深入理解MapReduce:Google的集群大数据处理模型
需积分: 9 51 浏览量
更新于2024-09-11
收藏 375KB PDF 举报
"这篇文档主要探讨了MapReduce的源码分析以及其实用性和全面性在处理Hadoop大数据集中的应用。MapReduce是一种编程模型,由Google的Jeffrey Dean和Sanjay Ghemawat提出,旨在简化大型集群上的数据处理。它提供了一种方式让用户通过定义Map函数处理键值对生成中间键值对,然后通过Reduce函数合并相同中间键的所有中间值,适合处理各种实际问题。"
MapReduce的核心概念:
1. Map阶段:这是数据处理的第一步,用户定义的Map函数将输入的数据(key-value对)转换为一系列的中间键值对。这个阶段可以并行化执行,使得计算分布在多个节点上。
2. Shuffle阶段:在Map任务完成后,系统会按照中间键对数据进行排序和分区,准备进入Reduce阶段。Shuffle阶段是MapReduce中一个关键的内部机制,确保相同的中间键被聚集到一起。
3. Reduce阶段:Reduce函数负责合并所有具有相同中间键的值,通常用于聚合或总结数据。这个阶段也是并行执行的,不同键的值可以同时处理。
4. 自动并行化:MapReduce程序天生就具备并行处理能力,系统会自动将任务分解并分配到集群中的各个节点上,无需程序员关心具体的并行细节。
5. 容错机制:MapReduce框架能够处理节点故障,如果某个节点失败,任务会被重新调度到其他可用节点,保证作业的完整性。
6. 输入输出:MapReduce允许用户自定义InputFormat和OutputFormat类,以适应各种不同的数据源和输出格式。
7. 应用场景:MapReduce广泛应用于各种大数据处理任务,如网页链接分析、搜索索引构建、日志分析、机器学习等。
源码分析:
在Hadoop实现的MapReduce中,主要涉及以下几个核心类:
- Job:代表一个MapReduce作业,包含了作业的配置信息、输入输出格式等。
- Mapper:实现了Map函数的逻辑,处理输入数据并生成中间结果。
- Reducer:实现了Reduce函数,对Map阶段产生的中间结果进行汇总和处理。
- InputFormat:负责将输入数据分割成适合Map任务处理的记录。
- OutputFormat:负责将Reduce任务的输出写入到指定的存储系统。
通过源码分析,我们可以深入了解MapReduce的执行流程、任务调度策略、容错策略以及数据分发机制,这对于优化MapReduce作业性能和理解大数据处理的底层工作原理至关重要。对于Hadoop开发者来说,掌握MapReduce的源码分析有助于编写更高效、更稳定的分布式应用程序。
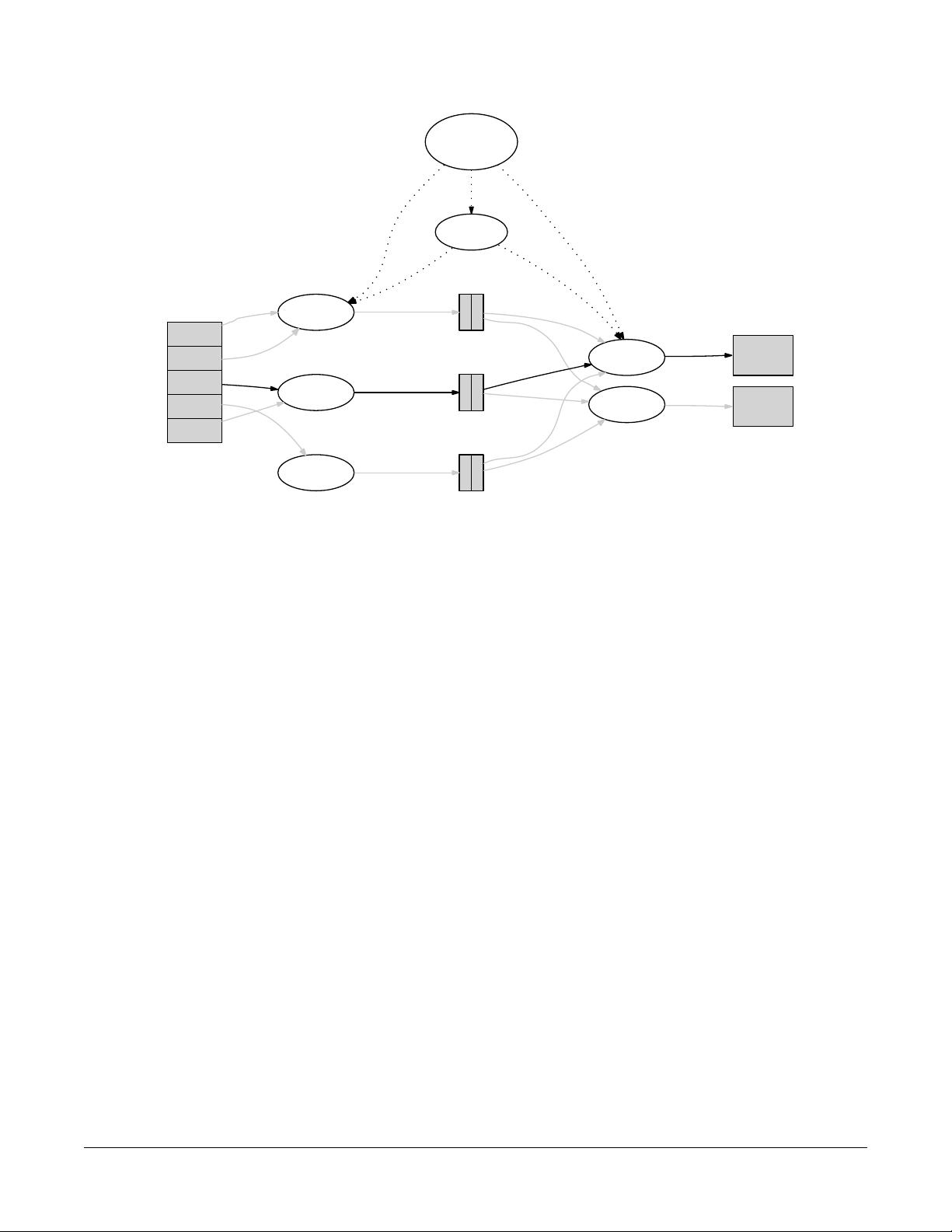
User
Program
Master
(1) fork
worker
(1) fork
worker
(1) fork
(2)
assign
map
(2)
assign
reduce
split 0
split 1
split 2
split 3
split 4
output
file 0
(6) write
worker
(3) read
worker
(4) local write
Map
phase
Intermediate files
(on local disks)
worker
output
file 1
Input
files
(5) remote read
Reduce
phase
Output
files
Figure 1: Execution overview
Inverted Index: The map function parses each docu-
ment, and emits a sequence of hword, document IDi
pairs. The reduce function accepts all pairs for a given
word, sorts the corresponding document IDs and emits a
hword, list(document ID)i pair. The set of all output
pairs forms a simple inverted index. It is easy to augment
this computation to keep track of word positions.
Distributed Sort: The map function extracts the key
from each record, and emits a hkey, recordi pair. The
reduce function emits all pairs unchanged. This compu-
tation depends on the partitioning facilities described in
Section 4.1 and the ordering properties described in Sec-
tion 4.2.
3 Implementation
Many different implementations of the MapReduce in-
terface are possible. The right choice depends on the
environment. For example, one implementation may be
suitable for a small shared-memory machine, another for
a large NUMA multi-processor, and yet another for an
even larger collection of networked machines.
This section describes an implementation targeted
to the computing environment in wide use at Google:
large clusters of commodity PCs connected together with
switched Ethernet [4]. In our environment:
(1) Machines are typically dual-processor x86 processors
running Linux, with 2-4 GB of memory per machine.
(2) Commodity networking hardware is used – typically
either 100 megabits/second or 1 gigabit/second at the
machine level, but averaging considerably less in over-
all bisection bandwidth.
(3) A cluster consists of hundreds or thousands of ma-
chines, and therefore machine failures are common.
(4) Storage is provided by inexpensive IDE disks at-
tached directly to individual machines. A distributed file
system [8] developed in-house is used to manage the data
stored on these disks. The file system uses replication to
provide availability and reliability on top of unreliable
hardware.
(5) Users submit jobs to a scheduling system. Each job
consists of a set of tasks, and is mapped by the scheduler
to a set of available machines within a cluster.
3.1 Execution Overview
The Map invocations are distributed across multiple
machines by automatically partitioning the input data
OSDI ’04: 6th Symposium on Operating Systems Design and ImplementationUSENIX Association
139
剩余12页未读,继续阅读
2023-06-13 上传
2024-10-26 上传
2023-07-13 上传
2023-05-13 上传
2024-10-26 上传
2023-08-31 上传
2024-06-19 上传

zrjnike
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
