联邦学习:隐私保护与技术进展探究
需积分: 0 180 浏览量
更新于2024-06-30
收藏 1.88MB PDF 举报
"联邦学习隐私保护研究进展"
随着全球对隐私保护的法律法规的不断出台,数据孤岛问题日益凸显,成为大数据和人工智能领域发展的一大障碍。联邦学习作为一种隐私计算技术,因其独特的特性而受到广泛关注。联邦学习允许在不直接共享数据的情况下进行分布式协作,从而在保护个人隐私的同时推进模型训练和智能服务的发展。
联邦学习的历史发展可以追溯到分布式机器学习的早期阶段,它逐渐演化为一种更加注重隐私和数据主权的方法。联邦学习的核心概念在于,数据保留在本地设备上,只交换模型参数或梯度信息,而不是原始数据。这分为横向联邦学习、纵向联邦学习和联合多模态联邦学习等不同的架构分类,分别对应于同一类型数据的不同设备间、不同特征的数据集之间以及不同模态数据的联合学习。
联邦学习的技术优势在于其能够有效地处理数据分散问题,减少数据传输和集中存储的风险,同时保持较高的学习效率。然而,联邦学习系统并非完全安全,面临着多种攻击方式,如模型逆向工程、数据泄露和中间人攻击等。因此,对于联邦学习的加密算法选择至关重要,如同态加密、安全多方计算和差分隐私等,它们在保护隐私的同时平衡计算效率和安全性。
近年来,学术界和工业界对联邦学习的隐私保护和安全机制展开了深入研究。差分隐私技术被广泛应用,通过引入随机噪声来模糊个体数据,防止数据泄露。同时,研究人员还探索了动态参与、可信执行环境和区块链等手段来增强联邦学习系统的安全性。
然而,联邦学习在隐私保护方面仍面临诸多挑战,包括如何有效量化和保证隐私水平、如何抵御更复杂的攻击策略、如何在资源受限的设备上实现高效加密计算,以及如何在保证性能的同时满足法规要求。未来的研究应聚焦于这些挑战,以推动联邦学习在实际应用中的普及和深化。
关键词:联邦学习;联邦学习系统攻击;隐私保护;加密算法
这篇研究综述详细探讨了联邦学习的历史、架构、技术优势、潜在威胁和隐私保护策略,为该领域的研究提供了全面的视角,并指出了未来可能的研究方向。通过不断改进和优化,联邦学习有望在保障隐私的前提下推动大数据和人工智能技术的持续发展。
STUDY 研究 133
中的参与方通过获取联合建模的模型,达
到提升本地模型的效果的目的。
2.3 联邦学习架构
本节将介绍联邦学习系统的基础架
构。由于不同的联邦学习任务具有不同的
学习场景,因此联邦学习架构的设计也是
不 同 的 。从 这 些 复 杂 架 构 中 ,笔 者 总 结 出 以
下 两 种 基 础 的 架 构 模 式 。一 种 是 服 务 器 客
户端架构,另一种是端对端架构。根据联
邦 学 习 应 用 场 景 的 复 杂 度 、安 全 需 求 ,笔
者将采用不同的架构。同时,当应用场景特
别复杂时,笔者可以根据需求将这两种基
础的联邦学习架构进行拼接组合,从而形
成一种混合的联邦学习架构。
在 很 多 横 向 联 邦 学 习 应 用 场 景 中 ,参
与训练的参与方数据具有类似的数据结构
(特征空间),但是每个参与方拥有的用
户是不相同的。有时参与方比较少,例如,
银行系统在不同地区的两个分行需要实现
联邦学习的联合模型训练;有时参与方会
非 常 多 ,例 如 ,做 一 个 基 于 手 机 模 型 的 智 能
系统,每一个手机的拥有者将会是一个独
立的参与方。针对这类联合建模需求,可以
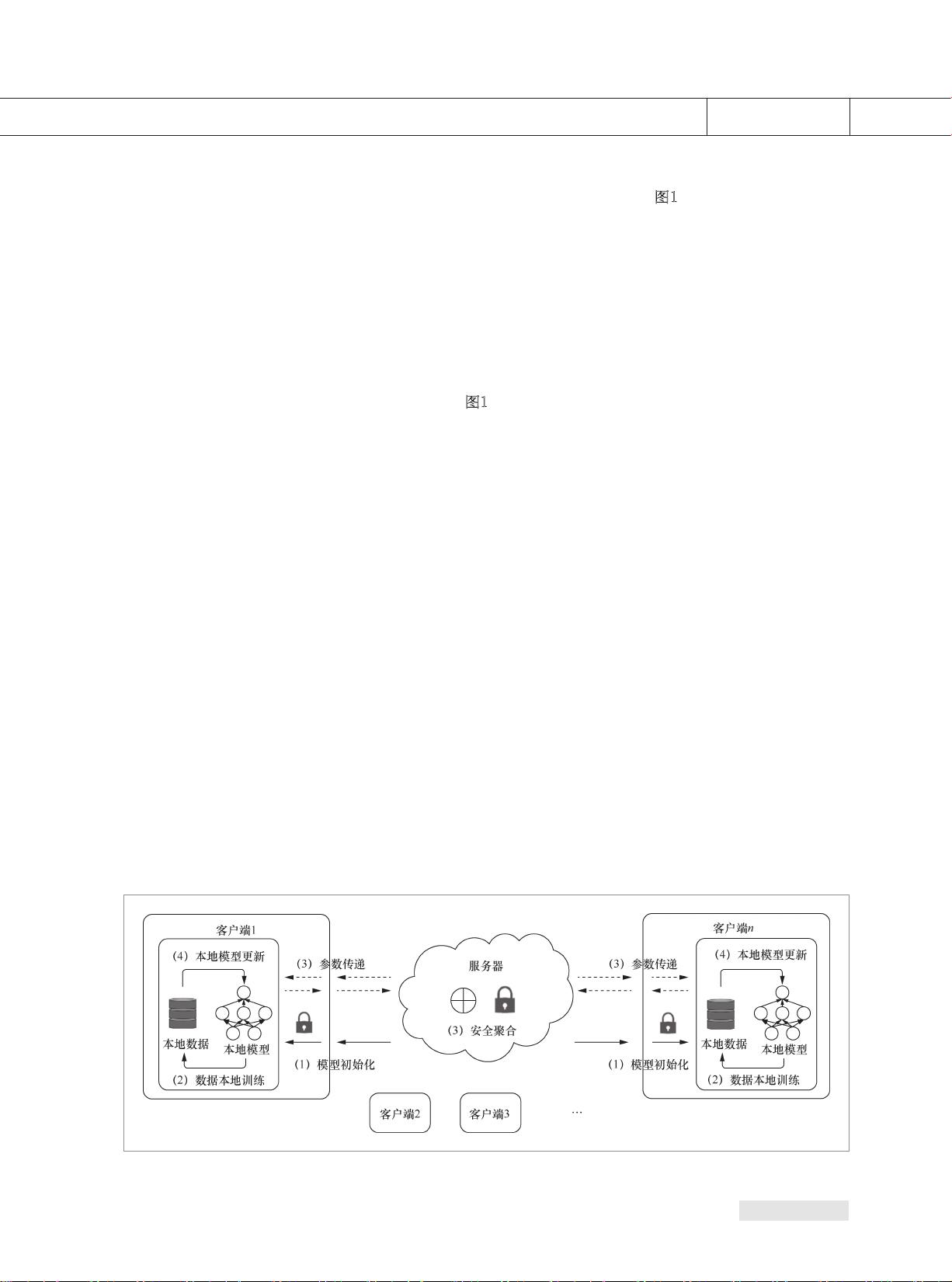
通过一种基于服务器客户端的架构来满足
很多横向联邦学习的需求,如
图1所 示 。将
每一个参与方看作一个客户端,然后引入一
个大家信任的服务器来帮助完成联邦学习
的联合建模需求。在联合训练的过程中,被
训练的数据将会被保存在每一个客户端本
地,同时,所有的客户端可以一起参与训练
一个共享的全局模型,最终所有的客户端
可以一起享用联合训练完成的全局模型。
如
图1所示,云服务器作为中心的服务器进
行联合训练模型参数的聚合,每一个参与
方作为客户端通过与服务器之间进行参数
传递来参与联合训练。服务器客户端架构
的联 合 训 练的 过 程 如下。
步 骤 1 :中 心 服 务 器 初 始 化 联 合 训 练
模型,并且将初始参数传递给每一个客
户端。
步 骤 2 :客 户 端 用 本 地 数 据 和 收 到 的 初
始化模型参数进行模型训练。具体步骤包
括 :计 算 训 练 梯 度 ,使 用 加 密 、差 异 隐 私 等
加密技术掩饰所选梯度,并将加密后的结
果发送到服务器。
步骤3:服务器执行安全聚合。服务器
只 收 到 加 密 的 模 型 参 数 ,不 会 了 解 任 何 客
户 端 的 数 据 信 息 ,实 现 隐 私 保 护 。服 务 器
将安全聚合后的结果发送给客户端。
步骤4:参与方用解密的梯度信息更新
图 1 服务器客户端架构
2021030-4
剩余19页未读,继续阅读
2020-08-08 上传
2021-01-08 上传
2022-08-04 上传
点击了解资源详情
2022-08-03 上传
2021-08-08 上传
2015-05-16 上传
点击了解资源详情
点击了解资源详情

王元祺
- 粉丝: 848
- 资源: 303
 我的内容管理
展开
我的内容管理
展开







最新资源
- 语音清浊音分类及浊音谐波提取算法_三阶累积量基于正弦语音模型的应用.pdf
- 有源电力滤波器中谐波提取的数字法实现.pdf
- 谐波提取理论的实践.pdf
- 基于谐波恢复方法的直升机声信号特征提取.pdf
- ASP.NET程序设计基础篇.pdf
- ASP.NET_XML深入编程技术.pdf
- 试采用FFT方法实现加速度_速度与位移的相互转换.pdf
- eclipse开发教程得到 的点点滴滴
- DWR中文文档.pdf
- 一种基于DNS和第七层交换的CDN实现方案
- keepalived the definitive guide权威指南
- 数据库原理课后答案(自考).doc
- 图书管理系统毕业论文
- 数字信号处理课程设计+matlab滤波器设计
- 基于提升方案小波和混沌映射的盲水印算法
- 基于快速提升小波变换与人眼视觉特性的数字水印算法
