DB2 DPF:数据分区与高性能管理
"DB2 DPF(Data Partitioning Feature)是一种用于大规模数据处理和高并发访问的技术,它在DB2企业版中作为选件提供。DPF通过采用Share-nothing体系结构,将数据库分解为独立的分区,每个分区拥有自己的资源,包括内存、CPU、磁盘和数据。这种设计使得数据通过Hash算法均匀分布,SQL操作由协调节点处理并分解为子任务在不同分区并行执行,最终将结果汇总给用户。数据库分区可以在集群或MPP环境以及单一SMP机器上部署,提供scaleup和scaleout的扩展能力。DB2 DPF支持最多1000个分区,允许通过增加逻辑分区(在同一台机器上)或物理分区(增加新机器)来扩展。此外,DPF还具备强大的并行处理能力,包括inter-partition parallelism和intra-partition parallelism,提高了系统性能和响应速度。在设计DB2数据库分区时,需要根据物理资源和应用需求来决定是垂直扩展还是水平扩展。"
DB2的DPF功能是为了解决大型数据库系统的性能和可扩展性问题。它基于Share-nothing架构,这意味着每个分区都独立运行,不共享任何硬件资源,从而减少了资源竞争和提升了并发性能。数据的分区策略通常使用Hash算法,确保数据均匀分布在整个系统中,提高查询效率。
在DPF中,当用户发起一个SQL请求时,协调节点(CoordinateNode)负责解析和分解这个请求,将任务分配给各个分区进行并行处理。这种并行处理分为两个层面:一是分区间的并行(inter-partition parallelism),通过Hash分区策略将请求分散到不同分区;二是分区内的并行(intra-partition parallelism),在同一分区内部,数据处理也能并行进行,进一步提升处理速度。
在规划DB2数据库分区时,需要考虑的是如何根据当前的硬件资源和预期的负载来确定扩展策略。如果现有的物理机器有充足的资源,可以通过增加逻辑分区(在同一台机器上创建更多分区)来实现垂直扩展,增加单机的处理能力。相反,如果需要处理更大的数据量或应对更高的并发,可能需要添加新的物理机器,即创建物理分区,这是水平扩展,可以扩展系统的整体容量。
DB2 DPF不仅提供了扩展性,还增强了系统的容错性和可用性。因为每个分区都是独立的,即使某个分区出现故障,其他分区仍然可以继续工作,保证了服务的连续性。
DB2 DPF是应对大数据和高并发场景的关键技术,通过智能的数据分区和并行处理,实现了数据库的高效运行和灵活扩展,为企业级数据库系统提供了强大的支撑。在实际应用中,设计和配置DPF需要综合考虑业务需求、硬件资源和性能优化等因素,以实现最佳的系统性能和可扩展性。
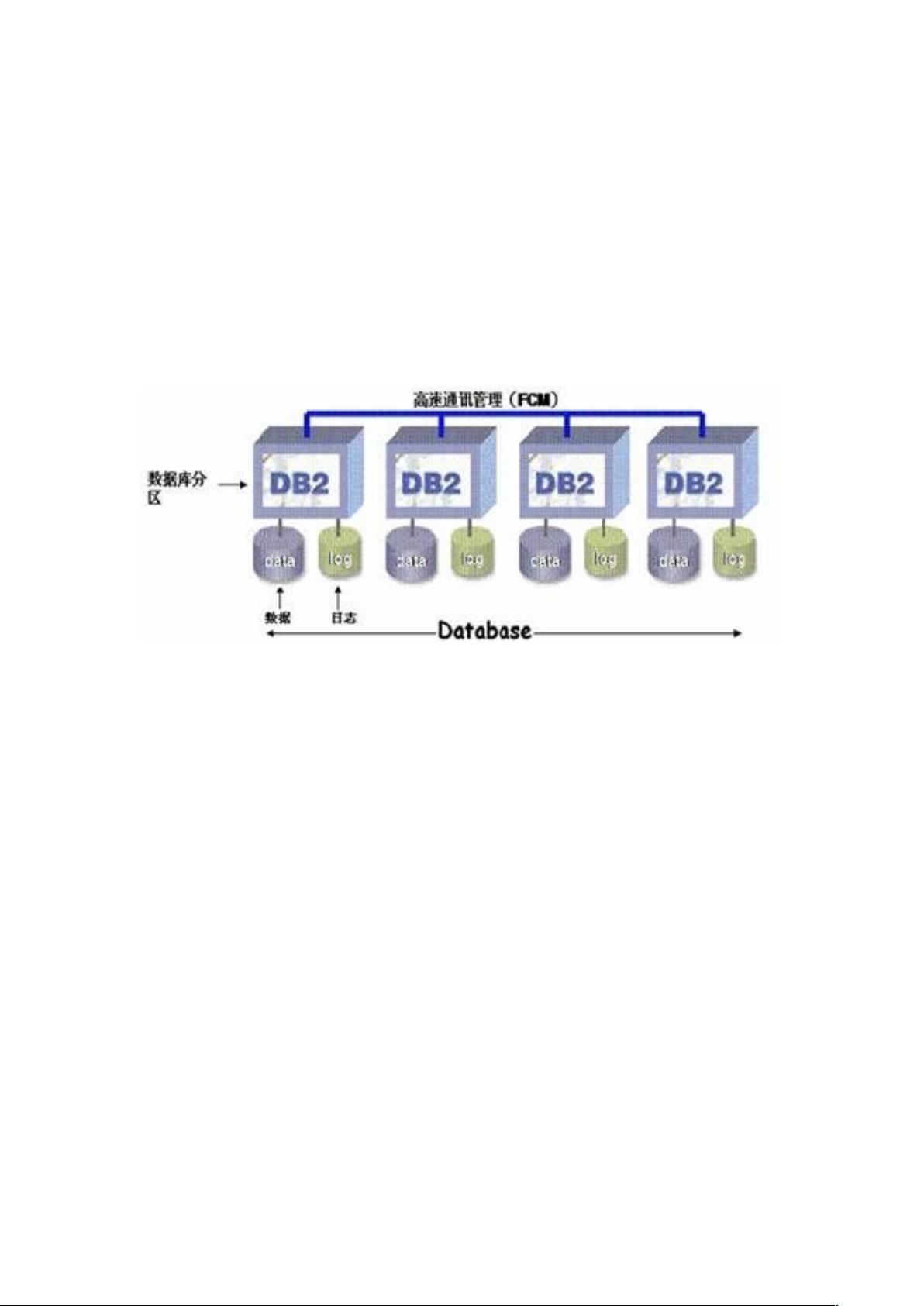
DB2 数据库分区管理
DB2 数据库分区是 DB2 企业版 DPF(Data Partitioning Feature)选件提供
的,它主要用来为大规模数据处理、高并发数据访问提供支持。DB2 数据库分
区采用 Share-nothing 体系结构,数据库在一个非共享的环境中被分解为独立
的分区,每个分区都具有自己的资源,例如内存,CPU 和磁盘以及自己的数据、
索引、配置文件和事务日志。数据库分区有时称为节点或数据库节点。如下图
所示:
图 1. DB2 数据库分区示例图
数据通过 Hash 算法均允地散列到不同的分区内,每个分区只负责处理自己的
数据。当用户发出 SQL 操作后,被连接的分区被称为 Coordinate Node,它负
责处理用户的请求,并根据 Partition key 将用户的请求分解成多个子任务交由
不同分区并行处理,最后将不同分区的执行结果经过汇总返回给用户,分区对
应用来说是透明的。
在 DB2 中,数据库分区可以部署在集群或 MPP 环境下,也就是说数据库分区
分布在不同的机器上;数据库分区也可以部署在同一台 SMP 机器上,在同一
台机器上的分区我们称为逻辑分区。同时,我们还可以在集群或 MPP 环境下
部署多个分区,在集群或 MPP 每一个节点上部署多个逻辑分区。
DB2 数据库分区提供了强大的可扩展能力。由于采用 Share-nothing 体系结构,
每个分区(节点)只处理它那一部分数据,分区之间尽可能独立,这就减少了节
点间共享资源的争用,允许数据库有效地伸缩以支持更大的数据规模及更多的
用户访问。DB2 数据库分区提供 scale up (垂直扩展)及 scale out (水平扩展)能
力。垂直扩展是通过增加机器的物理资源如 cpu、磁盘、内存来实现的;水平
扩展是通过增加物理机器来实现的,DB2 中,最多可以支持 1000 个分区。在
规划 DB2 数据库分区时,我们需要考虑是通过增加逻辑分区还是物理分区来实
现扩展能力。如果一台物理机器上有多个 CPU,其物理资源可以允许多个分区
共享该资源,我们可以通过增加逻辑分区来实现扩展;如果一台物理机器上的
物理资源不能满足应用需求,我们就需要通过增加机器,也就是物理分区来实
现扩展能力。
DB2 数据库分区还提供了强大的并行处理能力。首先,它提供了 inter-partition
parallelism 分区间的并行机制,通过 hash 算法将数据库请求分成多个任务在
1
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
175 浏览量
182 浏览量
182 浏览量
258 浏览量
258 浏览量
535 浏览量
391 浏览量

hanxy16
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- MyEclipse 7安装JBossTools插件教程
- Maemo开发平台详解:Linux手持设备的开源宝典
- 精通jQuery:从基础到高级操作指南
- LIS302DL:3轴智能数字输出加速度传感器规格书
- 武汉某公司Windows网络组建与部门职能详解
- ARM ADS集成开发环境详解:入门与调试教程
- C# Windows应用设计:异常处理与F1键帮助实现
- MySQL5.0新特性:存储过程详解
- SQL经典语句大全:创建、操作与管理
- Lotus Domino 公式详解与应用
- 互联网产品交互设计:自然语言法与实践
- ACM入门算法题集与程序设计基础
- 深入理解TCP/IP协议:结构与IP地址解析
- 基于EDA技术的交通灯控制系统设计
- Red5 to Tomcat部署教程:从WAR包入手
- MiniGUI开发全攻略:跨平台轻量级图形界面详解
