XLNet深度解析:重构双向上下文的自回归模型
需积分: 9 167 浏览量
更新于2024-07-15
收藏 3.06MB PDF 举报
"XLNet在NeurIPS大会上的演讲PPT"
XLNet是由Zhilin Yang、Zihang Dai等研究人员提出的,与BERT一样,它是一种预训练语言模型,旨在通过捕获双向上下文来改进自然语言处理任务的表现。这篇PPT在NeurIPS大会上进行了介绍,展示了XLNet在语言建模领域的创新之处。
在语言预训练领域,早期的研究包括受限玻尔兹曼机(RBMs)、自编码器(Autoencoders)、Jigsaw、生成对抗网络(GANs)等,以及词嵌入模型如word2vec和GloVe。这些模型主要关注无监督学习或半监督学习,通过训练词级别的表示来捕捉词汇的语义信息。随着研究的发展,出现了序列学习方法,如Semi-supervised sequence learning,以及基于Transformer的模型,如ELMo、CoVe和GPT,直至BERT的出现,预训练模型开始聚焦于利用上下文信息进行下一个词的预测或者重建被遮罩的词。
BERT(Bidirectional Encoder Representations from Transformers)是预训练的里程碑,它通过掩码语言模型(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP)实现了双向上下文的理解。然而,BERT的预训练任务——MLM,由于遮罩操作,使得模型在预测时无法看到被遮罩词的右侧上下文,这限制了其对完整上下文的理解。
XLNet则引入了一种新的预训练目标,即自回归语言建模(Auto-regressive Language Modeling),通过Transformer架构的变体,称为Transformer-XL,克服了BERT的这一局限。与BERT的掩码语言模型不同,XLNet采用“Permutation Language Modeling”策略,允许模型在整个序列中查看所有词的上下文,从而实现真正的双向依赖建模。这种方法在训练过程中人为地打乱序列,然后预测每个位置的词,根据之前的位置信息进行预测,确保了对整个序列的完整理解。
此外,XLNet还结合了自编码器的思想,即通过解码器恢复被噪声(例如随机替换或删除的词)污染的输入序列,即去噪自编码(Denoising Auto-encoding)。这进一步增强了模型对文本中的异常情况的鲁棒性。
在实际应用中,XLNet的双向上下文理解能力使其在多项自然语言处理任务上超越了BERT,包括问答、情感分析、文本分类等。通过这种方式,XLNet为NLP领域的研究和实践开辟了新的道路,推动了预训练模型的持续发展和优化。
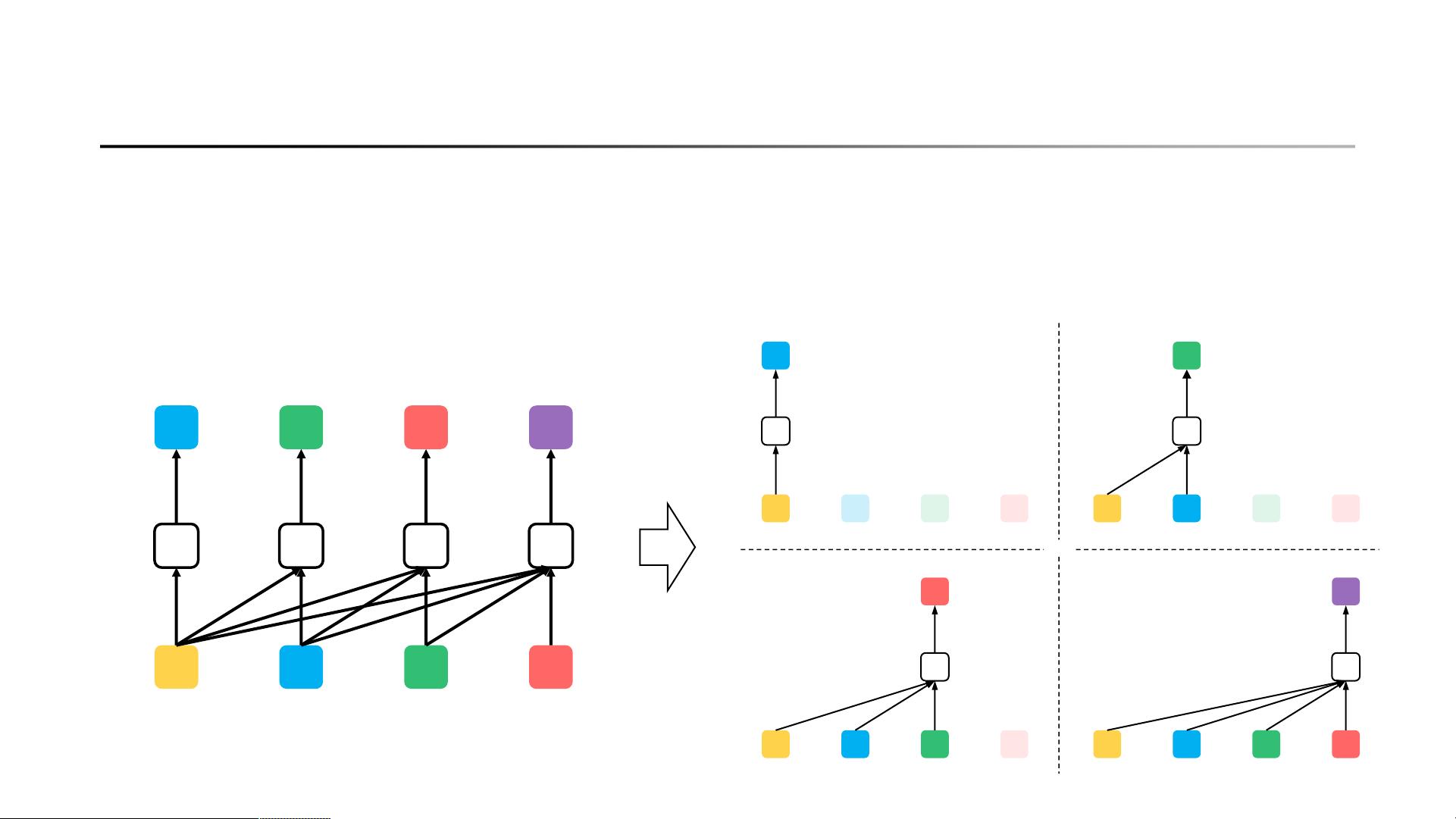
Context Depends on the Factorization Order
• Standard LM: Left-to-right factorization 1 à 2 à 3 à 4
x
"
x
#
x
$
x
%
x
$
h
#
x
%
h
$
x
"
h
%
x
'
h
"
x
"
x
#
x
$
x
%
x
"
h
%
x
"
x
#
x
$
x
%
x
%
h
$
x
"
x
#
x
$
x
%
x
'
h
"
x
#
x
$
h
#
x
"
x
$
x
%
P (x)=P (x
1
)P (x
2
| x
1
)P (x
3
| x
1,2
)P (x
4
| x
1,2,3
) ···
<latexit sha1_base64="iguYDnRJZZo4nxCTpLhGh1YJXYk=">AAACX3icbZHNS8MwGMbT+jGdX1VP4iU4hA3GaDdFL8LQi8cJbgprKWmaaljSliQVR9k/6U3w4n9i2hXUbS+EPDy/vOTNkyBlVCrb/jTMtfWNzdrWdn1nd2//wDo8GskkE5gMccIS8RwgSRiNyVBRxchzKgjiASNPweSu4E9vREiaxI9qmhKPo5eYRhQjpS3fehs0XY7UaxDl77MWvIGD5rvvtMqtC11OQ/jL/dyZzVFvBWp3K3ixErZ7Grs4TJSs132rYXfssuCycCrRAFUNfOvDDROccRIrzJCUY8dOlZcjoShmZFZ3M0lShCfohYy1jBEn0svLfGbwXDshjBKhV6xg6f7tyBGXcsoDfbKYWS6ywlzFxpmKrr2cxmmmSIznF0UZgyqBRdgwpIJgxaZaICyonhXiVyQQVvpLihCcxScvi1G34/Q6lw8Xjf5tFccWOAVnoAkccAX64B4MwBBg8GWYxo6xa3ybNXPftOZHTaPqOQb/yjz5AfWXsVc=</latexit>
7

剩余46页未读,继续阅读
228 浏览量
163 浏览量
2310 浏览量
2022-08-03 上传
105 浏览量
197 浏览量

_Focus_
- 粉丝: 1135
- 资源: 441
 我的内容管理
展开
我的内容管理
展开







最新资源
- matlab代码sqrt-M_matrix:使用类似Matlab的脚本语言与您的Fortran程序进行交互
- stellaris-wandering-leviathans:Stellaris的流浪Leviathans mod,可通过命令进行自定义
- 反应罐控制程序200.rar
- rgb 和 yuv_nv12 数据相互转换
- mints-sensordata-to-postgres-后端:将校准后的传感器数据读入postgres
- 维控 Plc加密 软件.rar
- northernrocketrywebsite
- estudo_angular_4_native_script_rails_api:Angular 4 + NativeScript e Api em Rails 5的列表列表
- matlab代码sqrt-UTM_Heat:用于数字实现统一变换方法(UTM)的代码,以多层求解热方程
- Titanic
- ios开发438个实例源码大全.rar
- 投资分析
- 维控LEVISTUDIO人机界面画面制作软件.zip
- WACOM数位板BAMBOO CTH-470驱动程序 官方最新版
- scss-storybook-quickstarter
- matlab代码sqrt-pnla:多项式数值线性代数
