"梯度下降与牛顿法解决机器学习问题的实现和优化方法"
需积分: 0 12 浏览量
更新于2024-02-01
收藏 480KB PDF 举报
在机器学习第四次作业中,我使用了梯度下降法和牛顿法来解决最小化成本函数的问题。具体来说,我首先尝试了随机梯度下降法,每次只更新一个变量,并进行了1000次迭代。接着,我使用了牛顿法来进行优化。
在使用梯度下降法求解之前,我进行了归一化处理。归一化能够加快收敛速度,保证能够收敛。具体地,我对输入数据进行了标准化处理,将每个特征的值减去该特征的最小值,然后除以该特征的最大值与最小值的差。这样做可以将特征值缩放到0到1之间,并且保持了特征之间的相对关系。
在进行梯度下降法优化之前,我还给成本函数增加了正则化项,以解决过拟合的问题。正则化项使得模型在不影响过拟合的情况下能更好地拟合训练数据。具体地,我对成本函数进行了改进,将方差正则项添加到了成本函数中。这样做可以使得模型在拟合数据的同时,尽量减小参数的大小。
在进行梯度下降法优化时,我对theta0不进行惩罚。这是因为theta0是偏置项,对应于特征x0的系数,它和其他特征的系数有所不同。不对theta0进行惩罚可以使得模型更好地拟合训练数据。
在梯度下降法的优化过程中,我使用了一个成本函数J来衡量模型预测和实际标签之间的差异。其中,m表示训练样本的数量,h表示模型的预测函数,x表示特征向量,和表示实际标签。成本函数可以用来评估模型的准确性。我通过最小化成本函数来调整模型的参数,使得模型能够更好地拟合训练数据。
接着,我尝试了使用牛顿法来进行优化。牛顿法是一种使用二阶导数信息的优化算法。具体地,我对成本函数求导,并使用二阶导数来更新模型的参数。牛顿法的优势在于它能够更快地收敛,并且在某些情况下可以达到较小的误差。
总体来说,通过在梯度下降法中加入正则化项和进行归一化处理,我成功地解决了过拟合和收敛速度的问题。并且,通过尝试不同的优化算法,我找到了最合适的算法来优化模型的参数。在实验中,我发现牛顿法能够更快地收敛,但是在多维情况下,计算二阶导数可能会变得复杂和昂贵。因此,在实际应用中,需要根据具体情况选择最合适的优化算法。
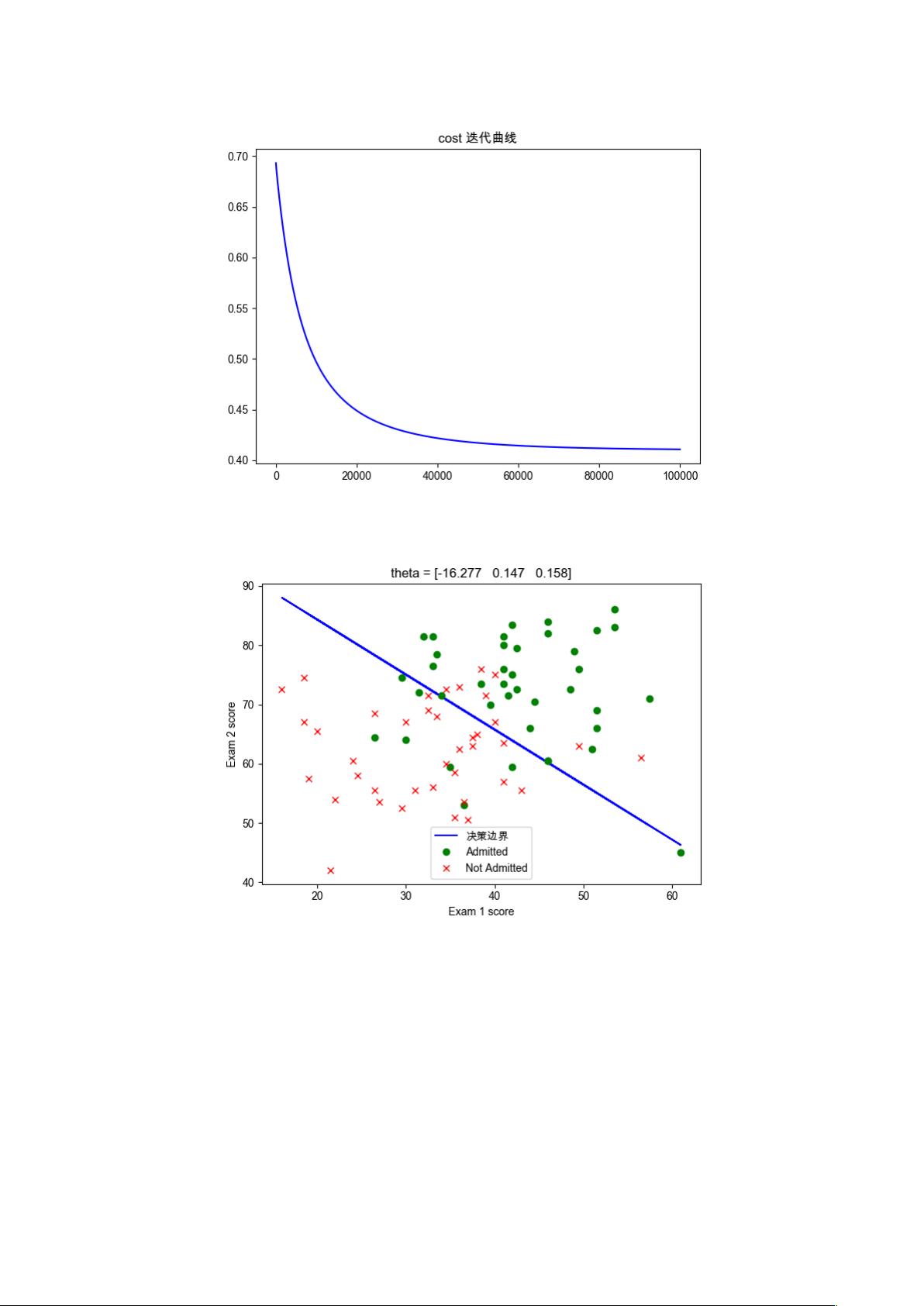
图表 2 迭代 1e5 次结果
图表 3 迭代 1e6 次结果
剩余23页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2022-08-03 上传
2022-08-04 上传
2022-08-03 上传
2022-08-08 上传
2022-08-08 上传

马克love
- 粉丝: 40
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
