HBase与Hive整合:性能对比与查询优化
需积分: 0 158 浏览量
更新于2024-08-04
收藏 319KB DOCX 举报
"本文探讨了HBase与Hive的整合,以及Hive在HDFS和HBase上的查询效率对比。文章提供了三个查询示例,并分析了不同情况下的性能表现。此外,还简要介绍了Hive over HBase的工作原理,强调了HBaseStorageHandler在整合中的作用。"
在大数据处理领域,HBase和Hive分别扮演着不同的角色。HBase是一个分布式的、面向列的NoSQL数据库,适合实时查询和大数据量存储,尤其在数据有序(例如通过RowKey排序)的情况下表现出色。而Hive则是一个基于Hadoop的数据仓库工具,用于结构化或半结构化数据的ETL(提取、转换、加载)以及数据分析,更适合批处理查询。
在查询性能方面,文章提到了三个查询示例:
1. 全表扫描:当执行无条件的全表查询时,如`select count(1) from on_hdfs`和`select count(1) from on_hbase`,Hive on HDFS的性能优于Hive on HBase,尤其是在未设置缓存(caching)的情况下。这是因为HDFS上的Hive可以直接对整个文件进行并行处理,而HBase需要通过MapReduce逐个Region扫描,增加了额外的开销。
2. 根据RowKey过滤:当查询条件基于RowKey时,如`select * from on_hdfs where key='13400000064_1388056783_460095106148962'`和`select * from on_hbase where key='13400000064_1388056783_460095106148962'`,Hive on HBase的表现优于Hive on HDFS,尤其是在数据量较大时。这是由于HBase的RowKey设计使得数据存储有序,有利于快速定位和过滤。
3. 根据value过滤:当查询条件基于value时,Hive on HDFS和Hive on HBase的性能差异取决于具体的数据分布和查询优化。在测试中,Hive on HBase未显示出明显优势,可能因为HBase的索引主要基于RowKey,对value的过滤需要扫描更多数据。
Hive over HBase的整合主要依赖于HBaseStorageHandler,它是一个接口,允许Hive理解如何与HBase交互。通过这个接口,Hive可以获取到HBase表的相关信息,如表名、列簇、列、InputFormat和OutputFormat,以及执行创建和删除HBase表的操作。在查询过程中,Hive会启动一个MapReduce任务,其中HBaseHBaseTableInputFormat负责将HBase的Region拆分为多个Split,每个Split对应一个Map任务,然后RecordReader读取这些Splits中的数据。
在实际应用中,为了提高查询效率,可以通过调整HBase的RowKey设计,使其在HBase的Region划分上更加均匀,减少热点现象。同时,合理设置Hive查询的caching参数,可以缓存扫描结果,减少对HBase的多次访问,从而提升性能。
HBase和Hive各有优势,选择哪种方案取决于应用场景。如果需要实时查询和高效的数据过滤,HBase可能是更好的选择;而在进行大规模批处理和复杂分析时,Hive则更有优势。合理地结合两者,可以实现更高效的大数据处理。
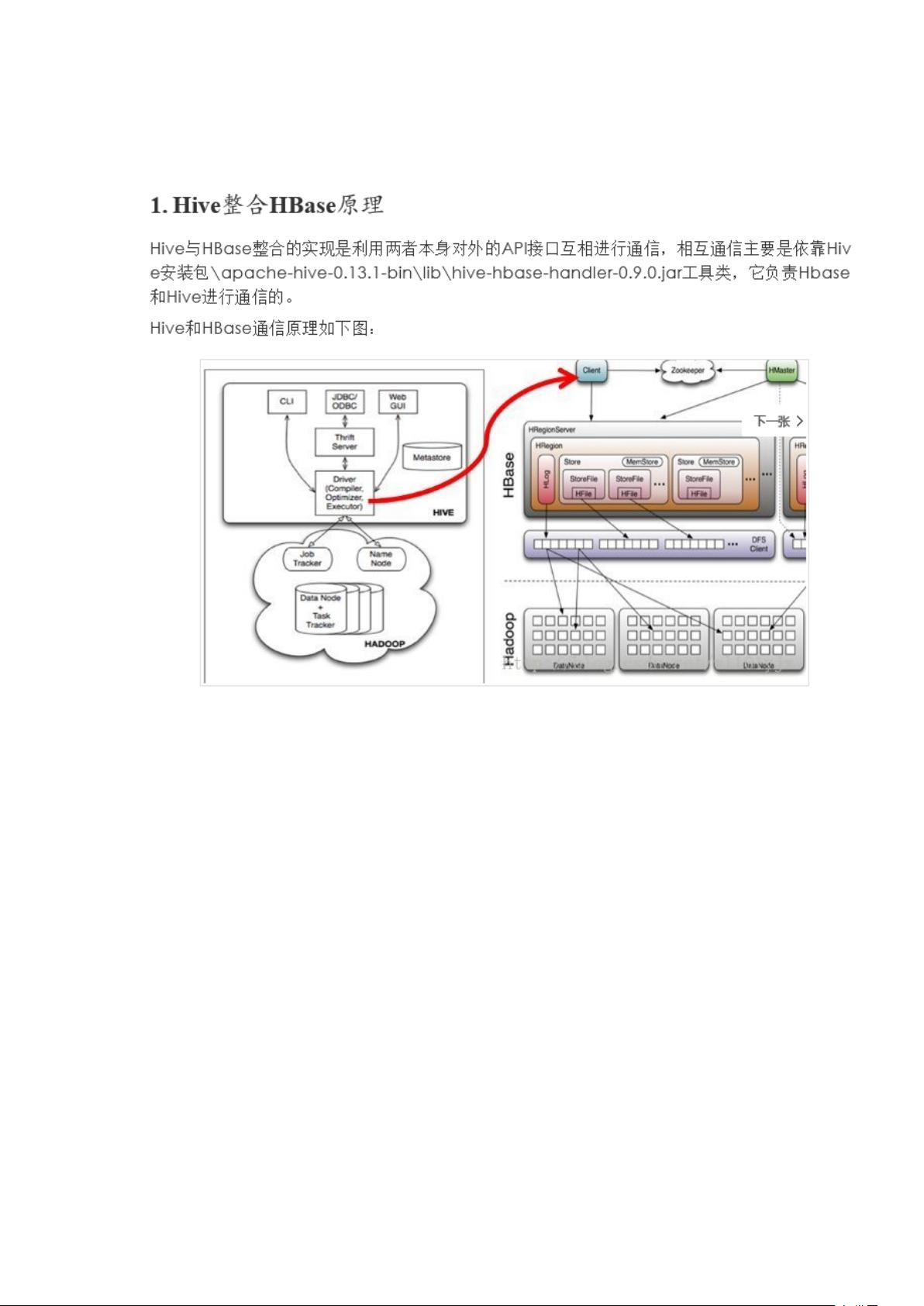
Hive 与 Hbase 结合的原理
一、查询性能比较:
query1:
select count(1) from on_hdfs;
select count(1) from on_hbase;
query2(根据 key 过滤)
select * from on_hdfs
where key = ‘13400000064_1388056783_460095106148962′;
select * from on_hbase
where key = ‘13400000064_1388056783_460095106148962′;
query3(根据 value 过滤)
select * from on_hdfs where value = ‘XXX';
select * from on_hbase where value = ‘XXX';
on_hdfs (20 万记录,150M,TextFile on HDFS)
on_hbase(20 万记录,160M,HFile on HDFS)
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-09-14 上传
2021-07-04 上传
2022-08-08 上传
2014-10-12 上传
300 浏览量
点击了解资源详情

一曲歌长安
- 粉丝: 870
- 资源: 302
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
