中文自然语言处理入门:从获取语料到预处理
需积分: 14 174 浏览量
更新于2024-07-09
1
收藏 7.21MB PDF 举报
"这篇文档是关于中文自然语言处理(NLP)的入门学习资料,主要介绍了NLP的基本流程,包括获取语料、语料预处理等关键步骤,并提及了语料预处理中的数据清洗、分词、词性标注和去停用词等技术。文档还提到了不同类型语料的来源,如已有语料和网上抓取的语料,并强调了语料预处理在NLP项目中的重要性,占据了大约50%-70%的工作量。"
在自然语言处理领域,中文NLP是至关重要的一个分支,特别是在人工智能背景下。2016年的AlphaGo与人类棋手的对决,引发了人们对机器智能的广泛讨论。机器是否能理解人类的语言,是这个领域的核心问题之一。本文旨在引导读者理解一个完整的NLP处理过程。
首先,NLP涉及的技术知识点繁多,包括文本分析、情感分析、语义理解等。虽然提供的图表给出了一种分析视角,但它可能并不全面,因为NLP在AI领域中涉及的范围更为广泛。
中文NLP的基本流程通常包括以下几个步骤:
1. **获取语料**:这是NLP项目的起点。语料可以来自已有的纸质或电子文本资料,经过整理和电子化后形成语料库。另一种方式是从网上下载或通过爬虫抓取公开数据集,如搜狗语料库和人民日报语料库。
2. **语料预处理**:这是NLP中最耗时的部分,占项目工作量的50%-70%。预处理主要包括:
- **数据清洗**:去除无用信息,如网页爬取时的广告、HTML标签等,提取出有用的内容,如标题、摘要和正文。
- **分词**:将连续的汉字序列切分成有意义的词汇,这是中文NLP的基础,因为中文没有明显的词形变化。
- **词性标注**:为每个词汇添加词性标记,帮助识别词汇的功能和意义,如名词、动词、形容词等。
- **去停用词**:移除常见的无实际含义或功能的词语,如“的”、“和”、“是”等,以减少后续处理的复杂性。
预处理的目的是将原始文本转化为可供算法分析的形式,以便进行更复杂的任务,如情感分析、命名实体识别、机器翻译和问答系统等。
掌握这些基本概念和步骤,是进入中文NLP领域的基础。通过不断学习和实践,可以深入理解和应用NLP技术,解决实际问题,推动人工智能的进步。

1. import jieba.posseg as psg
2. print([(x.word,x.flag) for x in psg.lcut(content)])
结果为:
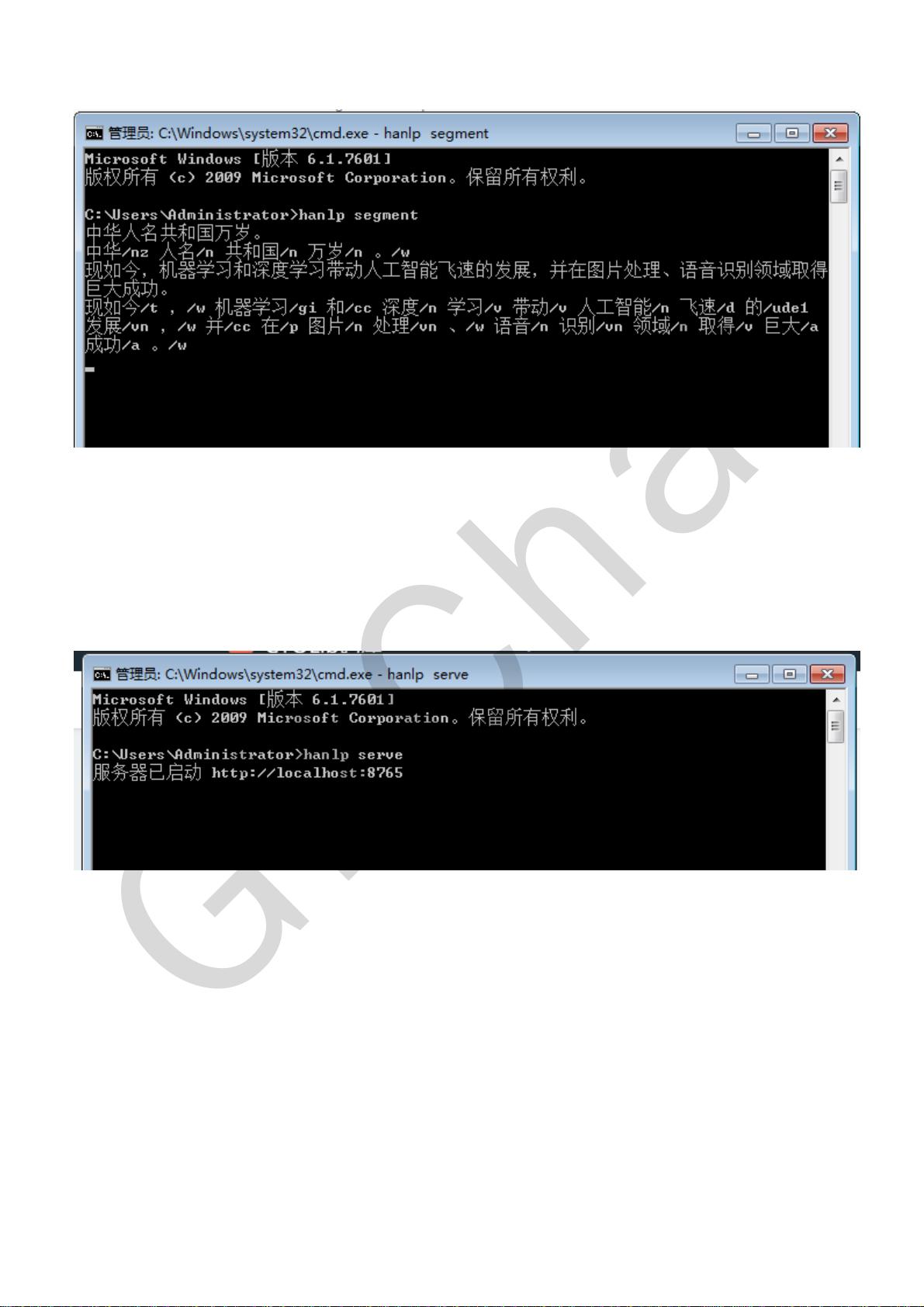
[('现如今', 't'), (',', 'x'), ('机器', 'n'), ('学习', 'v'), ('和', 'c'), ('深度', 'ns'), ('学习', 'v'), ('带
动', 'v'), ('人工智能', 'n'), ('飞速', 'n'), ('的', 'uj'), ('发展', 'vn'), (',', 'x'), ('并', 'c'), ('在',
'p'), ('图片', 'n'), ('处理', 'v'), ('、', 'x'), ('语音', 'n'), ('识别', 'v'), ('领域', 'n'), ('取得', 'v'),
('巨大成功', 'nr'), ('。', 'x')]
(6)并行分词
并行分词原理为文本按行分隔后,分配到多个 Python 进程并行分词,最后归并结果。
用法:
1. jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数 。
2. jieba.disable_parallel() # 关闭并行分词模式 。
注意: 并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。目前暂不支持 Windows。
(7)获取分词结果中词列表的 top n
1. from collections import Counter
2. top5= Counter(segs_5).most_common(5)
3. print(top5)
结果为:
[(',', 2), ('学习', 2), ('现如今', 1), ('机器', 1), ('和', 1)]
(8)自定义添加词和字典
默认情况下,使用默认分词,是识别不出这句话中的“铁甲网”这个新词,这里使用用户字典
提高分词准确性。
GitChat



剩余217页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-05-25 上传
2015-07-22 上传
2019-11-05 上传
2019-09-16 上传
2020-03-08 上传
2021-08-30 上传

青卿84569
- 粉丝: 24
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
