饿了么推荐算法演进与在线学习实践解析
版权申诉
177 浏览量
更新于2024-07-05
收藏 3.44MB PDF 举报
“饿了么推荐算法演进及在线学习实践(24页).pdf”
这篇文档详细介绍了饿了么推荐算法的发展历程和在线学习的实践应用。首先,文档从推荐业务的背景出发,阐述了推荐系统在饿了么平台中的重要角色,包括搜索词推荐、营销推荐、类目入口、首页推荐和品质推荐等多元化的产品形态,覆盖了全网90%以上的搜索推荐订单。
接着,文档详细梳理了推荐算法的演进路线。初期,推荐系统依赖于人工经验提取的规则,但这种方法效率低且无法实现个性化。随后,系统转向线性模型,通过自动学习人工特征权重,逐步引入简单的用户特征,实现了初步的个性化推荐。随着技术的发展,树模型和多模型融合被采用,结合用户实时行为反馈,进一步提升了推荐的个性化程度。最终,系统采用非线性模型,如DeepFM,实现了对象向量化表达,特征与模型实时在线更新,极大地提高了推荐的时效性和准确性。
在数据和特征方面,系统经历了从离线拼接到在线生成的转变,特征覆盖和波动实时监控得到了强化,数据采集也从天级提升到实时级别,引入了多维度实时特征和大规模稀疏特征,同时利用向量表达(item/user/query)来增强表示能力。
在线学习是演进过程中的关键部分,它允许模型在接收新数据时不断更新和优化,从而快速适应业务变化。文档提到了在线服务的架构,包括数据服务、画像服务、实时数据处理、查询理解以及基于Spark、Flume、Hadoop、Storm等工具构建的基础设施。推荐系统通过Rank特征加载和模型排序,对点击率、转化率和客单价进行预估,使用GBDT、GBDT+FTRL和DeepFM等模型进行预测。
推荐系统架构分为基础设施层、特征服务层、算法/模型层和产品/业务层,各层协同工作,确保推荐的高效和精准。数据来源包括业务日志、服务端日志和用户行为日志,特征则涵盖了用户特征、上下文特征和交叉组合特征,服务于搜索列表、品类列表和活动会场等多个场景。
这份文档全面展示了饿了么如何通过不断的技术迭代和在线学习,构建了一个能够实时响应用户需求、提供个性化推荐的强大推荐系统。
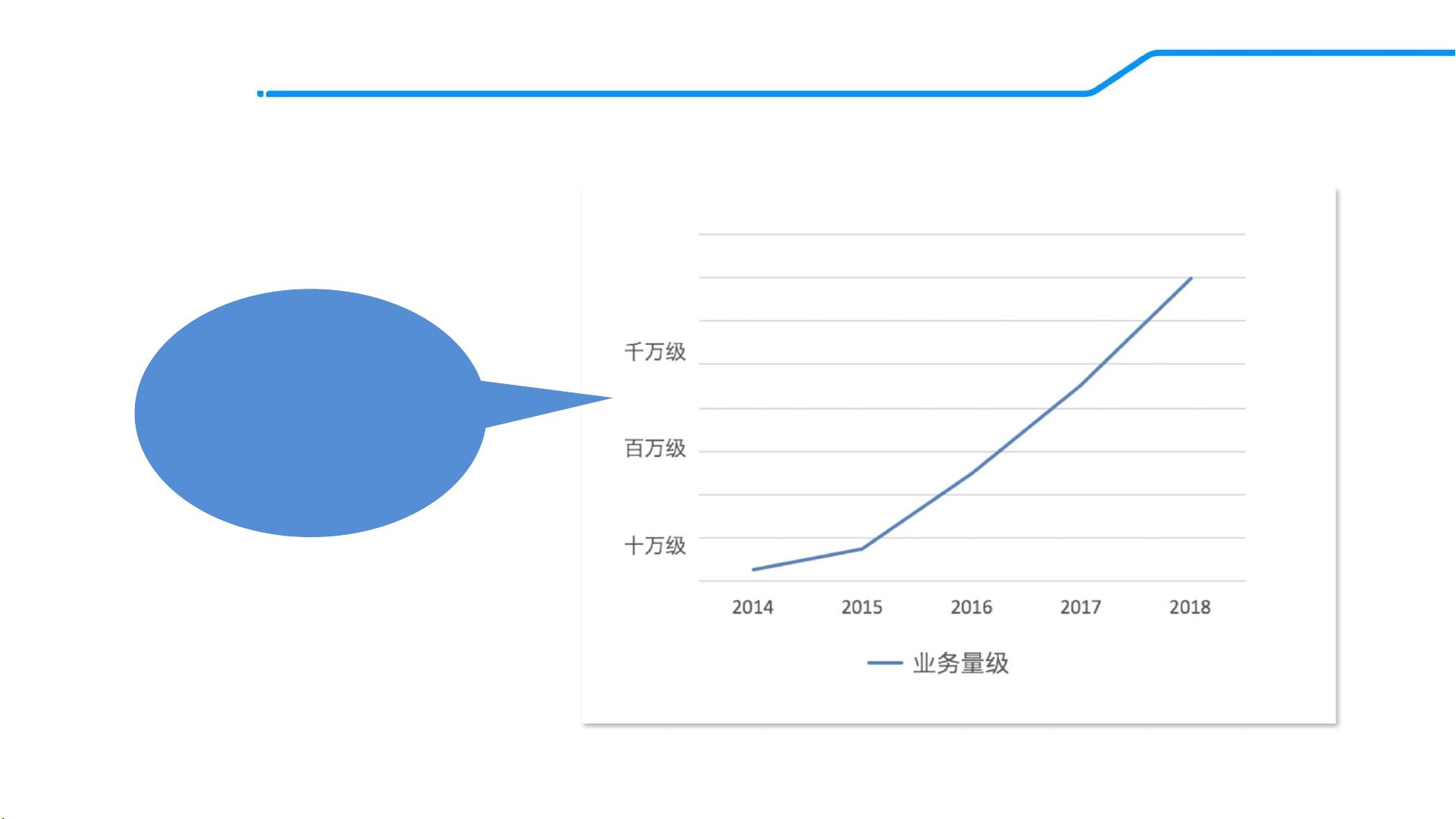
业务趋势
搜索推荐订单覆盖
全网90%以上
剩余23页未读,继续阅读
8982 浏览量
3348 浏览量
3769 浏览量
2022-03-18 上传
126 浏览量
2019-12-20 上传
2023-09-09 上传
2020-07-08 上传
126 浏览量









