统一多尺度深度卷积神经网络:快速对象检测的新进展
需积分: 10 43 浏览量
更新于2024-07-20
收藏 431KB PDF 举报
标题:"A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection"(统一多尺度深度卷积神经网络:快速目标检测)
该研究论文介绍了一种新型的深度学习架构,名为多尺度卷积神经网络(MS-CNN),它旨在提升对象检测的速度和性能,特别针对包含大量小目标的数据集,如KITTI和Caltech。MS-CNN由两个主要子网络组成:提议子网络和检测子网络。
在提议子网络中,关键创新在于设计了多个输出层进行检测,这样可以适应不同尺度的对象。每个输出层具有不同的感受野,能够捕获不同大小物体的特征,增强了对尺度变化的鲁棒性。这种设计使得MS-CNN能够在处理规模差异显著的目标时保持高效。
此外,MS-CNN采用了端到端的学习方式,通过优化一个多任务损失函数来训练整个网络。传统的输入上采样方法在处理大图像和高分辨率输入时可能会增加内存和计算成本,因此论文中还探讨了使用反卷积(deconvolution)来进行特征上采样,作为一种更有效的替代方案。这种方法不仅可以减少计算开销,还有助于保留更多的细节信息。
值得注意的是,MS-CNN在保持高精度的同时,达到了每秒15帧的实时性能,这对于实时应用如自动驾驶、视频监控等具有重要意义。由于其在速度和准确性方面的出色表现,MS-CNN在当时是计算机视觉领域的前沿技术,并且对后续的小目标检测和实时物体识别算法产生了深远影响。
关键词包括:对象检测、多尺度、深度学习、卷积神经网络、提议生成、实时性能、多任务学习和特征上采样。这一研究展示了如何通过深度学习技术优化目标检测流程,以适应不断增长的实际需求。
4 Zhaowei Cai, Quanfu Fan, Rogerio S. Feris, and Nuno Vasconcelos
(a) (d)(b) (e) (f) (g)(c)
input image
feature map
model template
CNN layers
approximated
feature map
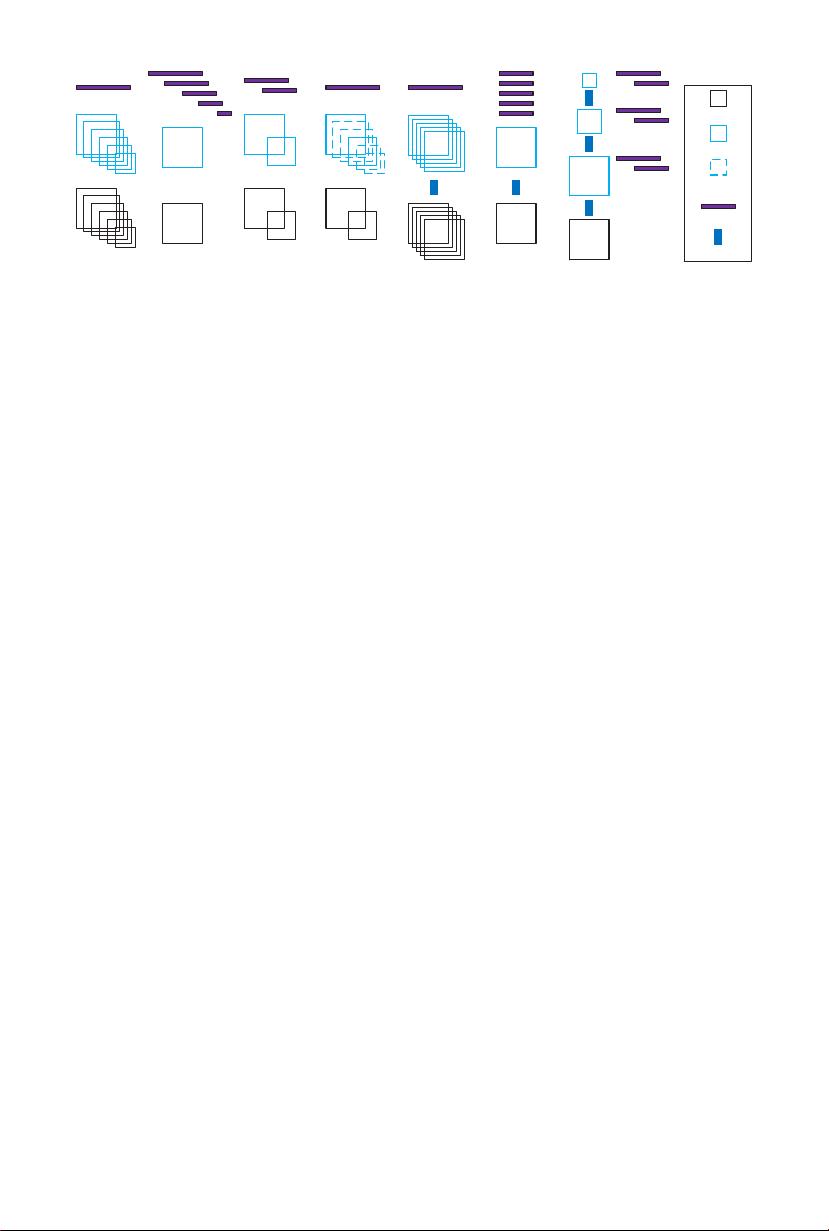
Fig. 2. Different strategies for multi-scale detection. The length of model template
represents the template size.
3.1 Multi-scale Detection
The coverag e of ma ny object scales is a critical problem for object detection.
Since a de tector is bas ic ally a dot-product between a learned template and an
image regio n, the template has to be matched to the spatial support of the object
to reco gnize. There are two ma in strategies to achieve this goal. The first is to
learn a single classifier and rescale the image multiple times, so that the classifier
can match all possible object sizes. As illustrated in Fig. 2 (a ), this strategy
requires feature computation at multiple image scales. While it usually produces
the most accurate detec tion, it tends to be very costly. An alternative approach
is to apply multiple classifiers to a single input image. This strategy, illustrated
in Fig. 2 (b), avoids the repeated computation of feature maps and tends to be
efficient. However, it requires an indiv idual classifier for each object scale and
usually fails to produce good detectors. Several approaches have been proposed
to achieve a good trade-off between accuracy and complexity. For example, the
strategy of Fig. 2 (c) is to rescale the input a few times and learn a small number
of model templates [24]. Another possibility is the feature approximation of [2].
As shown in Fig. 2 (d), this consists of rescaling the input a small number of
times and interpolating the missing feature maps. This has been shown to achieve
considerable speed-ups for a very modest loss of classification accur acy [2].
The implementation of multi-scale strategies on CNN-based detectors is slightly
different from those discussed above, due to the complexity of CNN features. As
shown in Fig. 2 (e), the R-CNN of [3] simply warps object proposal patches
to the natural scale of the CNN. This is somewhat similar to Fig. 2 (a), but
features are computed for patches rather than the entire image. The multi-scale
mechanism of the RPN [9], shown in Fig . 2 (f), is simila r to that of Fig. 2 (b).
However, multiple sets of templates of the same size are applied to all feature
maps. This can lead to a severe scale inconsistency for template matching. As
shown in Fig. 1, the single scale of the feature maps, dic tated by the (228×228)
receptive field o f the CNN, can be severely mismatched to s mall (e.g. 32×32) or
large (e.g. 640×64 0) objects. This compromises object detection performance.
Inspired by previous evidence on the benefits of the strategy of Fig. 2 (c)
over that of Fig. 2 (b), we propo se a new multi-sc ale stra tegy, shown in Fig. 2
剩余15页未读,继续阅读
793 浏览量
1797 浏览量
175 浏览量
603 浏览量
149 浏览量
411 浏览量
2024-11-20 上传
122 浏览量









