Hadoop之LLAP:亚秒级Hive分析查询
需积分: 5 74 浏览量
更新于2024-06-21
收藏 2.62MB PDF 举报
“藏经阁-LLAP_ Sub-Second Analytical Queries in Hive.pdf”是关于阿里云中LLAP(Live Long and Process)技术在Hive中的应用,旨在提供亚秒级的分析查询性能。
为什么需要LLAP?
1. 用户喜欢使用Hive:Hive作为一个大数据处理的流行工具,深受用户喜爱,但随着数据量的增长和云存储的普及,传统的磁盘到内存的数据处理方式逐渐变得效率低下。
2. 存储与计算分离:云存储通常不在本地,数据通过网络连接到CPU,这增加了延迟。
3. 安全性需求变化:数据安全边界从文件转向单元格和列,需要一个过程边界来安全地屏蔽列数据。
4. 并发、性能和扩展性的冲突:在每小时处理10万查询的高并发需求下,保持2-5秒的查询延迟,并且需要处理PB级别的数据仓库(其中包含TB级别的热数据),传统方式面临挑战。
什么是LLAP?
1. 混合模型:LLAP结合了守护进程和容器,以快速并行执行分析工作负载,如Hive SQL查询。
2. 无需特殊YARN队列的并发查询:LLAP允许在不设置特殊资源调度队列的情况下实现高并发查询。
3. 多线程执行向量化操作管道:提高运算效率,加快处理速度。
4. 异步IO和高效内存缓存:利用异步I/O技术减少等待时间,同时通过内存缓存提升数据读取速度。
5. 通过API提供关系型数据视图:允许开发者和用户以更灵活的方式访问和操作数据。
LLAP的优势:
- 提升性能:通过内存缓存和多线程处理,LLAP可以显著减少分析查询的延迟,达到亚秒级响应。
- 简化并发管理:无需专门的YARN队列设置,简化了资源管理和调度。
- 改善安全性:适应新的安全环境,支持基于单元格和列的安全策略。
- 支持大规模数据处理:在处理PB级别的大数据仓库时,仍然能保持良好的性能表现。
总结来说,LLAP是阿里云为了应对大数据分析的性能、并发、安全和扩展性挑战而推出的技术,它通过优化内存管理、并发执行和安全机制,实现了Hive在处理大规模数据时的高性能亚秒级查询,同时降低了运维复杂性。

Page 6
© Hortonworks Inc. 2011 – 2016. All Rights Reserved
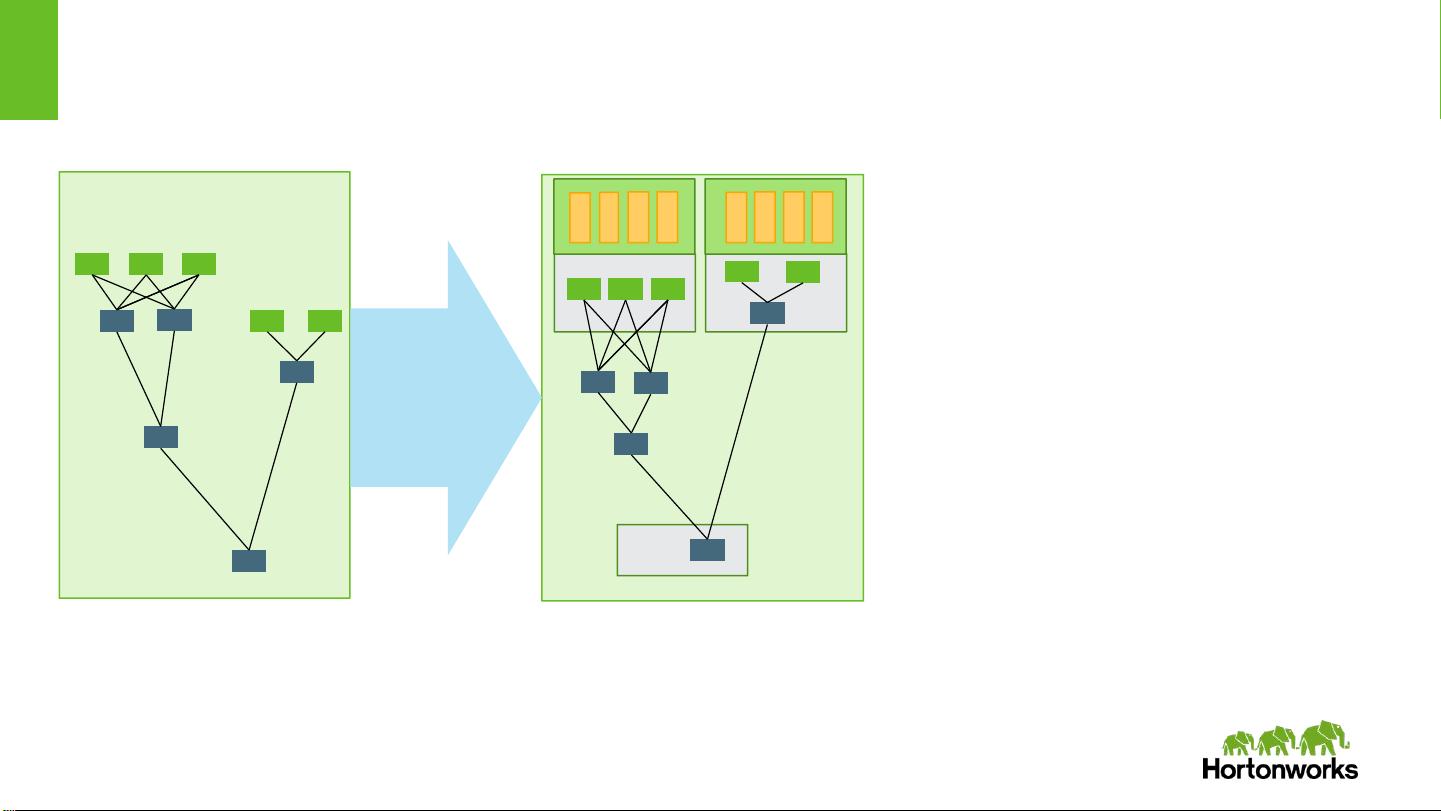
So…
M M M
R
R
R
M M
R
R
Tez
剩余31页未读,继续阅读
905 浏览量
2023-08-30 上传
2023-05-01 上传
184 浏览量
148 浏览量
106 浏览量
133 浏览量
380 浏览量
320 浏览量

weixin_40191861_zj
- 粉丝: 87
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







