Bloom Filter:空间效率与误差权衡的数据结构
需积分: 35 189 浏览量
更新于2024-07-31
收藏 416KB PDF 举报
“Bloom Filter概念和原理”
Bloom Filter是一种在计算机科学中广泛使用的概率数据结构,由Burton Bloom于1970年提出,主要用于高效地判断一个元素是否可能存在于一个大规模集合中。它的核心思想是在有限的空间内存储信息,以实现对集合成员资格的快速查询。由于Bloom Filter使用了多个独立的哈希函数,所以它能够在不存储实际元素的情况下,用位数组表示集合,从而极大地节省了存储空间。
Bloom Filter的工作原理基于以下几个关键点:
1. **位数组**:Bloom Filter使用一个固定长度的位数组,初始时所有位都设置为0。
2. **哈希函数**:它通常包含多个不同的、独立的哈希函数,每个函数将元素映射到位数组的不同位置上。当一个元素添加到过滤器时,这些哈希函数会将元素映射到数组的相应位置,并将这些位置设为1。
3. **查询**:对于查询操作,Bloom Filter会检查所有哈希函数映射的位置,如果所有位置都是1,则可能该元素在集合中;但如果有任何位置是0,那么该元素肯定不在集合中。这就是Bloom Filter可能导致假阳性的原因,即误判元素属于集合,但实际可能并不在。
Bloom Filter的应用场景广泛,包括但不限于:
- **缓存**:在缓存系统中,可以使用Bloom Filter来判断一个键是否存在于缓存中,避免无效的查找操作。
- **分布式系统**:在大型分布式数据库或搜索引擎中,Bloom Filter可以用来快速过滤掉不存在的节点或文档,减少网络通信成本。
- **网络路由**:在网络路由中,Bloom Filter可以帮助路由器快速识别并丢弃无效或不可达的IP地址。
- **去重**:在大数据处理中,Bloom Filter可以高效地检测重复的记录,尤其是在内存有限的情况下。
- **字典查找**:如描述中提到的自动分词程序,可以快速判断单词是否需要查词典,提高处理速度。
尽管Bloom Filter存在假阳性的问题,但通过选择合适的哈希函数数量k和位数组长度m,可以调整错误率到可接受的程度。错误率公式大约为:`p ≈ (1 - e^(-kn/m))^k`,其中n是集合中的元素数量。
为了进一步优化Bloom Filter,还出现了层次化Bloom Filter(Hierarchical Bloom Filters)等变体,它们可以更好地适应动态变化的集合,或者减少错误率。此外,还有一些扩展应用,如Counting Bloom Filter,它可以计数集合中元素的数量,而不仅仅是判断是否存在。
Bloom Filter以其高效的空间利用率和快速的查询性能,在许多需要快速判断成员资格但能接受一定错误率的场景中发挥了重要作用。然而,设计和使用Bloom Filter时,必须根据具体应用场景权衡错误率和存储空间,以达到最佳效果。

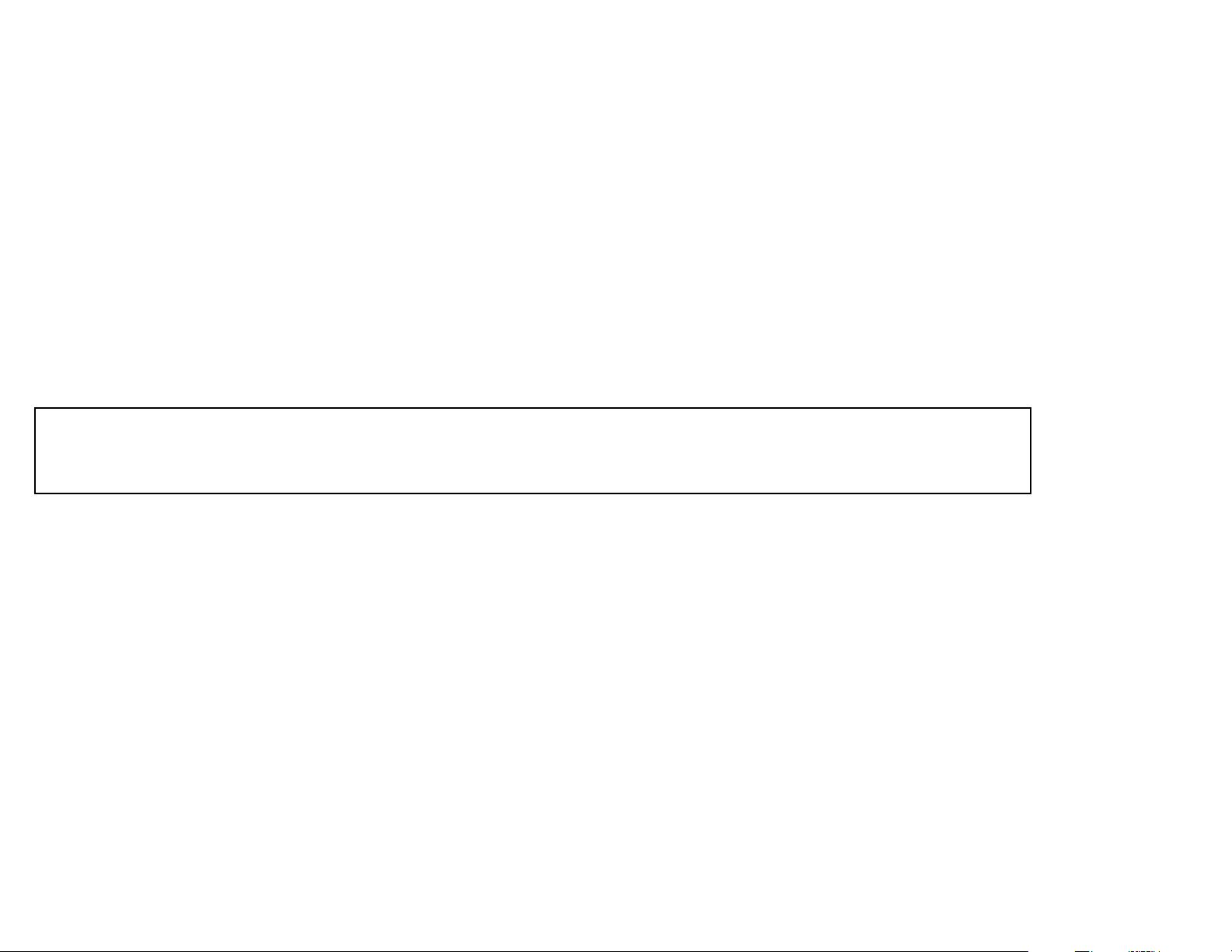
Choose k To Minimize False Positives
Since p = e
−
kn
m
, when p =
1
2
we have
k = ln 2 ·
m
n
Plugging back into f =
(
1 − p
)
k
, we find the minimum false
positive rate is
1
2
k
≈
(
.6185
)
m
n
Caveat: k must be an integer.
15


剩余112页未读,继续阅读
2021-03-12 上传
2012-07-26 上传
2020-09-05 上传
点击了解资源详情
2019-05-27 上传
2012-01-18 上传
2021-05-22 上传

yongyuandeqie
- 粉丝: 1
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
