信息检索模型详解:VSM与概率模型在搜索引擎中的应用
需积分: 37 61 浏览量
更新于2024-07-21
收藏 2.2MB PPT 举报
IR_计算模型是信息检索领域中的核心概念,它是一种用于对用户查询进行文档排序的理论框架和算法集合。该模型的核心目标是根据用户的查询需求,找出与之最相关的文档集合。IR模型的基本构成包括四个元素:
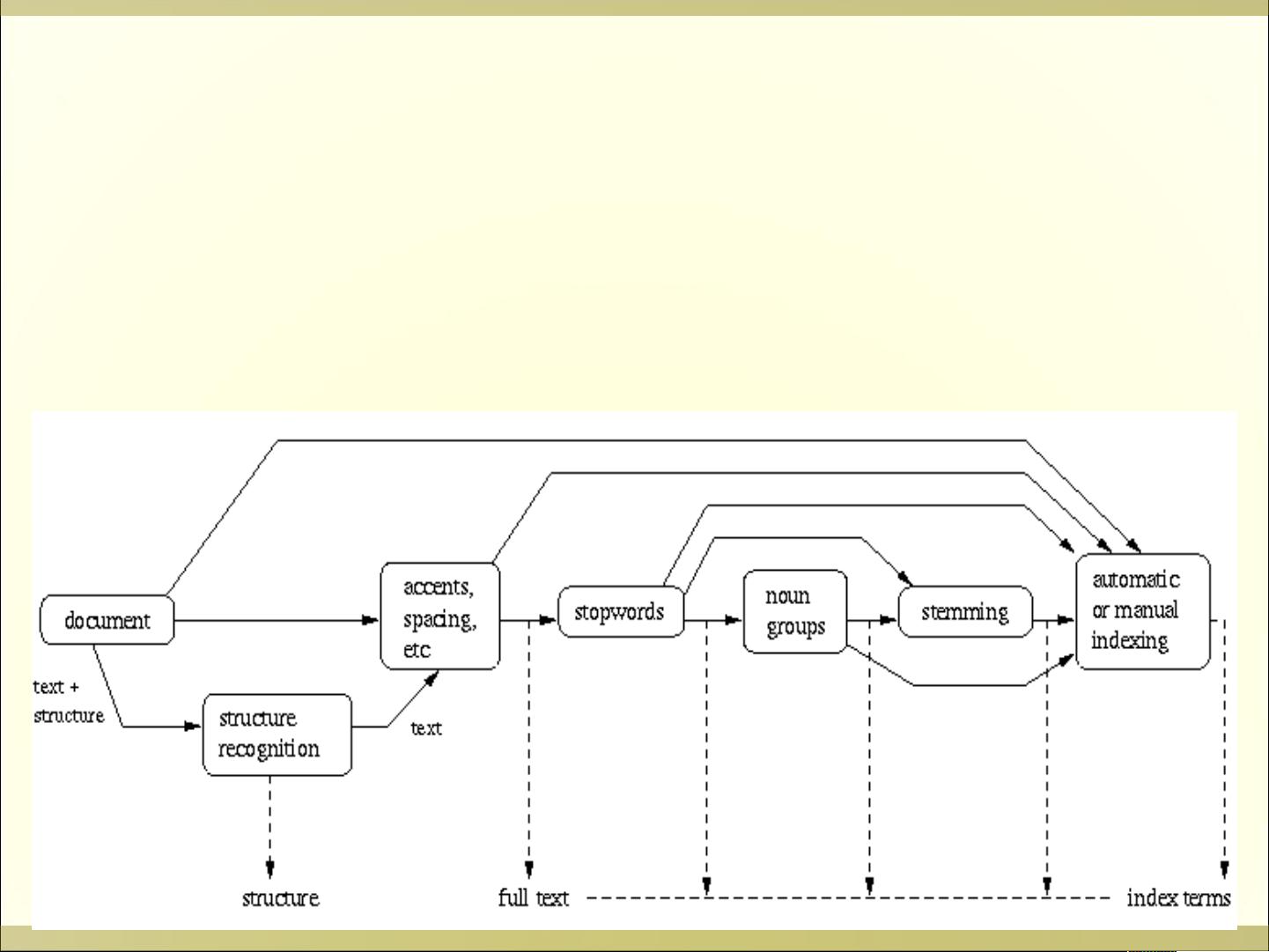
1. 文档集合D:由一组文档组成,这些文档可以通过逻辑视图来表示,通常是作为一组索引词或关键词。在实践中,文档可以是文本、图像、视频等形式,每种类型的文档有不同的表示方式:
- 文本文档:通过词汇集合表示,例如在倒排文档表示方法中,使用词级倒排文件(Word-Level Inverted File)。
- 图像:包含文本和图像特征,如图片的标签、颜色、纹理等。
- 视频:由图像帧序列和音频信息构成。
2. 查询集合Q:用户输入的查询,通常以关键词或布尔表达式的形式呈现,如"porridge & pot"。未来可能会扩展到更复杂的查询类型,如自然语言句子、文档样本、图像、草图或有向标记树。
3. 框架F:这是检索系统的基础架构,涉及预处理(如清理、标准化)、中间处理(如分类、聚类、索引构建)等步骤,用于构建文档、查询以及它们之间的关系。
4. 排序函数R(qi, dj):这是模型的核心,用于计算查询qi与文档dj之间的相关性得分,常见的衡量标准包括关键词匹配数量和Google的PageRank算法。
IR模型可以大致分为三类:
- 基于内容的信息检索模型:这类模型关注查询和文档内容的相似度,常见的有布尔模型(基于逻辑运算)、模糊集合模型(考虑部分匹配)、向量空间模型(VSM,通过计算词向量的余弦相似度)和潜在语义索引(LSI或LDA)等。
- 结构化模型:强调文档的结构信息,如XML或JSON,用于解析和组织数据。
- 浏览型数学模型:这种模型较少依赖文档内容,更多地依赖用户的行为和交互,如点击流模型。
IR_计算模型是一个复杂且不断发展演变的领域,随着技术的进步,其内容表示和查询处理方式也在不断更新和优化,以更好地满足用户的信息需求。
文本文档逻辑视图
•
D 是一个文档集合,通常由文档逻辑视图来表示。可以
是一组索引词或关键词。既可以自动提取,也可以是由
人主观指定。

剩余49页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-09-24 上传
2021-02-20 上传
164 浏览量
2021-09-28 上传
2021-09-29 上传
2022-09-15 上传

大猫whiskey
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 20210218_z中文latex-lshort.zip
- dynamic-programming:动态编程问题的解决方案
- cryptoverse-wars-backend
- NHSRdatasets:这是CRAN R软件包系统信息库的只读镜像。 NHSRdatasets —用于教育和培训的与NHS和医疗保健相关的数据。 主页
- LUA5.3支持库1.6版(lua4.fne)-易语言
- three-squirrels-web
- Q00CPU与HITECH触摸屏的通讯的示例。.zip三菱PLC编程案例源码资料编程控制器应用通讯通信例子程序实例
- petGame
- todos-app:使用Laravel框架php解决我的100daysofcode挑战的TODO应用程序
- AI Partition(银灿U盘分区工具)V2.0.0.3
- Stranger-Things:使用JS,jQuery和封闭源社区数据库构建了“消费者对消费者”(C2C)在线交易平台
- 屏蔽win键-易语言
- zenn
- flash_unde_noaxu
- pokedex-react-app-ts
- WiseBot:怀斯(Wise)打造的神奇机器人
