CentOS6.3环境下Hadoop 2.2.0详编译安装教程
需积分: 10 14 浏览量
更新于2024-09-10
收藏 661KB PDF 举报
"Hadoop 2.2编译安装详解"
Hadoop是一款开源的分布式计算框架,由Apache基金会开发,主要用于处理和存储大规模数据。本文将详细介绍如何在Linux环境下编译安装Hadoop 2.2.0版本。安装过程通常涉及多个步骤,包括环境配置、系统设置、用户创建、网络配置以及SSH互信。
首先,你需要准备一个基于Linux的操作系统,例如文中提到的CentOS 6.3 64位。在开始之前,确保所有参与集群的节点(如Master、Slave1和Slave2)都有固定的IP地址,并且已经正确配置。这可以通过编辑`/etc/sysconfig/network-scripts/ifcfg-eth0`文件来实现。
接下来,为了进行集群操作,需要统一修改所有节点的主机名。这可以通过编辑`/etc/sysconfig/network`文件完成。修改完成后,重启服务器使设置生效。
安装Hadoop通常需要创建一个新的用户,例如名为"hadoop"的用户,这可以通过`useradd hadoop`命令完成。创建用户后,还需在所有节点上设置`/etc/hosts`文件,添加各节点的IP地址和主机名映射,以实现内部网络的名称解析。
在多节点环境中,SSH无密码登录是必要的,以便Hadoop进程能够在不同节点间通信。为此,你需要在每个节点的"hadoop"用户下执行`ssh-keygen -t rsa`生成SSH密钥对,然后通过`ssh-copy-id`将公钥复制到其他节点,建立相互信任。
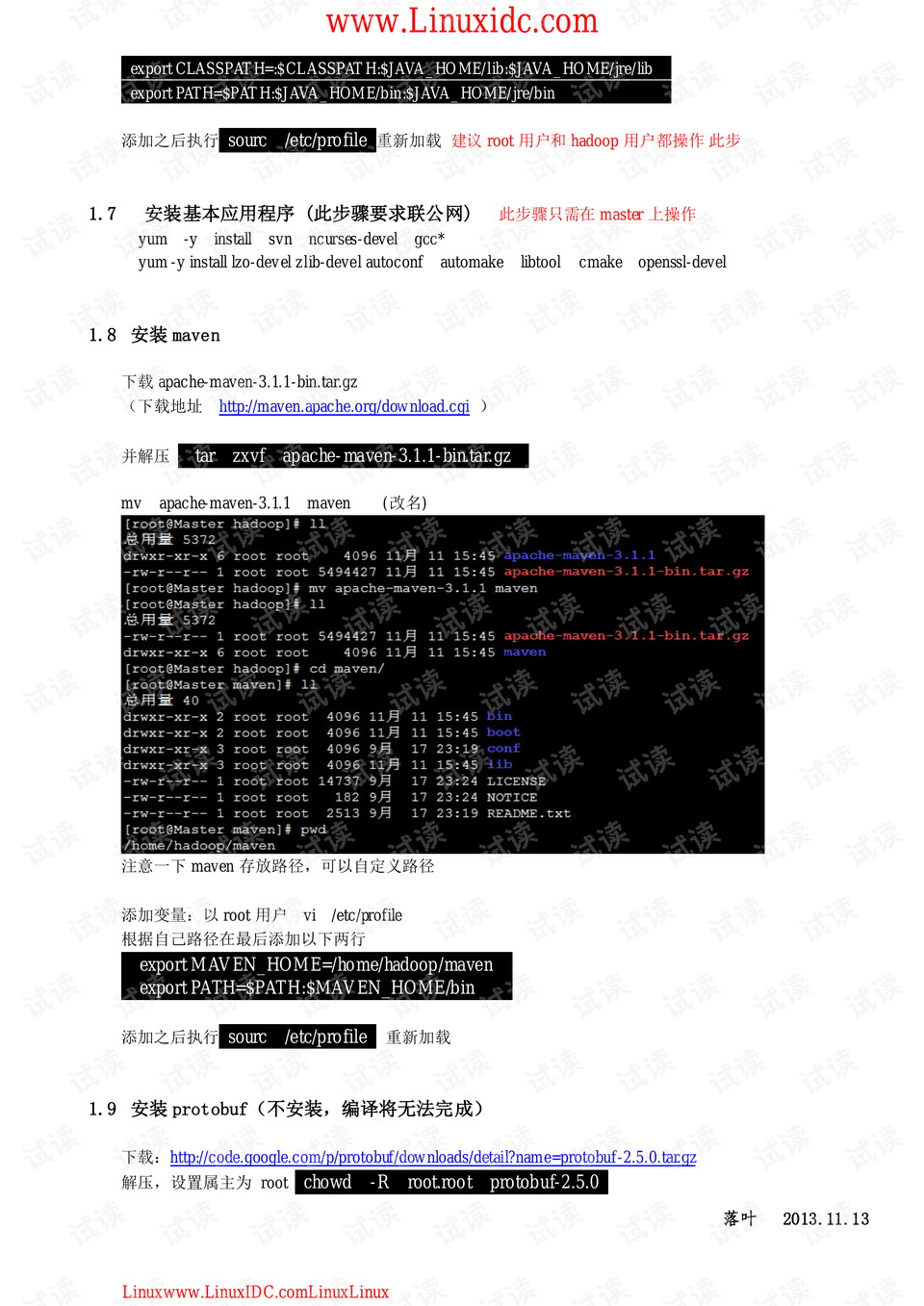
完成这些基础设置后,下载Hadoop的源码包,如`Hadoop-2.2.0-src.tar.gz`,解压并进入源码目录。编译Hadoop通常包含以下步骤:
1. 配置环境:确保系统已安装必要的依赖库,如Java开发工具(JDK)并设置`JAVA_HOME`环境变量。
2. 配置Hadoop:通过`./configure`命令自定义Hadoop的配置,例如指定安装路径、设置HDFS和YARN的相关参数。
3. 编译和构建:运行`make`或`make -j <num_cores>`(其中`<num_cores>`是你系统的CPU核心数)来编译源代码。
4. 安装:使用`sudo make install`将编译好的Hadoop二进制文件安装到指定目录。
5. 配置Hadoop集群:编辑`conf/hadoop-env.sh`、`conf/core-site.xml`、`conf/hdfs-site.xml`、`conf/mapred-site.xml`和`conf/yarn-site.xml`等配置文件,设置Hadoop集群的相关参数。
6. 初始化HDFS:使用`hdfs namenode -format`命令格式化NameNode。
7. 启动Hadoop服务:通过执行`start-dfs.sh`和`start-yarn.sh`启动Hadoop的各个组件。
最后,你可以通过Hadoop提供的命令行工具或Web界面来验证安装是否成功,例如运行`hadoop fs -ls /`检查HDFS的根目录,或者访问NameNode和ResourceManager的Web UI。
安装Hadoop是一个涉及多步骤的过程,需要对Linux系统和Hadoop的架构有基本理解。通过正确的配置和操作,你将能够搭建起一个功能完备的Hadoop分布式集群,为大数据处理提供强大的支持。
剩余13页未读,继续阅读
2015-03-19 上传
2014-08-13 上传
点击了解资源详情
点击了解资源详情
235 浏览量
156 浏览量
2013-01-13 上传
2016-05-07 上传
165 浏览量

qq_33642252
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- JAD工具:Java反编译神器的实用教程
- Delphi多线程控件BmdThread_1.9的安装与测试指南
- Flash猜拳游戏源码分享 - 剪刀石头布
- Java编程课程中辐射监测任务1解析
- 深入探究ASP.NET同学录系统设计与实践
- Windows Server 2003双机热备技术实施教程
- 掌握kindeditor使用技巧,实例操作解析
- mimos:打造hapi生态系统的Mime数据库界面
- JqGrid在VS2010和MVC下的应用示例
- C#实现USB HID设备通信的方法及实例
- YangDiDi-bilibili.github.io网站CSS技术解析
- Eclipse贪吃蛇游戏插件简易安装指南
- MATLAB实现:非线性方程组的无导数解算器开发
- 揭秘:超级玛丽游戏源码的神秘面纱
- Scribd文档去划线解决方案及开发指南
- 单片机红外线控制数码管显示与蜂鸣器
