
百度分布式交互查询平台百度分布式交互查询平台PINGO架构迭代架构迭代
PINGO是一个由百度大数据部与百度美国研发中心合作而成的分布式交换查询平台。在PINGO之前,百度的大数据查
询作业主要由基于Hive的百度QueryEngine去完成。QueryEngine很好的支持着百度的离线计算任务,可是它对交互式
的在线计算任务支持并不好。为了更好的支持交互式任务,我们在大约一年前设计了基于SparkSQL与Tachyon的
PINGO的雏形。在过去一年中, 通过跟不同业务的结合,PINGO逐渐的演变成一套成熟高效的交互式查询系统。本文
将详细介绍PINGO的架构迭代过程以及性能评估。
PINGO设计目标
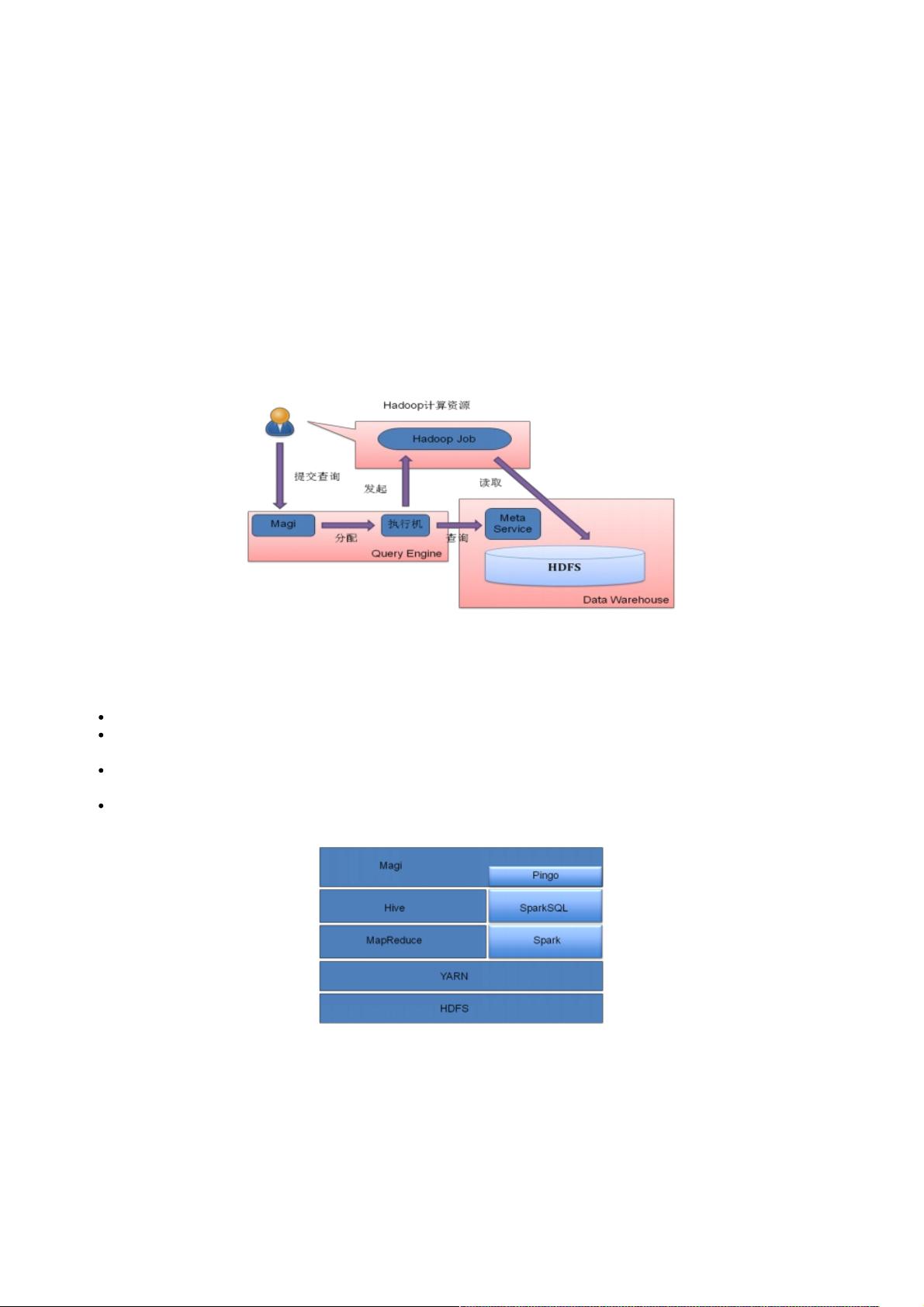
QueryEngine是基于Hive的百度内部的大数据查询平台,这套系统在过去几年中较好的支撑了百度的相关业务。 图1展
示了QueryEngine的架构图,其服务入口叫做Magi。用户向Magi提交查询请求, Magi为这次请求分配一个执行机, 执行
机会调用Hive读取Meta信息并向Hadoop队列提交任务. 在这一过程中, 用户需要自行提供计算需要的队列资源。随着近
几年对大数据平台的要求越来越高, 我们在使用QueryEngine过程中也发现了一些问题:首先QueryEngine需要由用
户提供计算资源, 这使得数据仓库的用户需要去了解Hadoop以及相关的管理流程, 这增加了用户使用数据的门槛。 第
二, 对于很多小型计算任务而言, MR的任务的起动时间也较长, 往往用户的计算任务只需要1分钟, 但是排队/提交任务就
需要超过一分钟甚至更长的时间。这样的结果是,QueryEngine虽然很好的支持线下执行时间长的任务,但是对线上
的一些交换式查询任务(要求延时在一到两分钟内)确是无能为力。
图1: Query Engine 的执行流程
为了解决这些问题, 在大约一年前,我们尝试在离线计算的技术栈上搭建起一套具有在线服务属性的SQL计算服务
PINGO。如图2所示: PINGO使用了SparkSQL为主要的执行引擎, 主要是因为Spark具有下面的特点:
内存计算:Spark以RDD形式把许多数据存放在内存中,尽量减少落盘,从而提升了计算性能。
可常驻服务:Spark可以帮助实现常驻式的计算服务, 而传统的Hadoop做不到这一点。常驻式的计算服务有助于
降低数据查询服务的响应延迟。
机器学习支持:对于数据仓库的使用, 不应仅仅局限于SQL类的统计任务。 Spark的机器学习库可以帮助我们将
来扩展数据仓库, 提供的交互式的数据挖掘功能。
计算功能多元:虽然PINGO是一个查询服务, 不过仍然有其他类型的计算需求, 如数据预处理等。 使用Spark可以
使我们用一个计算引擎完成所有的任务, 简化系统的设计。
图2: PINGO初版系统架构设计
PINGO系统迭代
在过去一年中,PINGO从一个雏形开始,通过跟不同业务的结合,逐渐的演变成一套成熟高效的系统。中间经历过几
次的架构演变,在本章中,我们将详细介绍PINGO的迭代过程。
PINGO 1.0
PINGO初版的目标是提升性能,让其能支持交互式查询的任务。由于Spark是基于内存的计算引擎,相对于Hive有一
定的性能优势, 所以第一步我们选择使用Spark SQL。为求简单,最初的服务是搭建在Spark Standalone集群上的。
我们知道, Spark在Standalone模式下是不支持资源伸缩的, 一个Spark Application在启动的时候会根据配置获取计算资
源。 这时就算一个查询请求只有一个Task还在运行, 该Application所占用的所有资源都不能释放。好在一个Spark
下载后可阅读完整内容,剩余4页未读,立即下载

weixin_38718413
- 粉丝: 9
- 资源: 946
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


