自组织加权增量概率潜在语义分析:面向大数据文档分类的高效方法
需积分: 5 72 浏览量
更新于2024-08-13
收藏 2.85MB PDF 举报
本文献主要探讨了一种名为“自组织加权增量概率潜在语义分析”(Self-Organizing Weighted Incremental Probabilistic Latent Semantic Analysis, WIPLSA)的研究方法。随着信息技术的发展,大量的数字内容如新闻、博客、网页、科研文章、书籍等不断涌现,使得信息检索和理解变得愈发复杂。为了应对大数据时代的挑战,研究人员提出了一种适应大规模数据集的新型文本挖掘工具,WIPLSA。
WIPLSA结合了概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)与自组织学习(Self-Organization)和增量学习(Incremental Learning)的理念。PLSA是一种常用的主题模型,它通过分析文档中词语的共现关系来揭示潜在的主题结构。然而,传统PLSA在处理大规模数据时可能会遇到效率问题,特别是当数据集不断增长时。
自组织学习强调的是系统自我组织和优化的能力,它能够在无监督或半监督的环境下,通过对数据进行聚类和组织,形成一种无需预先设定的结构。在WIPLSA中,这种特性被用来处理文档中的多主题场景,使得模型能够自动发现和识别文档中的不同主题及其相关性。
增量学习则是指模型能够在新数据到来时,实时地更新和改进其性能,而无需重新训练整个模型。这对于处理实时流式数据或不断增长的数据集至关重要。WIPLSA通过增量的方式处理新文档,只对相关的部分进行权重调整,从而提高了计算效率和存储效率。
论文指出,WIPLSA的优势在于它在大型数据集上的适用性,以及在文档分类任务中的良好性能。关键词包括概率潜在语义分析、增量学习、相似度和大数据。作者们在2016年2月5日接收了这篇论文,并于2017年4月10日接受发表,版权归属Springer-Verlag Berlin Heidelberg。
总结来说,这项研究提供了对大规模文本数据的一种有效处理策略,通过结合自组织、增量学习和概率潜在语义分析,WIPLSA为文本挖掘和信息检索提供了一个更为高效和灵活的解决方案。对于大数据时代的信息管理而言,这是一种具有实际应用价值的技术革新。
Int. J. Mach. Learn. & Cyber.
1 3
probability, it is supposed to be considered as a topic about
“sports”. We use
P
(d
i
)
to denote the probability that a par-
ticular document
d
i
will be observed,
P(w
j
|z
k
)
denotes the
class-conditional probability of a specific word conditioned
on the latent class variable
z
k
, and
P(z
k
|d
i
)
signifies a docu-
ment specific probability distribution over the latent vari-
able space. Each word
w
j
in document
d
i
can be generated
as follows. First, select a document
d
i
with probability
P
(d
i
)
.
Second, pick a latent class
z
k
with probability
P(z
k
|d
i
)
, and
finally generate a word
w
j
with probability
P
(w
j
|
z
k
)
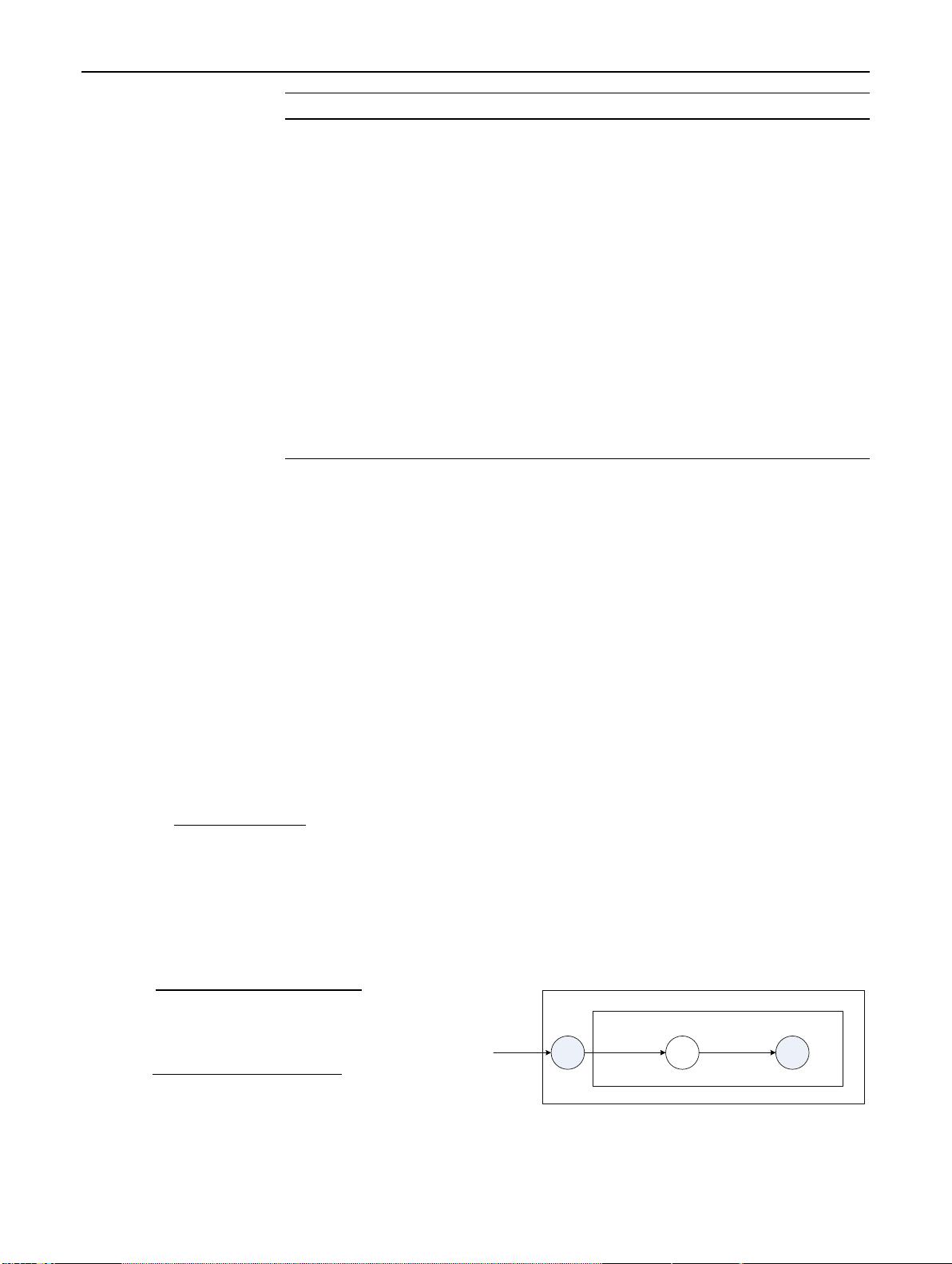
. Figure1
is the graphic model.
The standard procedure for maximum likelihood estima-
tion in PLSA is the Expectation Maximization (EM) algo-
tithm [21]. According to EM algorithm and the PLSA model,
in the E-step, P(z|d,w) is updated by Eq. (1).
It is the probability that a word w in a particular docu-
ment d is explained by the topic corresponding to z. In the
M-step, we update P(w|z) and P(z|d) by Eqs. (2) and (3)
respectively.
(1)
P
(z
k
�
d
i
, w
j
)=
P(w
j
�z
k
)P(z
k
�d
i
)
∑
K
l=1
P(w
j
�
z
l
)P(z
l
�
d
i
)
(2)
P
(w
j
�
z
k
)=
∑
N
i=1
n(d
i
, w
j
)P(z
k
�
d
i
, w
j
)
∑
M
m=1
∑
N
i=1
n(d
i
, w
m
)P(z
k
�
d
i
, w
m
)
(3)
P
(z
k
�
d
i
)=
∑
M
j=1
n(d
i
, w
j
)P(z
k
�
d
i
, w
j
)
∑
K
l=1
∑
M
j=1
n(d
i
, w
j
)P(z
l
�
d
i
, w
j
)
3 Related work
In this section, we will introduce the main incremental
technologies to PLSA and highlights MAP PLSA and
QB PLSA. Due to the variability of increasing data, it is
necessary to discover the dynamic topics and process the
large data set incrementally. Moreover, PLSA models suf-
fer from the problem of inferencing new documents. To
overcome these problems, we incorporate new words and
documents into an existing system for updating a PLSA
model and different updating methods are utilized for
model learning [27]. There are several noteworthy related
work. Here, we give a brief introduction.
Hoffmann proposed the “fold-in” update scheme in
[29]. The incremental strategy was to update P(z|d) in
the model while keeping the P(w|z) fixed. A “fold-in”
approach similar to this one was also used in [30]. The
authors proposed incrementally Built Aspect Models
(BAMs) to dynamically discover new topics from docu-
ment streams. BAMs were probabilistic models designed
to accommodate new topics with the spectral algorithm.
This approach retained all the conditional probabilities
of the old words, given the old latent variables, and the
spectral step was used to estimate the probabilities of
Table 1 The notation
convention for parameter
estimation
Notations Explanations
D ={d
1
, d
2
, … , d
N
}
Training/adaptation data with N documents
W ={w
1
, w
2
, … , w
M
}
Vocabulary with M words
K The number of topics
𝜃 ={P(w
j
|z
k
), P(z
k
|d
i
)}
PLSA parameter set with latent variable
z
k
in
Z ={z
1
, … , z
K
}
𝜑 ={
𝛼
j
,
k
, 𝛽
k
,
i
}
Hyperparameters of PLSA parameters
P(w
j
|z
k
)
and
P(z
k
|d
i
)
P(z
k
|d
i
, w
j
)
Posterior probability of latent variable
z
k
generating document
d
i
and word
w
j
n(d
i
, w
j
)
Occurrences of word
w
j
in document
d
i
n(d
i
)
Total occurrences of
{w
1
, … , w
M
} in document
d
i
R(
𝜃|𝜃)
Log posterior probability with current estimate
𝜃
and new estimate
𝜃
𝛾
balance factor between new documents and old documents
n
={D
1
, … , D
n
}
Sequence of adaptation documents
{D
0
, D
1
, … , D
n
}
Sequence of input documents, including training ones and adaptation ones.
𝜑
(n)
={𝛼
(n)
j,k
, 𝛽
(n)
k,i
}
At nth epoch, Hyperparameters of PLSA parameters
P
(
w
j
|z
k
)
and
P(z
k
|d
i
)
V The vector representing the document set which has N documents
v
i
The ith component of V
P(
𝐰
d
i
)
The probability of generating the words in document
d
i
d z w
()
i
pd
(|)
ki
pz d
(|)
jk
pw z
M
N
Fig. 1 The graphic model of PLSA
剩余11页未读,继续阅读
2022-06-19 上传
2024-04-20 上传
2021-04-08 上传
点击了解资源详情
2024-11-11 上传
2024-11-11 上传
2024-11-11 上传

weixin_38668160
- 粉丝: 10
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
