大数据压缩算法在Hadoop中的应用探析
需积分: 10 35 浏览量
更新于2024-09-09
收藏 342KB PDF 举报
"这篇文章是关于Hadoop压缩算法的调查研究,作者Sampada Lovalekar来自印度SIES Graduate School of Technology。随着大数据在信息技术领域的热度不断上升,处理大量结构化、非结构化或半结构化数据成为当前挑战。由于互联网、智能手机、社交媒体、GPS设备等的普及,数据量急剧增长,传统数据仓库系统难以应对。文章指出,面对如此庞大的数据,使用压缩技术可以带来显著的优势。"
在Hadoop生态系统中,数据压缩是一个关键的优化策略,它有助于减少存储需求,提高数据传输效率,并最终提升整体性能。Hadoop是处理大数据的主要平台,其核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。压缩在Hadoop中的应用主要体现在以下几个方面:
1. **数据存储优化**:通过对数据进行压缩,HDFS可以存储更多的数据在相同的磁盘空间上,降低了存储成本。此外,压缩还可以帮助防止磁盘碎片,提高读取速度。
2. **网络传输优化**:在Hadoop集群中,数据经常需要在节点间移动。压缩数据可以减少在网络中传输的数据量,降低带宽消耗,从而加快数据传输速度。
3. **MapReduce性能提升**:在MapReduce作业中,输入数据通常会被解压后再处理。选择合适的压缩算法可以平衡解压时间和处理时间,整体提升作业性能。
Hadoop支持多种压缩算法,包括:
- **Gzip**:是一种广泛使用的通用压缩算法,压缩率高但压缩和解压缩速度较慢。
- **LZO**:提供较快的压缩和解压缩速度,但压缩率较低,适用于对速度有较高要求的场景。
- **BZip2**:提供比Gzip更高的压缩率,但速度更慢,适合长时间运行的批处理作业。
- **Snappy**:由Google开发,专为Hadoop设计,提供了较高的压缩速度和解压缩速度,适合实时处理和MapReduce作业。
选择合适的压缩算法需要考虑多个因素,包括数据特性、处理需求和硬件资源。例如,对于需要快速处理的实时流数据,可能更适合使用Snappy;而对于存储空间有限且不急于处理的批量数据,BZip2可能是更好的选择。
此外,Hadoop还支持压缩配置的灵活性,用户可以根据具体需求调整压缩级别,平衡压缩效率和压缩率。同时,Hadoop允许数据以压缩或未压缩的形式存储,这为处理不同类型的作业提供了灵活性。
理解并有效地利用Hadoop中的数据压缩技术,对于优化大数据处理的效率和成本至关重要。通过深入研究各种压缩算法的优缺点,开发者和数据工程师能够更好地应对大数据带来的挑战,实现高效的数据处理和分析。
International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169
Volume: 2 Issue: 3 479 – 482
______________________________________________________________________________________________
479
IJRITCC | March 2014, Available @ http://www.ijritcc.org
_______________________________________________________________________________________________
A Survey on Compression Algorithms in Hadoop
Sampada Lovalekar
Department of IT
SIES Graduate School of Technology
Nerul, Navi Mumbai, India
sampada.lovalekar@gmail.com
Abstract—Now a days, big data is hot term in IT. It contains large volume of data. This data may be structured, unstructured or semi structured.
Each big data source has different characteristics like frequency, volume, velocity and veracity of the data. Reasons of growth in the
volume is use of internet, smart phone ,social networks, GPS devices and so on. However, analyzing big data is a very challenging problem today.
Traditional data warehouse systems are not able to handle this large amount of data. As the size is very large, compression will surely add the benefit
to store this large size of data. This paper explains various compression techniques in hadoop.
Keywords-bzip2, gzip ,lzo, lz4 ,snappy
______________________________________________________*****___________________________________________________
I. INTRODUCTION
The volume of big data is growing day by day because of use
of smart phones, internet, sensor devices etc. The three key
characteristics of big data are volume, variety and value. Volume
can be described as the large quantity of data generated because
of use of technologies now a day. Big data comes in different
formats like audio, video, image etc. This is variety. Data is
generated in real time with demands for usable information to be
served up as needed. Value is the value of that data whether it is
more or less important.
Big data is used in many sectors like healthcare, banking,
insurance and so on. The amount of data is increasing day by
day. Big data sizes vary from a few dozen terabytes to many
petabytes of data.
Big data doesn’t only bring new data types and storage
mechanisms, but new types of analysis as well. Data is growing
too fast. New data types are added. Processing and managing
big data is a challenge in today’s era. With traditional methods
for big data storage and analysis is less efficient. So, there is
difference between analytics of traditional data and big data.
The challenges comes with big data are data privacy and
security, data storage, creating business value from the large
amount of data etc. Data is growing too fast. Following points
should be considered [1].
In 2011 alone, mankind created over 1.2 trillion GB of
data.
Data volumes are expected to grow 50 times by 2020.
Google receives over 2,000,000 search queries every
minute.
72 hours of video are added to YouTube every minute.
There are 217 new mobile Internet users every minute.
571 new websites are created every minute of the day.
According to Twitter’s own research in early 2012, it
sees roughly 175 million tweets every day, and has more
than 465 million accounts.
As the size of big data is growing, compression is must. These
large amounts of data need to be compressed. The advantages of
compression are [2]:
Compressed data uses less bandwidth on the network
than uncompressed data.
Compressed data uses less disk space.
Speed up the data transfer across the network to or from
disk.
Cost is reduced.
II. BIG DATA TECHNOLOGIES
Hadoop is an open source framework for processing, storing,
and analyzing massive amounts of distributed unstructured data.
Hadoop has two main components. These are:
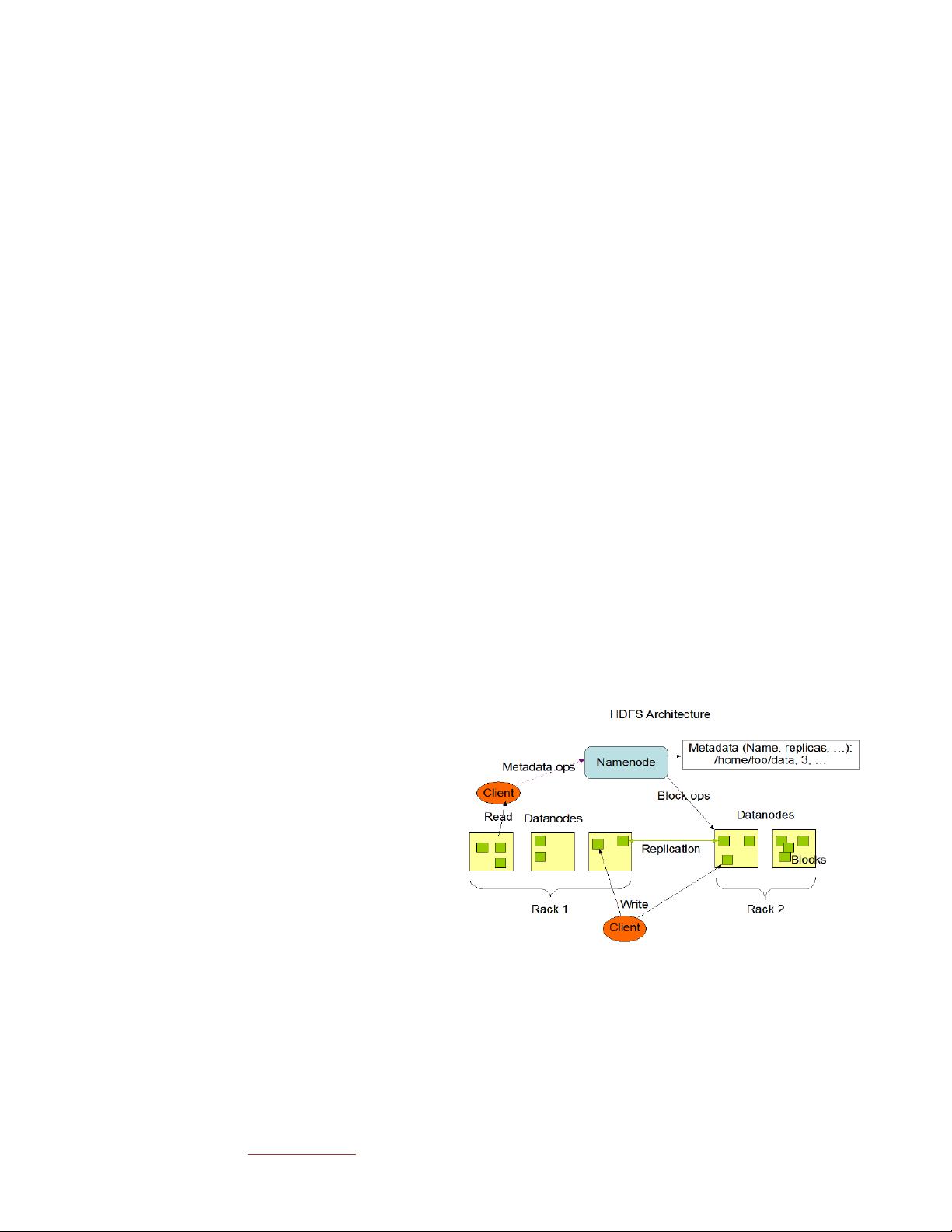
Figure 1. HDFS architecture
A HDFS: Hadoop Distributed File System
The Hadoop Distributed File System (HDFS) is a distributed file
system designed to store very large data sets , and to stream those
data sets at high bandwidth to user applications.
下载后可阅读完整内容,剩余3页未读,立即下载
2014-06-29 上传
2022-07-14 上传
2021-02-06 上传
2014-06-23 上传
2021-04-25 上传
2021-12-09 上传
2021-04-23 上传
2023-06-09 上传
2011-09-24 上传

renzhewh
- 粉丝: 39
- 资源: 100
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
