使用Keras处理Quora问题对相似性:特征选择与数据分布调整
需积分: 0 201 浏览量
更新于2024-08-04
收藏 298KB DOCX 举报
"16337341+朱志儒2的实验报告"
这篇实验报告主要探讨了在处理Quora问题对相似性检测任务中的特征选择和模型训练策略。实验者使用了Windows 10 64位操作系统,搭载Intel Core i5-6300HQ CPU和8GB内存以及NVIDIA GeForce GTX 950M GPU,并选择了Python编程语言,利用了包括pandas, numpy, gensim, Keras, sklearn, nltk和matplotlib等在内的多个Python库。
在特征选择阶段,报告指出Quora的训练数据集包含大约40万个问题对,每个问题对由四个元素构成:问题对ID,两个单独的问题ID(qid1和qid2),以及问题内容(question1和question2),并标记了是否为重复问题(is_duplicate)。注意到正样本(重复问题)的比例为0.3692,而以此比例作为测试集的预测结果时,得到的logloss为0.55。为了评估模型在训练集上的性能,计算了训练集的logloss为0.6585。这个较大的差距表明训练集和测试集之间的数据分布存在差异。
为了解决这个问题,实验者利用Keras的`class_weight`参数来调整模型的训练过程,通过加权损失函数来平衡正负样本的影响力。这样做的目的是使模型能够更好地适应测试集的分布。
接着,实验者进行了文本预处理,移除了停用词,并计算了每个问题对中的单词数量。通过将问题1和问题2的文本合并成一个Series,然后应用lambda函数来计算每个问题对的单词长度。分别计算了训练集和测试集的平均单词数,这有助于进一步分析两个数据集的差异,并可能作为特征用于模型训练。
由于报告中未提供完整的实验结果和模型细节,如具体模型结构、训练过程、评估指标和最终性能,我们无法深入讨论模型的优劣或优化策略。然而,可以看出实验者已经意识到数据不平衡问题并采取了相应的权重调整措施,这是在处理不平衡数据集时的一个常见且重要的步骤。此外,通过计算问题的单词数,实验者可能在尝试构建基于词频的特征,如TF-IDF,这对于文本相似性任务是常见的做法。
question2.append(word)
return abs(len(question1) - len(question2))
train_length_difference = train_set.apply(length_difference, axis=1,
raw=True)
print("Duplicate 平均值:", np.mean(train_length_difference[train_set
['is_duplicate'] == 1]))
print("Not Duplicate 平均值:", np.mean(train_length_difference[train_set
['is_duplicate'] == 0]))
plot.hist(train_length_difference[train_set['is_duplicate'] == 1],
range=[0, 20], normed=True, label='Duplicate')
plot.hist(train_length_difference[train_set['is_duplicate'] == 0],
range=[0, 20], normed=True, alpha=0.7, label='Not Duplicate')
plot.xlabel("length difference")
plot.ylabel("frequency")
plot.legend()
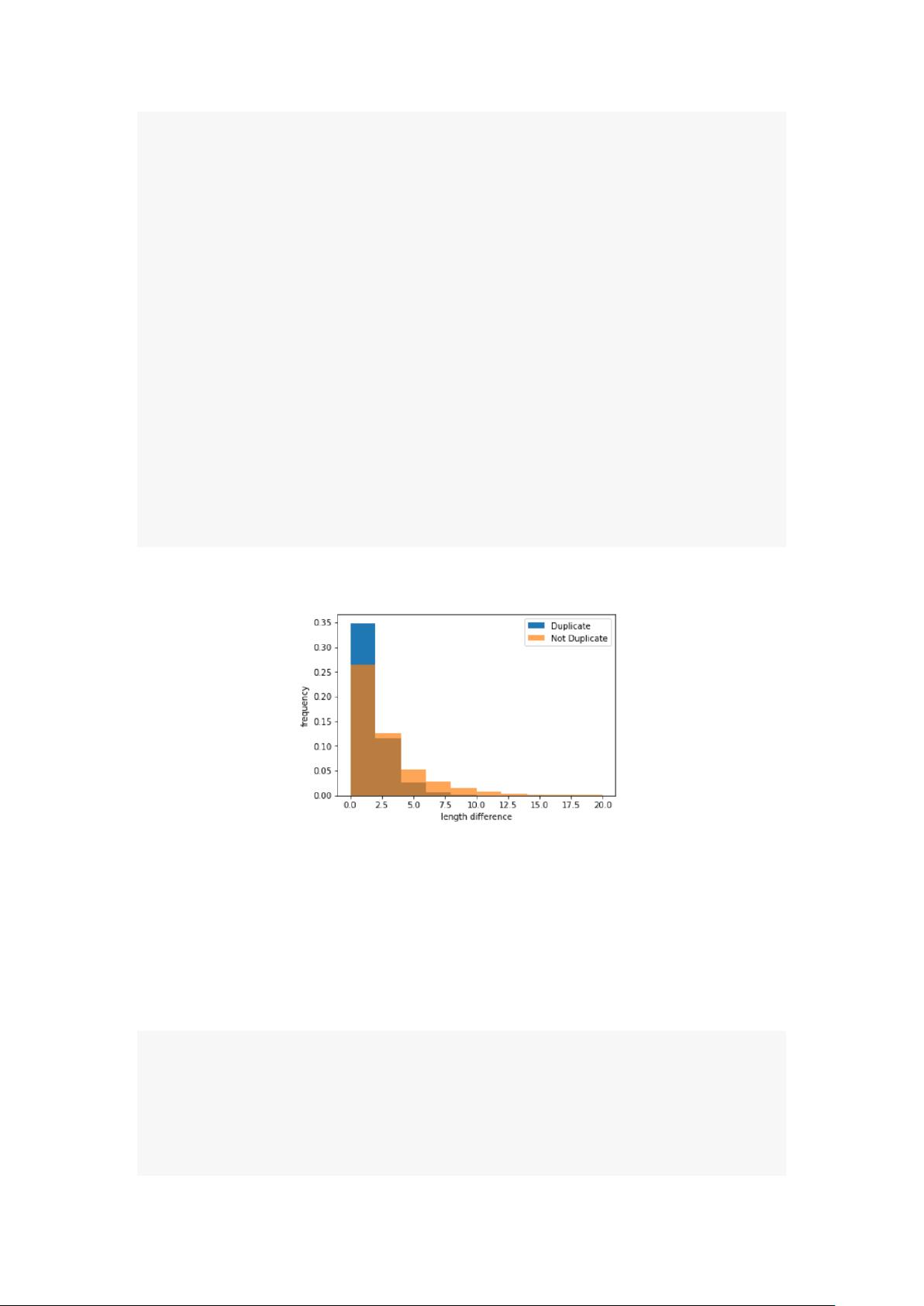
可以得到:
其中,标签为“Duplicate”的问题对的平均值为 1.2556,标签为“Not Duplicate”的问题对
的平均值为 2.3762。由图可知标签为“Not Duplicate”的问题对中单词量差别更大一些,而标
签为“Duplicate”的问题对中单词量差别较小。
对于训练集的问题对,除去停用词后,统计两个问题中相同单词的数目,代码如下:
def find_same(row):
question1 = []
question2 = []
for word in str(row['question1']).lower().split(' '):
if word not in stop:
question1.append(word)
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-03 上传
2022-08-08 上传
2022-08-08 上传









