余7页未读,立即下载
2019-03-02 上传
2024-02-03 上传
2024-02-02 上传
2024-02-02 上传
2024-02-02 上传
2024-02-02 上传
2022-05-26 上传

weixin_38644097
- 粉丝: 4
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
