Hive入门指南:基础知识与环境搭建
需积分: 9 136 浏览量
更新于2024-07-16
收藏 1.22MB PDF 举报
Hive-part1-基础知识.pdf是一份详细介绍Hive基础知识的文档,涵盖了Hive的基本概念、与RDBMS和HBase的比较、架构、数据存储以及环境搭建和基本使用等内容。以下是对这些关键知识点的详细解读:
1. **Hive基本概念**:
- **Hive简介**
Hive是由Facebook开发并开源的大数据处理工具,它建立在Hadoop之上,主要用于管理和处理大规模结构化数据。Hive的核心特性包括:
- 将HDFS中的非结构化数据转换为结构化的表,便于用户使用Hive SQL进行查询。
- 提供HiveQL语言,允许用户编写类似SQL的查询,简化了对分布式数据的处理。
- 通过将SQL语句转化为MapReduce任务执行,使得不熟悉MapReduce技术的用户也能高效地进行批处理计算。
2. **与RDBMS和HBase的比较**:
- Hive与关系型数据库管理系统(RDBMS)相比,更侧重于大规模数据处理,而RDBMS更适合实时事务处理和较小规模的数据操作。
- Hive与列式存储的NoSQL数据库HBase相比,Hive适合于读多写少的场景,查询性能较好,但写入速度相对较慢。
3. **Hive架构**:
- Hive包含元数据存储层,用于存储关于表结构的信息;数据存储层通常基于HDFS,数据以列式存储,有利于优化查询性能。
- HiveServer是Hive的核心组件,包括HiveServer2和Beeline,前者提供服务端接口,后者是命令行客户端工具。
4. **Hive环境搭建**:
- 安装选项包括内嵌Derby数据库(内存模式)、外置MySQL等,以及在Linux上通过RPM包安装MySQL。
- 搭建过程涉及安装Hive、配置环境变量、设置元数据库,并介绍三种主要的连接方式:CLI、HiveServer2/beeline和Web UI。
5. **Hive基本使用**:
- 用户通过HiveServer2/beeline客户端或Web UI与Hive交互,执行HiveQL语句来操作数据仓库。
- HiveQL支持常见的SQL操作,如创建表、插入数据、查询、聚合函数等,但不支持复杂的事务处理。
Hive-part1-基础知识.pdf为读者提供了全面的入门指南,帮助理解Hive如何作为大数据处理工具,以及如何在实际环境中安装、配置和使用它来进行大规模数据的分析和查询。这对于理解和应用Hadoop生态系统至关重要。
Stay hungry Stay foolish --马中华-- http://blog.csdn.net/zhongqi2513
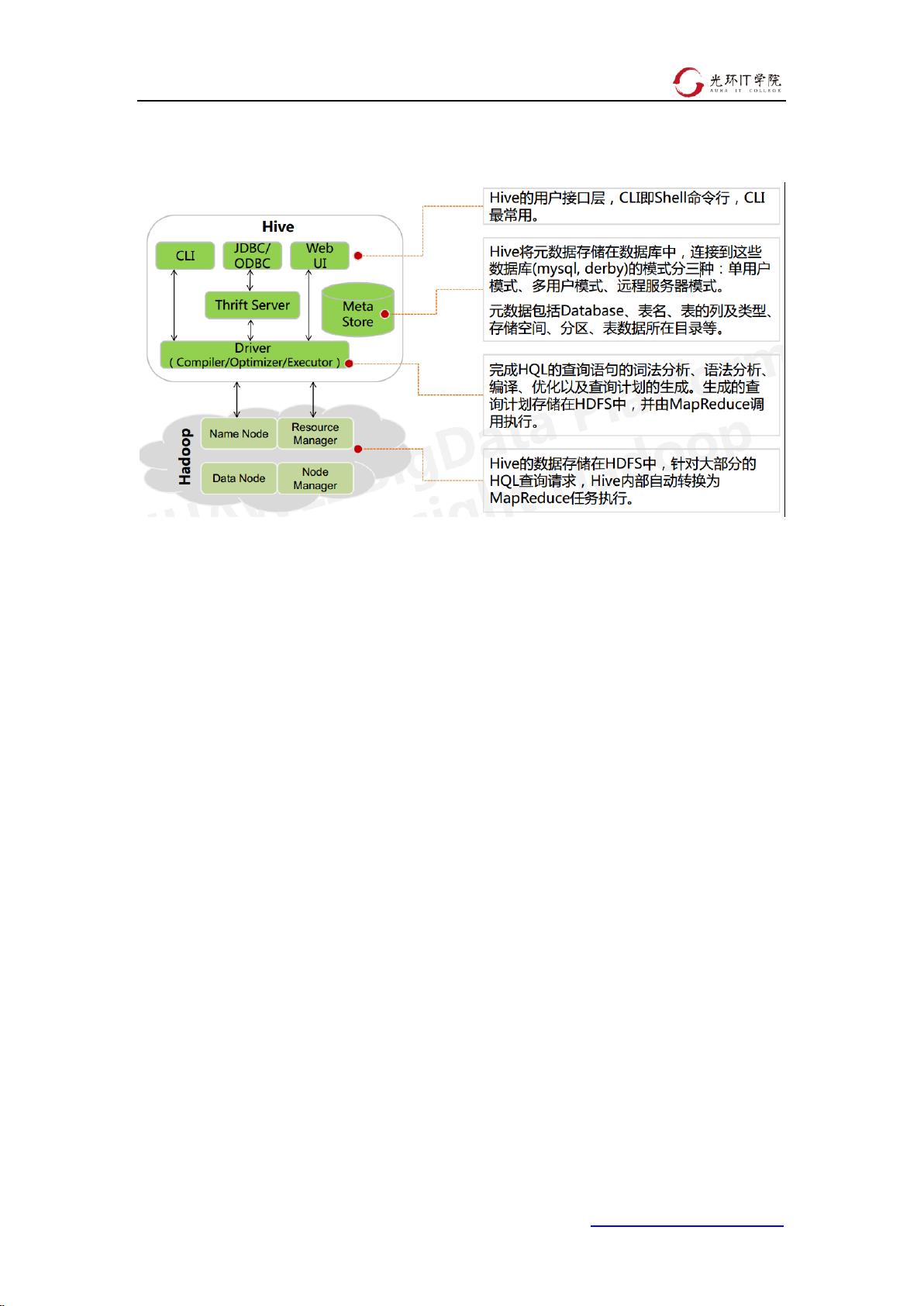
1.4、Hive 架构
基本组成
一、用户接口
CLI,Shell 终端命令行(Command Line Interface),采用交互形式使用 Hive 命令行与 Hive
进行交互,最常用(学习,调试,生产)
JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过
这连接至 Hive server 服务
Web UI,通过浏览器访问 Hive
二、Thrift Server
Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发,
Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口
三、元数据存储
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和
外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存
储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程)
Hive 和 MySQL 之间通过 MetaStore 服务交互
四、Driver:编译器(Compiler),优化器(Optimizer),执行器(Executor)
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行
计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
剩余15页未读,继续阅读
2024-07-20 上传
2021-10-18 上传
点击了解资源详情

qq_22733131
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- gtasa_vita:GTA:SA Vita
- BingWallPaperAutoDownload
- IsthisVegan-
- STM32 无感无刷直流电机开发板资料(原理图、MDK源码、参考资料等)-电路方案
- SocialMediaApp:使用Python(Django Rest Framework)和React Js构建的社交媒体应用程序的前端,并通过Redux来管理我的应用程序状态
- contentful-aws-lambda-static:使用 Contentful 和 AWS Lambda 的静态站点生成实验
- mern-exercise-tracker:MERN运动追踪器(教程)
- Python库 | imath_requests-0.1.2.tar.gz
- javascript-lemmatizer:JavaScript Lemmatizer 是一个词形还原库,用于从英语屈折词中检索基本形式
- Company_Named_Entity_Recognition:对于这个项目,我使用了与命名实体识别相关联的公共库,称为“ spaCy”。 具体来说,当输入大量文本数据作为输入时,我创建了一种训练算法来训练spaCy识别财富500强公司名称
- Data-Visualization-
- 可自动调整的24V步进电机设计(硬件+源代码+BOM等)-电路方案
- PayPal Express Checkout-开源
- my_first_rails_app
- react_crud
- hopfield-colors:训练 Hopfield 循环神经网络识别颜色并使用它来解释图像
