深入解析LevelDB:核心概念与实现
“leveldb文档 - 详尽解析淘宝核心系统的存储技术”
本文将深入剖析leveldb,一个由Google开源的轻量级、高性能的键值存储系统,广泛应用于数据库、日志存储等领域。leveldb的核心设计目标是提供快速的读写性能和高效的磁盘空间利用。
一、代码目录结构
leveldb的源码组织结构清晰,主要包括以下几个部分:
1. doc/:包含文档和README等。
2. include/leveldb/:接口头文件,定义了leveldb的主要类和接口。
3. db/:实现了数据库的主要逻辑,如DBImpl、DB等。
4. table/:实现了SSTable,leveldb的数据存储格式。
5. port/:平台相关的代码,如不同操作系统下的I/O操作。
6. util/:通用工具类,如压缩、编码、随机数生成等。
7. helper/memenv/:内存环境的辅助实现。
二、基本概念
1. Slice:一个不可变的字节序列,常用于表示键或值。
2. Option:数据库的配置选项,如压缩、缓存大小等。
3. Env:抽象的环境接口,处理文件I/O、定时任务等,可替换为自定义实现。
4. Varint:可变长度整数编码,用于节省存储空间。
5. ValueType:键值对中的值类型标识,如PUT、DELETE等。
6. SequenceNumber:全局序列号,确保数据的一致性。
7. Userkey:用户提供的键,用于区分数据。
8. ParsedInternalKey:解析后的内部键,包含用户键、序列号和值类型。
9. InternalKey:内部使用的键,用于索引和排序。
10. LookupKey:用于查找内部键的辅助类。
11. Comparator:比较器接口,用于定义键的比较规则。
12. InternalKeyComparator:基于InternalKey的比较器,用于SSTable的排序。
13. WriteBatch:批量写入操作,优化写入性能。
14. Memtable:内存中的键值表,采用SkipList实现。
15. SSTable:Sorted String Table,磁盘上的数据文件。
16. FileMetaData:SSTable的元数据,包括文件名、最大和最小键等。
17. Block:SSTable的基本数据块,包含多个键值对。
18. BlockHandle:指向数据块在文件中的位置。
19. FileNumber:文件编号,用于唯一标识SSTable。
20. filename:文件命名规则,包括生成和解析文件名。
21. Level-n:leveldb的多层数据结构,数据分布在不同层级以平衡速度和空间。
22. Compact:数据压缩操作,用于清理过期和合并数据。
23. Compaction:数据层间的合并过程,优化存储并减少读取延迟。
leveldb通过这些基本概念和组件协同工作,实现了高效的数据存储和检索。其核心算法包括跳表(用于Memtable)和Bloom Filter(用于减少磁盘查找次数),以及精心设计的压缩策略,确保在保持高吞吐量的同时,最大限度地减少了磁盘空间的使用。在实际应用中,开发者可以根据具体需求调整Option参数,以优化leveldb的性能和存储效率。
4
enum ValueType {
kTypeDeletion = 0x0,
kTypeValue = 0x1
};
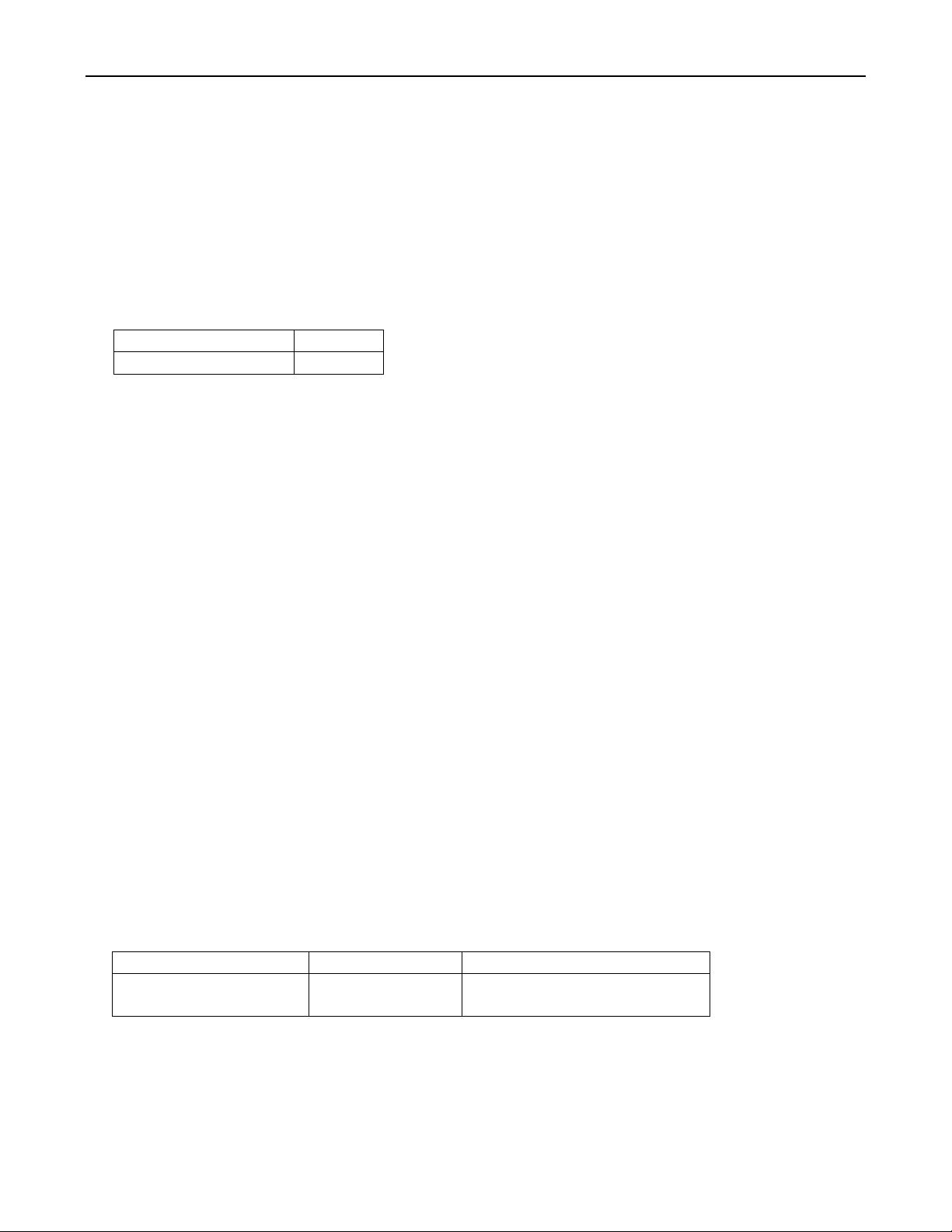
6. SequnceNnumber (db/dbformat.h)
leveldb 中的每次更新(put/delete)操作都拥有一个版本,由 SequnceNumber 来标识,整个 db 有一个
全局值保存着当前使用到的 SequnceNumber。SequnceNumber 在 leveldb 有重要的地位,key 的排序,
compact 以及 snapshot 都依赖于它。
typedef uint64_t SequenceNumber;
存储时,SequnceNumber 只占用 56 bits, ValueType 占用 8 bits,二者共同占用 64bits(uint64_t).
0
56
SequnceNumber
ValueType
7. user key
用户层面传入的 key,使用 Slice 格式。
8. ParsedInternalKey (db/dbformat.h)
db 内部操作的 key。db 内部需要将 user key 加入元信息(ValueType/SequenceNumber)一并做处理。
struct ParsedInternalKey {
Slice user_key;
SequenceNumber sequence;
ValueType type;
};
9. InternalKey (db/dbformat.h)
db 内部,包装易用的结构,包含 userkey 与 SequnceNumber/ValueType。
10. LookupKey (db/dbformat.h)
db 内部在为查找 memtable/sstable 方便,包装使用的 key 结构,保存有 userkey 与
SequnceNumber/ValueType dump 在内存的数据。
class LookupKey {
…
private:
const char* start_;
const char* kstart_;
const char* end_;
};
LookupKey:
start
kstart
end
userkey_len
(varint32)
userkey_data
(userkey_len)
SequnceNumber/ValueType
(uint64)
对 memtable 进行 lookup 时使用 [start,end], 对 sstable lookup 时使用[kstart, end]。
11. Comparator (include/leveldb/comparator.h util/comparator.cc)
对 key 排序时使用的比较方法。leveldb 中 key 为升序。
剩余33页未读,继续阅读
351 浏览量
点击了解资源详情
138 浏览量
128 浏览量
2021-06-14 上传
2021-03-21 上传
120 浏览量
2021-04-04 上传
207 浏览量

vuleetu
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- webacus工具实现自动页面生成与报表导出功能
- 深入理解FAT32文件系统及其数据存储与管理
- 玛纳斯·穆莱全栈Web开发学习与WakaTime统计
- mini翼虎播放器官方安装版:CG视频教程全能播放器
- CoCreate-pickr:轻便的JavaScript选择器组件指南与演示
- 掌握Xdebug 5.6:PHP代码调试与性能追踪
- NLW4节点项目:使用TypeORM和SQLite进行用户ID管理
- 深入了解Linux Bluetooth开源栈bluez源代码解析
- STM32与A7105射频芯片的点对点收发控制实现
- 微信高仿项目实践:FragmentUtil使用与分析
- 官方发布的CG视频教程播放器 mini翼虎x32v2015.7.31.0
- 使用python-lambder自动化AWS Lambda计划任务
- 掌握异步编程:深入学习JavaScript的Ajax和Fetch API
- LTC6803电池管理系统(BMS)经典程序解析
- 酷音传送v2.0.1.4:正版网络音乐平台,歌词同步功能
- Java面向对象编程练习:多态在游戏对战模拟中的应用
