基于双重定向胶囊网络的低分辨率人脸识别方法
下载需积分: 0 | DOCX格式 | 1.88MB |
更新于2024-08-04
| 47 浏览量 | 举报
低分辨率人脸识别胶囊网络
低分辨率人脸识别胶囊网络是一种新颖的深度学习模型,旨在解决低分辨率(VLR)图像识别问题。该模型基于胶囊网络架构,结合卷积层和胶囊层,以学习有效的VLR识别模型。
低分辨率图像识别是计算机视觉领域中的一个挑战性问题。由于图像捕获的距离较大,目标区域的分辨率非常低,通常小于16×16。这种问题在监视场景中非常常见,例如在监控摄像机中捕获的人脸识别。
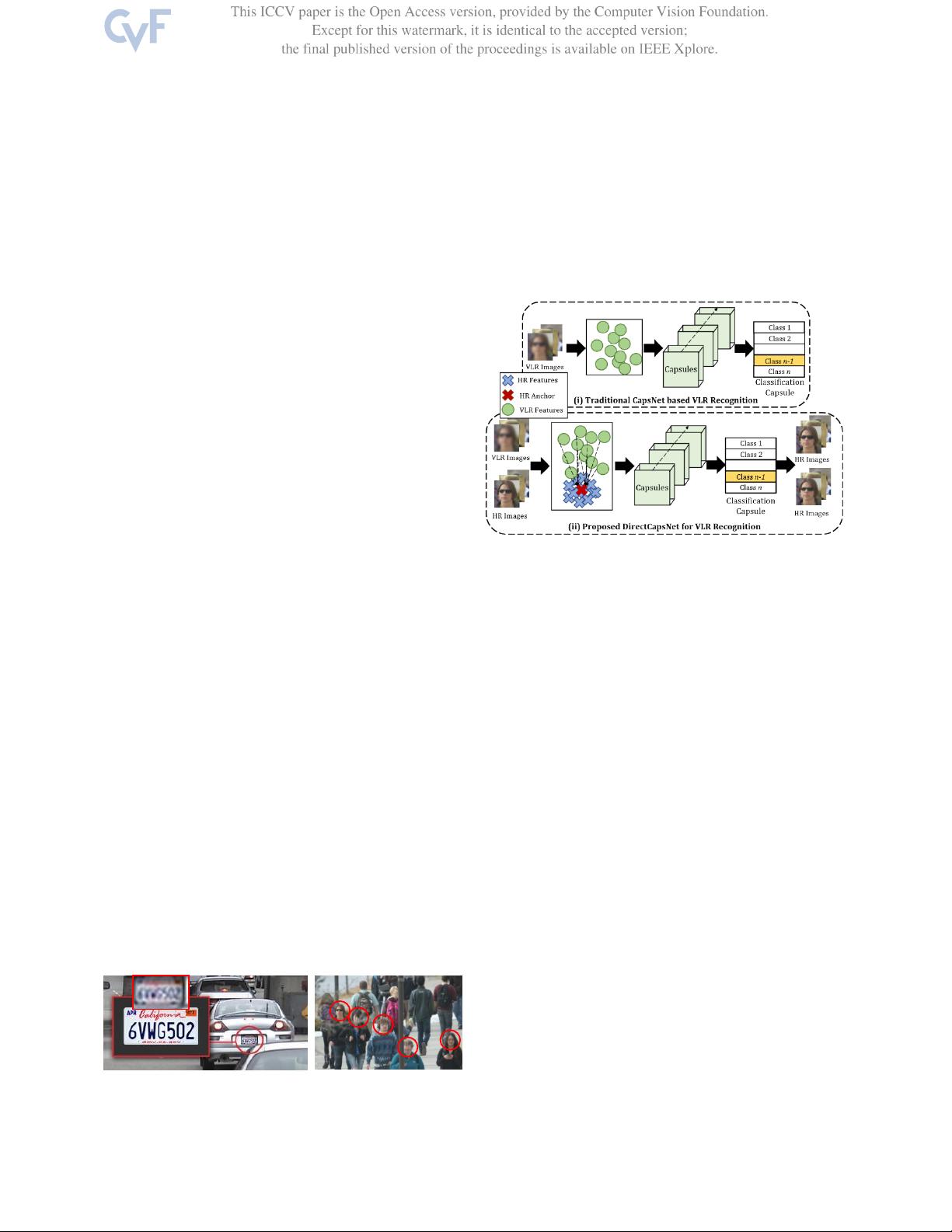
低分辨率图像识别的挑战在于信息内容有限和模糊不清。图像中的噪声和不确定性使得识别变得非常困难。为了解决这些挑战,研究人员提出了双重定向胶囊网络模型,称为DirectCapsNet。
DirectCapsNet模型结合了胶囊层和卷积层,以学习有效的VLR识别模型。该模型还引入了两个新颖的损失函数:建议的HR锚损失和建议的目标重建损失,以克服VLR图像中信息量有限的挑战。
HR锚损失函数用于指导模型学习高分辨率图像中的区别性特征,而目标重建损失函数用于重建目标图像。这些损失函数在训练过程中使用高分辨率图像作为辅助数据,以“直接”进行区别性特征学习。
实验结果表明,DirectCapsNet模型在VLR数字分类和VLR人脸识别方面取得了最先进的结果。例如,在UCCS人脸数据库中,当16×16图像与80×80图像匹配时,DirectCapsNet模型取得了最好的结果。
低分辨率人脸识别胶囊网络是一种有效的解决方案,旨在解决低分辨率图像识别问题。该模型基于胶囊网络架构,结合卷积层和胶囊层,以学习有效的VLR识别模型。该模型还引入了两个新颖的损失函数,以克服VLR图像中信息量有限的挑战。
在实际应用中,低分辨率人脸识别胶囊网络可以应用于监控场景、图像标记、人脸识别等领域。该模型可以帮助提高图像识别的准确性,特别是在低分辨率图像中。
低分辨率人脸识别胶囊网络是一种新颖的深度学习模型,旨在解决低分辨率图像识别问题。该模型基于胶囊网络架构,结合卷积层和胶囊层,以学习有效的VLR识别模型。该模型还引入了两个新颖的损失函数,以克服VLR图像中信息量有限的挑战。
双定向胶囊网络可实现非常低分辨率的图像识别
Maneet Singh,Shruti Nagpal,Richa Singh 和 Mayank Vatsa IIIT-德
里,印度
{ 鬃毛,兽皮,rsingh,玛雅克} @ iiitd.ac.in
抽象
低 分 辨 率 (
VLR
) 图 像 识 别 对 应 于 对 分 辨 率 为
16×16 的
图像进行分类或更少。尽管当以很大的对距
距离(例如,监视场景)或从广角移动摄像机捕获对
象时,它具有广泛的适用性,但受到的关注有限。这
项研究提出了一种新颖的双重定向胶囊网络模型,称
为
DirectCapsNet
,用于解决
VLR
数字和面部识别问题。
所提出的体系结构利用胶囊和卷积层的组合来学习有
效的
VLR
识别模型。该体系结构还合并了两个新颖的
损失函数:(
i
)建议的
HR
锚损失和(
ii
)建议的目标
重建损失,以克服
VLR
图像中信息量有限的挑战。拟
议的损失在训练过程中使用高分辨率图像作为辅助数
据,以
“
直接
”
进行区别性特征学习。针对
VLR
数字分
类和
VLR
人脸识别进行了多次实验,并与最新算法进
行了比较。拟议的
DirectCapsNet
始终展示最先进的结
果;例如,在
UCCS
人脸数据库中,当
16×16
图像与
80×80
图像匹配。
1. 简介
在典型的监视场景中,通常会在较大的距离内捕获
图像,从而使目标区域具有非常低的分辨率(VLR),
通常小于 16×16 [ 33 ]。图 1 (a)显示了 VLR 识别的
实际示例应用,其中感兴趣的区域可以是人脸,可疑
物体或移动车辆的车牌号。这些样本证明了问题的艰
巨性,其中 VLR 识别的一些关键挑战是信息内容有限
和模糊不清。VLR 识别在图像标记中也具有适用性,
在该图像标记中,在框架中捕获了多个对象/人物,并
且这些实体中的每个实体的分辨率都很小。
(a) VLR 识别的实际应用。图片来源:(i)互联网,(ii)
UCCS 数据集[ 24 ]
(b) 建议的双重定向胶囊网络(DirectCapsNet)
图 1:拟议的 DirectCapsNet 利用 HR 样本,通过拟议的
HRanchor损失和目标重建损失,
指导
对 VLR图像识别
更有意义和更具区别性的特征的学习。
Netzer
等。
[ 17 ]证明了人类在识别在真实环境中捕
获 的 VLR 数 字 时 表 现 不 佳 。 对 于 街 景 房 门 号 码
(SVHN)数据集,作者观察到人类对 101-125 像素高
度的样本的准确性为百分之几。另一方面,性能下降
到 82
。
当对分辨率非常低的样本(即高度不超过 25像
素的图像)进行分类时为 0%±2%,从而恢复了问题
的挑战性。直接上采样经由内插可以被看作是用于识
别 VLR 一个可能的解决方案,但是,多个研究已经证
实由于需要大的放大系数[性能差 14 ,25]和
1 340
噪声的可能引入,也可以在图 1 (a)(i)中观察到。此
外,在文献中,研究人员还证明了在高分辨率(HR)图
像(包含高信息含量)上训练的模型无法在(V)LR图像
上表现良好[ 25 ]。当前稀缺的解决方案以及 VLR 识别的
广泛应用使其成为一个重要问题,需要引起人们的关注。
这项研究提出了一种新颖的基于胶囊网络的 VLR 图像
识别模型。Hinton
等。
[ 7 ]提出了学习“胶囊”,它表示实
例化参数的向量,以便更有效地编码输入。实例化参数可
(
i) Digit Classification
(
ii) Face Recognition
下载后可阅读完整内容,剩余8页未读,立即下载
相关推荐



陌陌的日记
- 粉丝: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
