OpenCL编程指南:CUDA架构与性能优化
需积分: 10 162 浏览量
更新于2024-07-26
收藏 1.49MB PDF 举报
"OpenCL Programming Guide (NVIDIA)" 是一本针对使用OpenCL在NVIDIA CUDA架构上进行编程的指南,涵盖了从基础概念到性能优化的各种主题。本书旨在帮助开发者理解和利用OpenCL这一开放标准,实现CPU与GPU之间的数据通信,并有效地利用不同类型的内存以达到最小的消耗。
OpenCL,全称为Open Computing Language,是一种跨平台的并行计算框架,主要用于硬件加速计算,特别是在图形处理单元(GPU)上执行通用计算任务。CUDA(Compute Unified Device Architecture)是NVIDIA为GPU开发的一种编程模型,使得开发者能够利用GPU的强大计算能力执行非图形相关的计算任务。
在介绍CUDA架构时,书中的章节讲述了以下几点:
1. SIMT(Single Instruction Multiple Thread)架构是CUDA的基础,它允许单个GPU核心执行多个线程,这些线程在同一指令下并行操作,提高了计算效率。
2. 硬件多线程特性使得GPU能在单个流处理器(Streaming Multiprocessor, SM)上并发运行多个线程块,进一步提升并行度。
3. PTX(Parallel Thread Execution)是CUDA的中间代码表示,它是编译CUDA程序时的一个阶段,用于生成可被执行的GPU指令。
4. Volatile关键字用于标记变量,表明其状态可能在GPU的不同线程之间发生变化,需要特殊处理。
5. 计算能力(Compute Capability)是NVIDIA GPU的一个指标,它定义了设备能支持的特性级别和性能。
书中还提到了性能指导原则,如:
1. 整体性能优化策略,这涉及到从应用程序设计层面到硬件资源使用的全局考虑。
2. 提高利用率是优化的关键,包括应用层面、设备层面和多处理器层面的优化,确保GPU资源得到充分使用。
3. 提升内存带宽是性能优化的另一个重要方面,涉及如何高效地传输数据以及访问不同类型的设备内存:
- 主机与设备间的数据传输需要精心设计以减少延迟和提高吞吐量。
- 全局内存是所有线程可访问的存储,但访问速度较慢,优化时要考虑减少全局内存访问。
- 局部内存(Local Memory)是线程块内部共享的存储,对于局部数据的快速交换非常有用。
- 共享内存(Shared Memory)在同一个SM上的线程之间快速共享,可显著提升数据交换速度。
- 常量内存(Constant Memory)提供了一种高速且只读的存储方式,适合存储不会改变的常量数据。
通过深入理解OpenCL和CUDA的编程模型,开发者可以编写出高效利用GPU计算能力的程序,实现高性能计算任务,例如矩阵乘法这样的并行计算示例,书中的实例将帮助读者更好地掌握这些技术。

Chapter 2.
OpenCL on the CUDA Architecture
2.1 CUDA Architecture
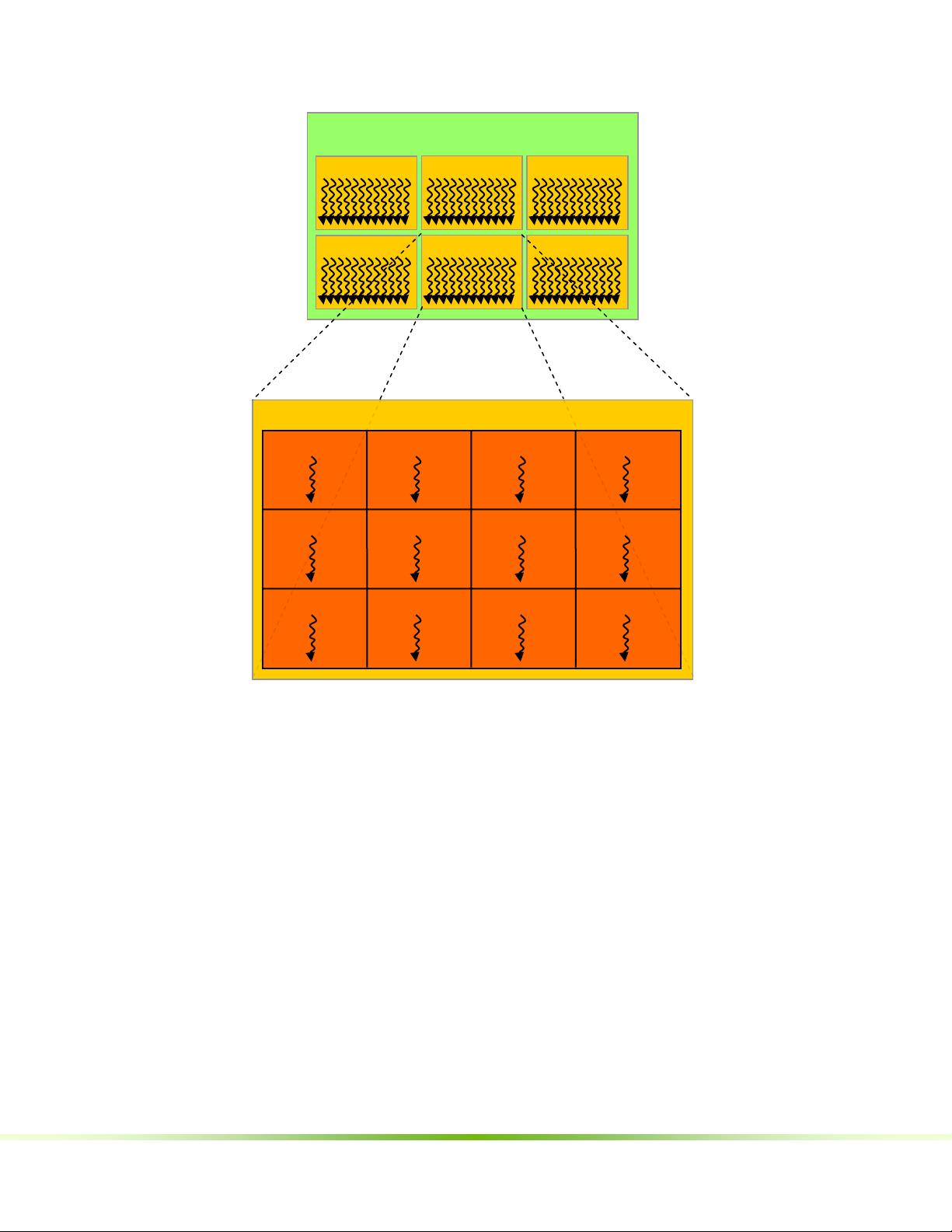
The CUDA architecture is a close match to the OpenCL architecture.
A CUDA device is built around a scalable array of multithreaded Streaming
Multiprocessors (SMs). A multiprocessor corresponds to an OpenCL compute unit.
A multiprocessor executes a CUDA thread for each OpenCL work-item and a thread
block for each OpenCL work-group. A kernel is executed over an OpenCL
NDRange by a grid of thread blocks. As illustrated in Figure 2-1, each of the thread
blocks that execute a kernel is therefore uniquely identified by its work-group ID,
and each thread by its global ID or by a combination of its local ID and work-group
ID.

剩余60页未读,继续阅读
1123 浏览量
129 浏览量
132 浏览量
2010-05-13 上传
235 浏览量
2018-02-06 上传
163 浏览量

dandan1991
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







