
10697
<
(
i
+1
)
<
(
i
+1
)
θ
(
i
+1
)
展开
Top-1
与LSTM基线相比,TEOR和SPICE得分大幅下降。在
选项卡中。4、我们比较了GAN [25]和我们基于POS的
方法,后者更准确。
VAE
。 Wang
等人
[32]建议使用具有加法高斯潜在空间
(AG-CVAE)的条件变分自动编码器而不是GAN来
生成不同的用他们的方法获得的多样性是由于从学习
的潜在空间中采样。他们证明了在传统的LSTM基线
的准确性的改进。由于波束搜索的计算复杂性,与从
VAE采样的字幕数量相比,他们为LSTM基线使用了
更少的波束,即它们保证了计算时间相等。与AG相比
波束搜索
我们的POS
. .
. .
. .
CVAE [32]并表明我们获得了更高的best-1标题
日
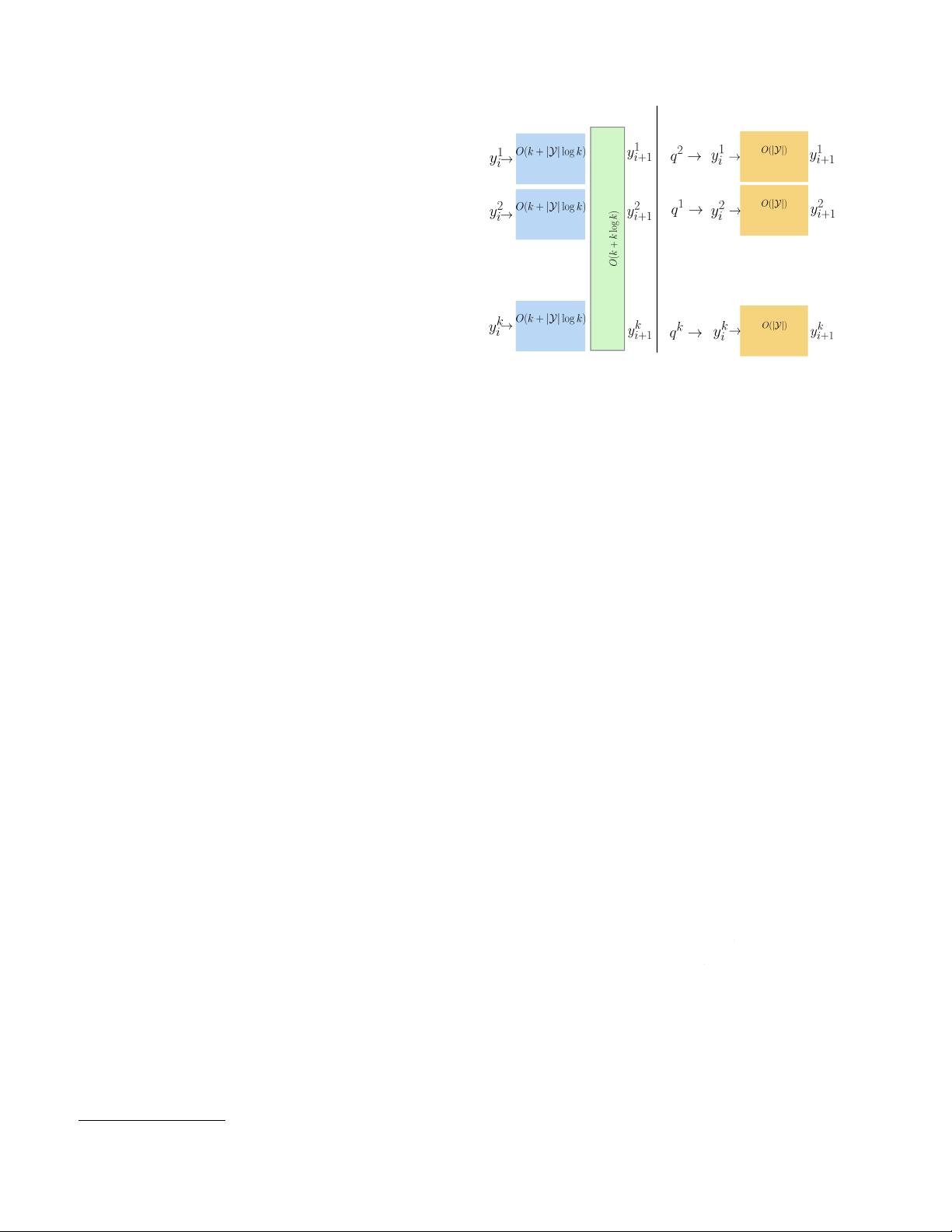
图1:波束搜索和POS采样示意图,
扩展最佳
k
个
字幕(
y1
,
y2
,
. . .
(
k
)从单词posi-
准确度(
Tab.3
)和我们最好的
-
k
字幕精度(
k
=
1
我我我
至10)优于AG-CVAE(图(3)第三章。注意,Tab中
的最佳-k得分。图3和图3表示给定相同数量的采样字
幕(20或100)的
第
k个排名字幕
i
+
1
。参见第
3
、注意事项及其他细节。
最大化训练集D上的可能性,
即
,
对于所有方法。为了公平起见,我们使用相同的排名
程序(
即
,由[7]提出并使用的共识重新排序
公
司
简介
最大
log
p
θ
(
y
|
其中
p
θ
(
y
|
I
)
=
p
(
y
i
|
y
<
i
,
I
)
。
在[32]中)对所有方法的采样字幕进行排名。
θ
(I
,
y)
∈D
i
=1
(一
)
3.
背景
问题设置和符号。不同的captioning的目标是生成k
个
序列
y1
,
y2
,
. . .
,
y
,
k
,给定图像。为了可读性,我
们去掉了上标,只关注一个序列y。我们讨论和开发的
方法将对许多这样的序列y进行采样
,
并对它们进行排
序 , 以 获 得 最 佳 的 -k-y1
,
y2
,
. . .
,
y
k
. 单 个 帽 y
=
(
y1
,
. . .
,
y
N
)由一系列的字y
i
组成
,
i
∈ {1
,
. . .
,
N
}
,其精确地描述给定图像
I
。对于每
个字幕
y
,单词
y
i
,
i
∈ {1
,
. . .
,
N
}
是从固定词汇表
Y
中获 得 的 ,
即
,
y
i
∈ Y 。此 外 , 我 们 假设 词 性
(
POS
)的可用性
句子y的标记。 更具体地,POS标签器提供标签序列t
=
(
t
1
,
. . .
,
t
N
),其中
t
i
∈ T
是词y i的POS标记。 集
合
T包含12个通用的POS标签
(
NOUN
)、代词(
PRON
)等
。
1
为了训练我们的模型,我们使用数据集D
=
{(
I
,
y
,
t
)},它包含由图像
I
、句子
y
和对应的
POS
标签
序列
t
组成的元组(
I
,
y
,
t
)。
因为它是不可行的,以注释的
。
5M字幕
联合概率分布的因式分解强制执行单词的时间排序。
因此,在
第
i个时间步(或词位置)处的词y
i
仅取决于所
有相邻词y
<i
。该概率模型使用具有时间(或掩蔽)卷
积的递归神经网络或前馈网络来表示。特别是后者,
即
,时间卷积(temporalconvolution)最近已经被用于
不同视觉和语言任务,以代替经典的递归神经网络,
例如
,[3、9、4]。
在训练过程中,我们学习最佳参数
θ
θ
。然后,对于
测试图像I,条件逐词后验
概率
p
θ
∈
(
y
i
|
y
<
i
,
I
)
依次
从
i
=
1到
N
。考虑到这些后验,波束搜索是适用的
-
这是我们的底线。图图1示出了波束搜索
其中从字位置
yi
到
yi
+1
的波束宽度为
k
。这里,波束搜索
维护按可能性排序的最佳
k
(不完整)字幕。它扩展了
最好的-
k
标题在每 一个词grecery从开始到 结 束的句
子。
更具体地,对于从词位置
i
的波束搜索
,
我们
首先
生成后 验
p
j
∈
(
yi
+1
|
y
J
,
I
)
基于
包含
yj
,
j
∈
{1
,
. . .
,
k
}。然后,我们通过扩展
MSCOCO与POS标签,我们使用自动的一部分-
k
个条目
y
j
在列表中使用计算后验
演讲者
1
p
j
(
y
i
+1
|
y
J
,
I
)。我们称之为的时间
θ
(
i
+1
)
经典图像字 幕。 经典技术将 联合概率模型p
θ
(y|
(
1)把所有的词转化为条件句的乘积。他们通过以下
方式学习模型参数θθ
单个扩展top-k操作复杂度是相同的
从一个大小为的数组中获取排序后的前
k
个
值,
|.|
.
2
所有扩展top-
k
操作的时间复杂度为
O
(
k
~ 2
+
|Y|
k
log
k
)。
1
有关POS标签和自动POS标签器的详细信息,请参阅
https://www.nltk.org/book/ch05.html
.
.
.
.
.
.
展开
Top-k
展开
Top-k
展开
Top-k
展开
Top-1
展开
Top-1
将
kxk
大小的数组合并到新的
top-k
剩余14页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


