Hadoop HDFS读写流程与NameNode机制解析
版权申诉
"大数据框架知识点总结,主要关注Hadoop的HDFS读写流程及NameNode与SecondaryNameNode的工作机制。"
在大数据处理领域,Hadoop是一个关键的开源框架,其分布式文件系统(HDFS)提供了高容错性和高吞吐量的数据存储能力。以下是HDFS的核心知识点:
### HDFS写数据流程
1. **客户端发起上传请求**:客户端通过DistributedFileSystem接口向NameNode询问是否可以上传文件,并指定文件路径。
2. **NameNode检查**:NameNode检查文件是否存在,以及父目录是否已经创建。
3. **选择DataNode**:客户端得到NameNode的确认后,请求将第一个Block的存储位置,NameNode返回3个DataNode(如dn1、dn2、dn3)。
4. **建立通信管道**:客户端依次与dn1、dn2、dn3建立连接,形成一个数据传输管道。
5. **数据传输**:客户端开始向dn1上传数据,数据以Packet为单位,每个Packet被逐级传递并存储。
6. **应答机制**:每个DataNode在接收到Packet后,会将它发送给下一个节点并等待应答,确保数据完整性。
7. **Block传输**:当一个Block传输完毕,客户端重复上述步骤上传下一个Block。
### HDFS读数据流程
1. **客户端下载请求**:客户端通过DistributedFileSystem向NameNode请求下载文件,获取文件Block的位置信息。
2. **选择DataNode**:NameNode提供最近或随机的DataNode服务器地址。
3. **DataNode传输数据**:选定的DataNode开始读取硬盘上的Block数据,并以Packet为单位进行校验,然后发送给客户端。
4. **客户端接收**:客户端接收Packet,先存储在本地缓存,再写入目标文件。
### NameNode与SecondaryNameNode工作机制
1. **Fsimage**:Fsimage文件保存了HDFS的元数据,包括所有目录和文件的inode信息,是元数据的一个检查点。
2. **Edits文件**:Edits文件记录了所有的更新操作,即自上一次检查点以来的修改。
3. **Seen_txid**:记录了最后应用到Fsimage的事务ID。
**思考:NameNode元数据存储**
NameNode的元数据不直接存储在自身磁盘上,而是通过内存来缓存,以提高访问速度。Fsimage和Edits文件则存储在磁盘上,用于持久化元数据。在系统启动时,NameNode加载Fsimage到内存,然后合并Edits中的更新操作,生成新的Fsimage。SecondaryNameNode的主要职责是定期帮助NameNode合并Fsimage和Edits,防止Edits文件过大导致NameNode重启耗时过长。
这个过程中,SecondaryNameNode并不是NameNode的热备份,它在主NameNode故障时不能接管服务,但可以帮助主NameNode管理元数据,确保系统的稳定运行。因此,理解NameNode和SecondaryNameNode的工作机制对于维护Hadoop集群的健康至关重要。
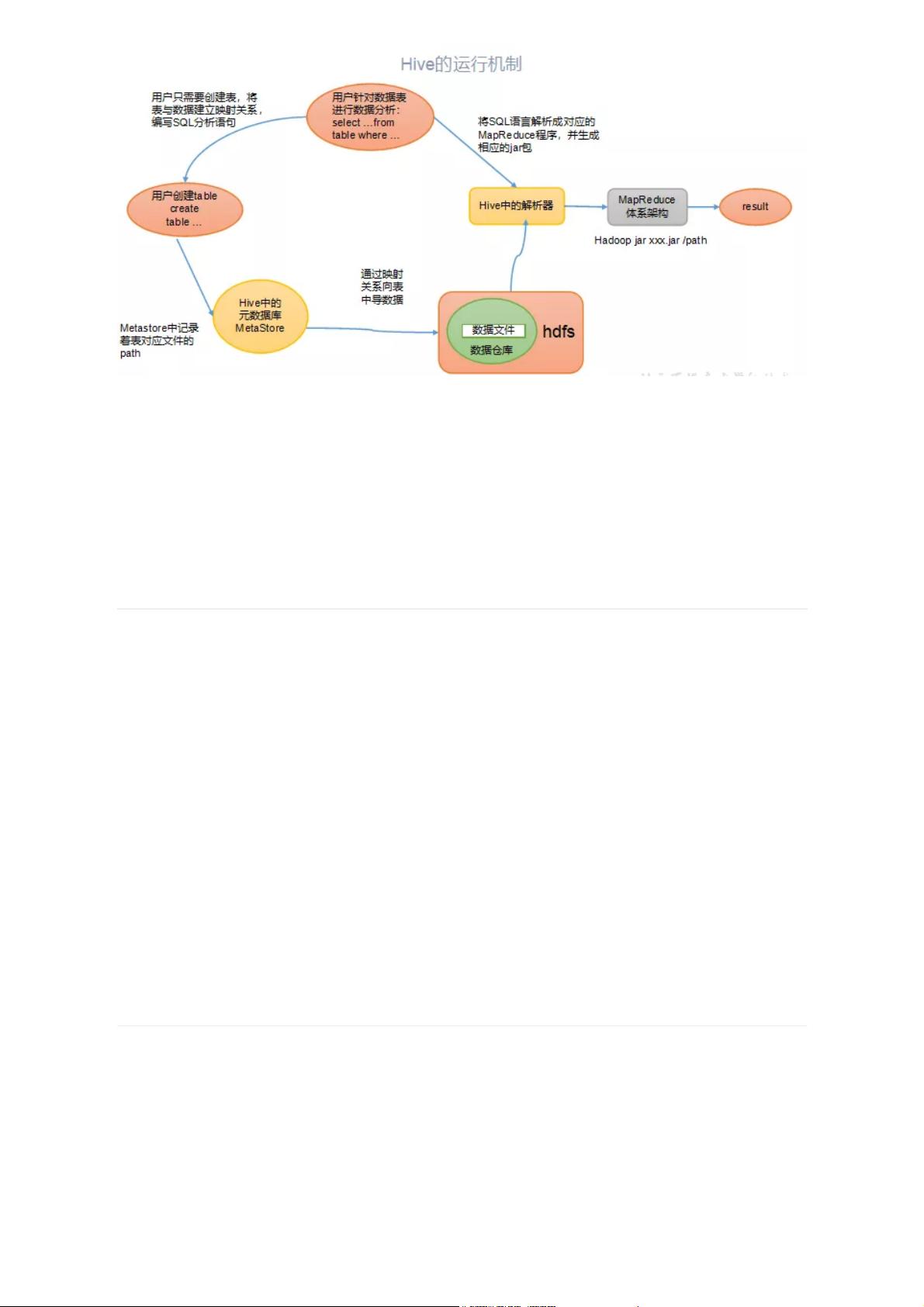
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据
(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出
到用户交互接口。
其实,还可以这样理解:Hive要做的就是将SQL翻译成MapReduce程序代码。实际上,Hive内置了很多
Operator,每个Operator完成一个特定的计算过程,Hive将这些Operator构造成一个有向无环图
DAG,然后根据这些Operator之间是否存在shuffle将其封装到map或者reduce函数中,之后就可以提
交给MapReduce执行了。
内部表与外部表
不同点
1 外部表不会加载数据到Hive,减少数据传输、数据还能共享。
共享的理解就是:当我们删除一个内部表时,Hive 也会删除这个表中数据。内部表不适合和其他工具共
享数据。
2 Hive创建内部表时,会将数据移动到数据仓库指向的路径。
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外
部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
场景选择
在公司中绝大多数场景都是外部表。
自己使用的临时表,才会创建内部表。
Hive分区与分桶
Hive分区
是按照数据表的某列或者某些列分为多区,在hive存储上是hdfs文件,也就是文件夹形式。现在最常用
的跑T+1数据,按当天时间分区的较多。
把每天通过sqoop或者datax拉取的一天的数据存储一个区,也就是所谓的文件夹与文件。在查询时只要
指定分区字段的值就可以直接从该分区查找即可。创建分区表的时候,要通过关键字 partitioned by
(column name string)声明该表是分区表,并且是按照字段column name进行分区,column name
值一致的所有记录存放在一个分区中,分区属性name的类型是string类型。
剩余104页未读,继续阅读
2022-11-24 上传
263 浏览量
2022-11-24 上传
2021-12-22 上传
237 浏览量
2962 浏览量

普通网友
- 粉丝: 13w+
- 资源: 9194
 我的内容管理
展开
我的内容管理
展开







最新资源
- PLSQL DEVELOPER 基本用法详解PLSQL.txt
- Quartus 2 简明操作指南
- 数据挖掘综述 基础文章
- 针对java程序员的UML概述
- SQLPlus主要编辑命令.doc
- 74系列芯片功能大全
- MFC俄罗斯方块制作详细向导
- 网络工程师必备英语词汇表
- SQL Injection 数据库 注入 课件
- UNIX操作入门和100多个命令
- mcs51子程序使用说明与注释
- Manning.Zend.Framework.in.Action.2007.pdf
- Linux入门教程,使用与初学者
- 点对点通讯P2P介绍pdf格式
- delphi考试试题,软件工程师考试试题
- Apress.Pro.PHP.XML.and.Web.Services.Mar.2006.pdf
