Apache Beam架构详解:批流处理统一模型与实战应用
版权申诉
77 浏览量
更新于2024-07-05
收藏 8.9MB PDF 举报
Apache Beam是一种开源的统一数据处理框架,由Google提出并维护,旨在提供一种模块化的、可扩展的方式来构建批处理和实时流处理应用程序。这份56页的文档深入探讨了Apache Beam的架构原理以及其实践应用。
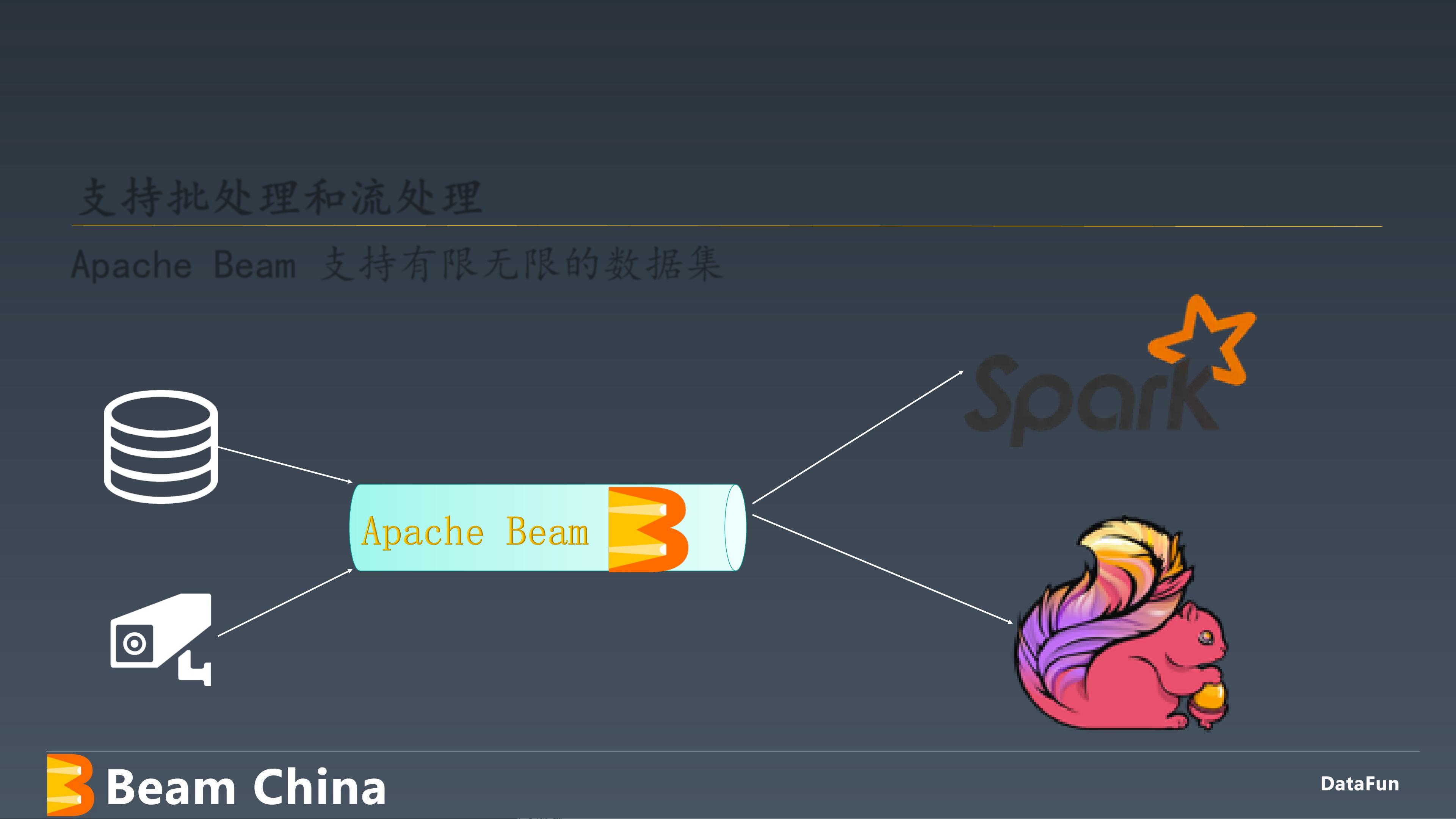
首先,作者张海涛,作为海康威视金融事业部架构师和Apache Beam中文社区发起人,分享了自己在金融领域的大数据分析与AI基础架构构建经验,包括云基础平台的搭建和自研组件的研发。他指出,Apache Beam的核心价值在于它的统一性,它提供了一种通用的编程模型,使得开发者能够轻松地处理来自不同数据源(如各种数据库和消息队列)的数据,无论是批处理还是实时流数据,都能通过相同的API进行处理。
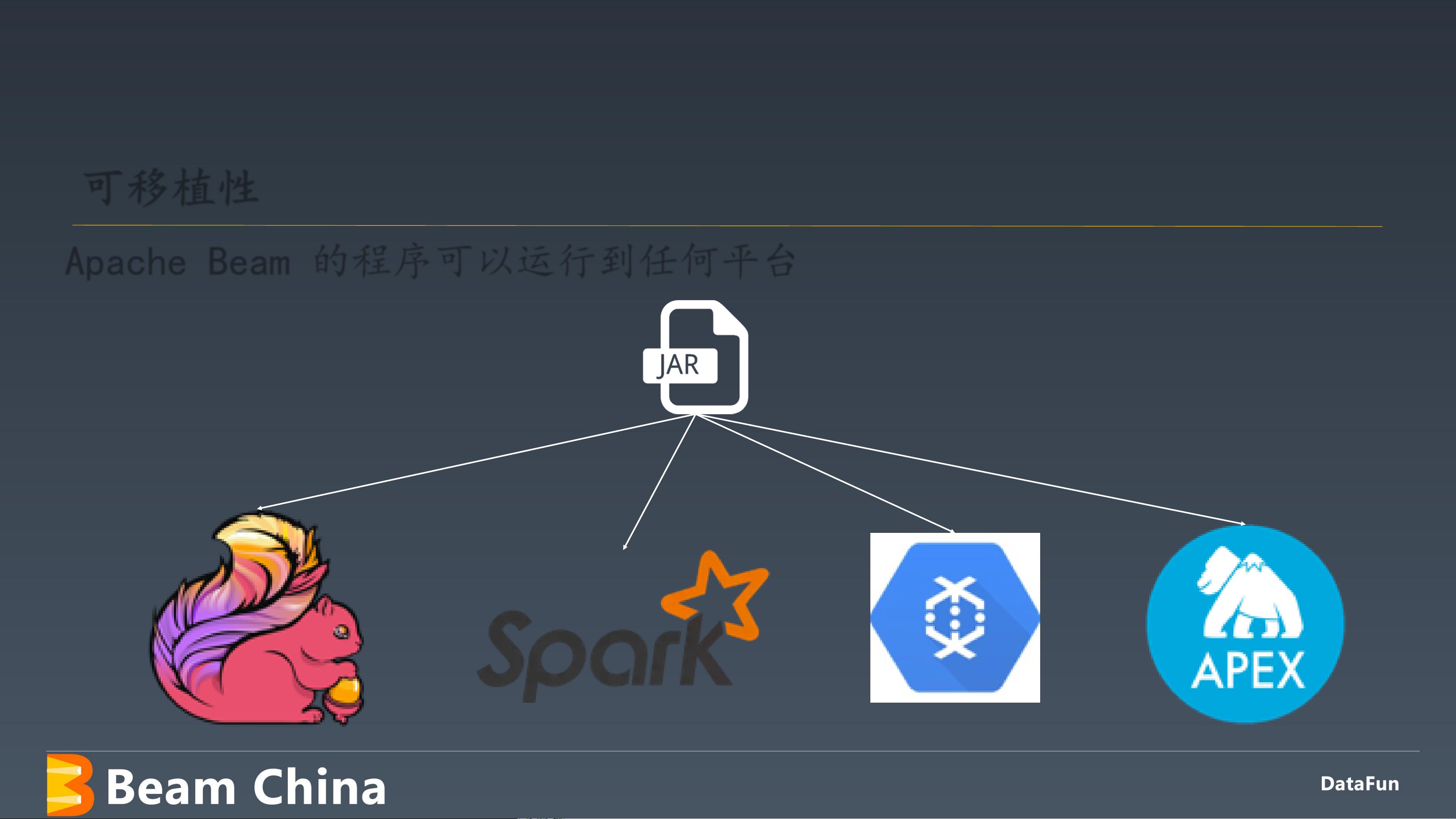
文档详细介绍了Apache Beam的架构设计,它基于数据处理管道的概念,用户编写定义数据处理流程的代码,然后这些代码由背后的支持后端(如Apache Apex、Apache Flink、Apache Spark或Google Cloud Dataflow)分布式执行。这种设计允许用户在不关心具体执行引擎的情况下,实现跨平台的可移植性和灵活性。
在核心组件解析部分,文档讨论了如何利用Apache Beam构建高吞吐量实时数据处理的应用,以及如何将其应用到AI微服务中,可能涉及到数据存储的选择,如GoogleFS,以及与其他技术(如Go、Scala等编程语言和Apache Samza、Apache Gearpump等实时处理框架)的对比。
此外,文档强调了Apache Beam的可扩展性,由于其模块化设计,用户可以根据需求选择和替换不同的组件,以适应不断变化的业务和技术环境。这种灵活性使得Apache Beam成为一个强大的工具,适用于不断发展的大数据场景和AI服务的构建。
总结来说,这份文档不仅介绍了Apache Beam的基本概念和优势,还深入剖析了其在实际项目中的应用策略,对想要理解和使用Apache Beam进行数据处理的开发者来说,是一份极具价值的参考资料。
2022-03-18 上传
1883 浏览量
2023-03-21 上传
2022-11-09 上传
2023-08-26 上传
2022-03-18 上传
点击了解资源详情
222 浏览量
2025-01-10 上传

行业报告
- 粉丝: 4
- 资源: 6143
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fall2019-group-20:GitHub Classroom创建的Fall2019-group-20
- cv-exercise:用于学习Web开发的仓库
- 雷赛 3ND583三相步进驱动器使用说明书.zip
- Rocket-Shoes-Context
- tsmc.13工艺 standardcell库pdk
- 回归应用
- 汇川—H2U系列PLC模拟量扩展卡用户手册.zip
- mysql-5.6.4-m7-winx64.zip
- PortfolioV2.0:作品集网站v2.0
- 线性代数(第二版)课件.zip
- 直线阵采用切比学夫加权控制主旁瓣搭建OFDM通信系统的框架的实验-综合文档
- quicktables:字典的超快速列表到Python 23的预格式化表转换库
- 彩色无纸记录仪|杭州无纸记录仪.zip
- DiagramDSL:方便的DSL构建图
- api.vue-spotify
- LLDebugTool:LLDebugTool是面向开发人员和测试人员的调试工具,可以帮助您在非xcode情况下分析和处理数据。
