芯片集成系统建模与快速模拟:博士论文概要
178 浏览量
更新于2024-06-18
收藏 12.62MB PDF 举报
"这篇博士学位论文由Richard Buchmann撰写,主题为‘芯片集成系统的循环级别建模与快速模拟’,属于计算机科学领域,特别是在硅片集成系统的研究方面。论文于2006年在巴黎第六大学完成,并在2009年10月23日提交至开放获取存档HAL。该研究探讨了如何对芯片上的集成系统进行建模和快速模拟,以支持架构探索。论文中提到,随着硬件架构的复杂性和软件部署选项的增多,评估各种设计指标(如硅面积、能量消耗和性能)的模拟过程变得极为耗时。因此,快速模拟技术成为了优化设计流程的关键,尤其是在循环级别的模拟,这对于理解和预测系统行为至关重要。
Richard Buchmann在论文中提出的方法旨在加速这一过程,以帮助设计师更有效地探索不同的架构配置。评审委员会包括多位知名专家,他们对论文进行了评审和指导。论文的摘要指出,建模工作涵盖了软件应用程序的规范以及硬件架构的建模,目标是找到最佳的部署策略。快速模拟技术的应用能够显著减少评估时间,这对于在设计早期阶段做出关键决策非常有益,同时还能确保系统在性能和能效方面的最优表现。
这篇博士论文对学术界和工业界都有重要的意义,因为它提供了对芯片集成系统设计中关键问题的深入理解,同时也提出了提高设计效率的新方法。通过HAL平台,这篇论文可供全球的研究人员和工程师查阅,促进了知识的共享和进一步研究。"
0
1.3.架构模拟7
0
选择抽象级别进行架构探索
0
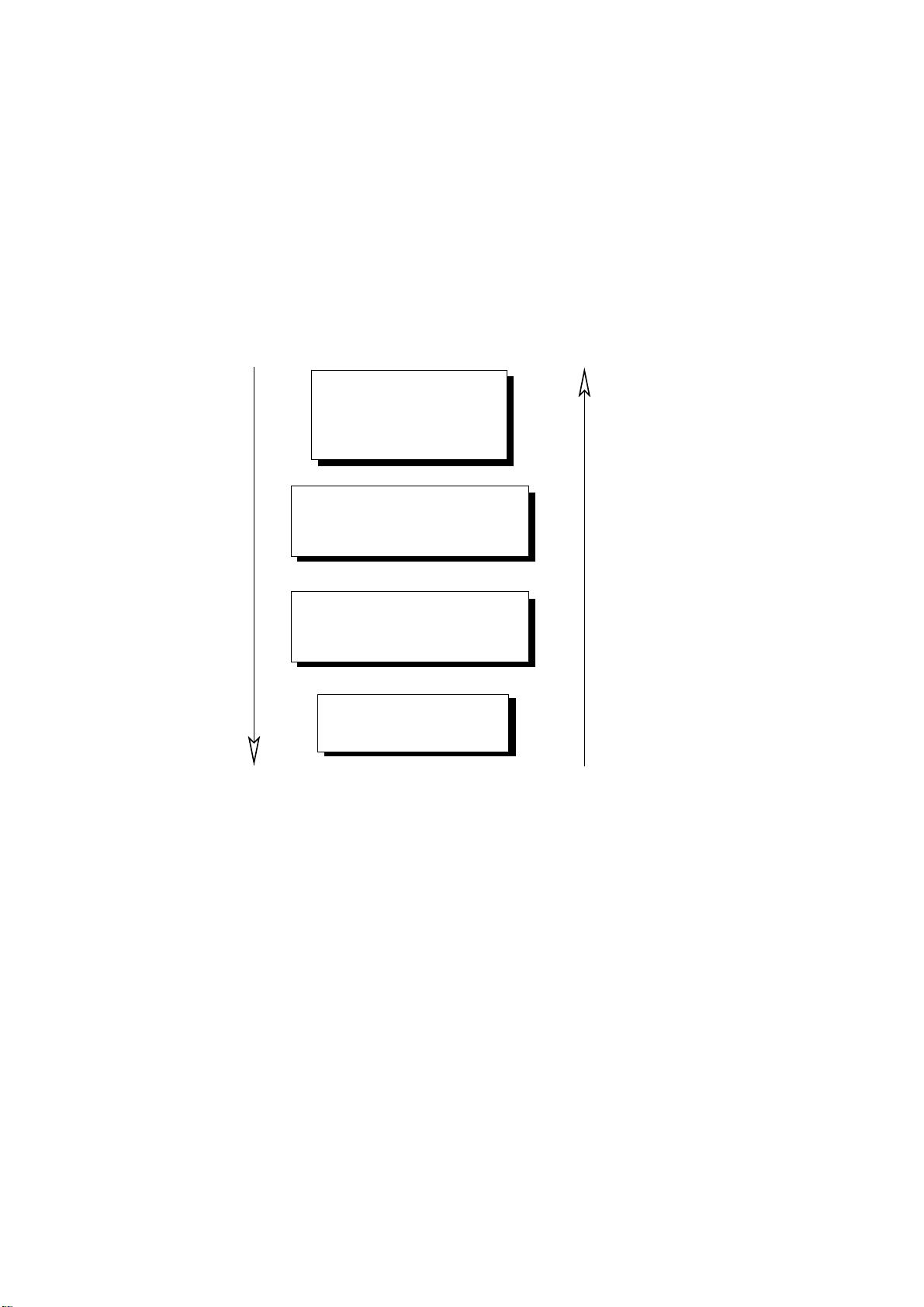
模拟速度和评估精度取决于硬件架构模型的抽象级别。图1.4总结了抽象级别对模拟速度和模型
精度的折衷。
0
模型精度模拟速度
0
CABA级别(
或CC)
0
可综合RTL级
别
0
事务时间级别(TLM
−T)
0
门级别
0
图1.4-抽象级别与性能/精度的折衷
0
TLM-T级别不能保证系统性能的精确评估。事务发生的日期可能会有几个周期的误差。
0
其他三个建模级别-门、可综合RTL和CABA-
可以精确评估集成系统的能耗和系统的时间性能。CABA级别比其他两个级别更快。
0
在本论文中,我们关注CABA抽象级别,因为这个级别在架构探索中提供了一个很好的折衷方案
。
0
我们已经看到执行速度取决于抽象级别和模拟引擎。



剩余149页未读,继续阅读
1132 浏览量
636 浏览量
6952 浏览量
902 浏览量
1775 浏览量
1930 浏览量
2613 浏览量
2247 浏览量
1429 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
