编译原理驱动的计算器设计详解与关键实现
版权申诉
160 浏览量
更新于2024-07-02
收藏 268KB DOC 举报
本文档主要探讨了基于编译原理的计算器设计与实现,通过一个简化版的计算器功能来展示编译原理在实际应用中的关键步骤。计算器的主要功能包括设置变量、计算表达式和退出,其中编译的核心部分在于计算表达式的解析。
在词法分析阶段,将输入的表达式文本转换成一系列词法元素,即tokenList,这是将自然语言转换为计算机可理解形式的第一步。例如,表达式"10+pow(b,c)"会被分解成一个个单独的符号,如数字、运算符等。
语法分析是将tokenList转化为抽象语法树(syntaxTree),这一步是理解表达式结构的关键,它展示了各个部分如何按照语法规则组合。例如,加法运算符连接两个子表达式,形成一个计算节点。
语义分析是将语法树进一步转化为汇编语言(ASM)的代码,这是为了能够直接在计算机硬件层面执行。在这个阶段,会将计算逻辑转化为具体的机器级指令,如存储数值、加法、减法等操作。
汇编器和虚拟机是文档中特意强调的部分。通常,编译器会直接从中间代码生成机器码,但在本文中,作者选择生成汇编代码以便于调试,因为汇编代码比机器码更易于理解和修改。此外,由于现有的机器指令可能没有直接支持某些高级数学运算(如幂和平方根),作者决定自定义虚拟机,以便设计专用的计算指令,从而简化整体程序设计。
尽管汇编器和虚拟机不是编译原理的基础组成部分,但它们对于实现这个特定计算器至关重要。汇编指令如"store"用于存储数值,"add"和"sub"进行基本的算术运算,这些构成了计算器核心的计算逻辑。
本文详细介绍了如何运用编译原理的各个步骤,包括词法分析、语法分析、语义分析以及汇编器和虚拟机的设计,来构建一个具有基础计算功能的计算器,同时也强调了在特定情况下选择生成汇编代码和自定义虚拟机的原因。这个计算器虽然规模较小,但它展示了编译原理在实际项目中的实用性,特别是当需要处理复杂计算逻辑时。
字符串,在处理之后,我们按照一定的“规则”分解为多个单词。
算法是多种多样的,有创造力的程序员会想出各种办法来处理这个单词分解的问题。
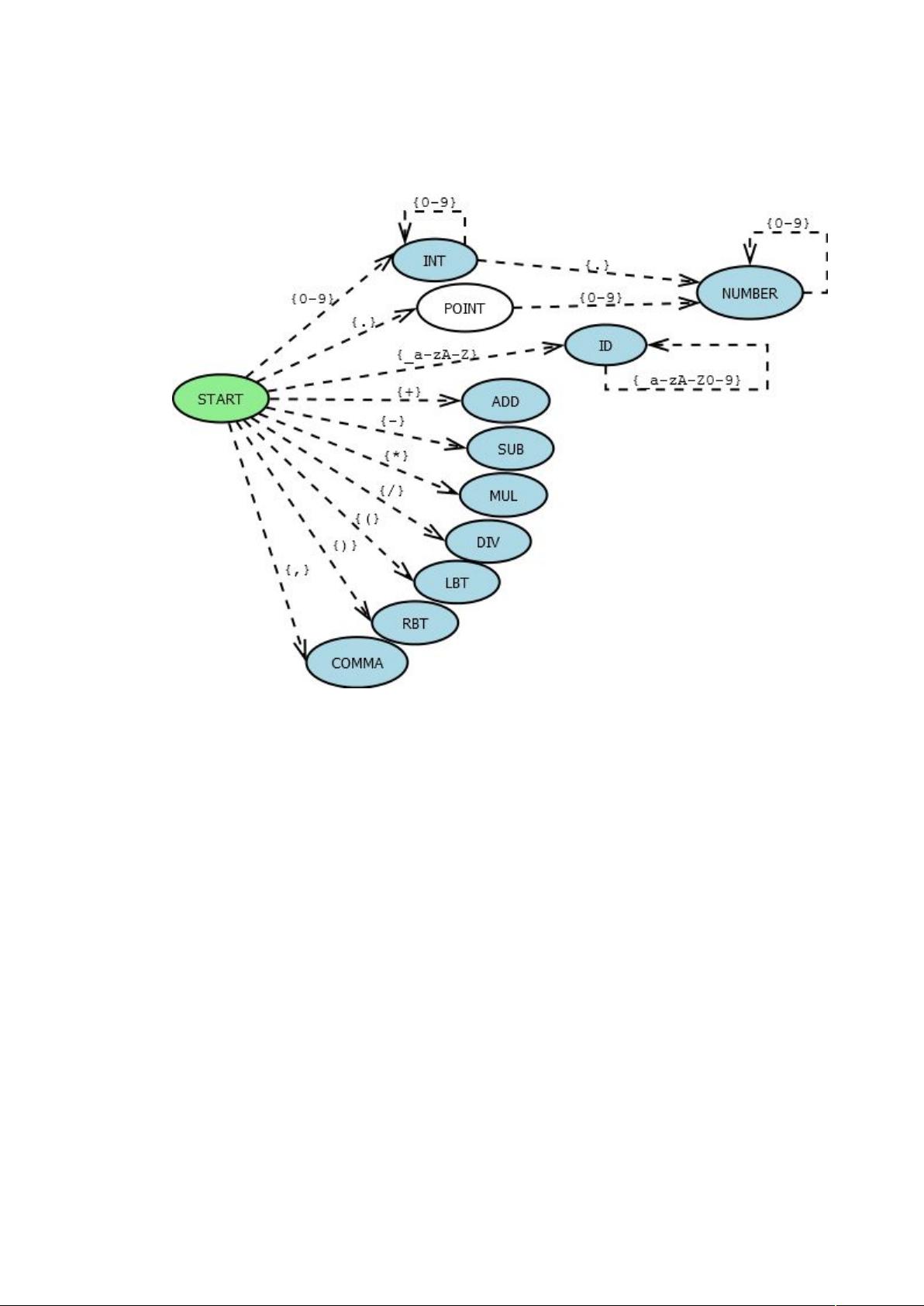
在编译原理中,普遍的方式是用如下一个状态转换图来实现的
在图中,“椭圆形”的是状态,状态与状态之间有一条有方向的线,这个线代表从一个
状态到另一个状态的路径,在这条线上面有一个花括号代表从前一个状态到达 后一个状态
的输入(为方便表示,0-9 表示从 0 到 9 十个数字,a-z 表示从 a 到 z 二十六个字母等),如
从 START 状态开始,输入一个数字 1,就会到达 INT 状态。
图中蓝色的状态是终结状态,如果从 START 状态经过若干输入后到达终结状态,则这
些输入的字符可合并为词法的合法单词——这里需要额外说明一点:在对输入进行匹配状
态时采用贪婪方式,即:尽量输入更多的字符。
在识别到一个合法的词法单元之后,状态回到 START 继续识别下一个元素,直到没有
新的元素为止。
这个状态转换图在编译原理中有一个专有名词称呼它“确定有限状态自动机”,英文简
称 DFA。这里“确定”的意思是每一个状态经过一个输入字符可以确定只有 一条路径到达另
一个状态,“有限”的意思是,状态的个数是有限的。对于一个复杂语言的状态数量是这个
状态机的几个数量级的大小。但我们现在的计算器只需要 这几个状态就够了。
通常的 DFA 会由工具读取正则方法描述而生成的,而不是直接手工构造,但对我们现
在设计的计算器来说,其 DFA 非常小,手工构造是很方便的,所以就不用工具了。另外,
如果使用工具的话,我这篇文章也不会使用现有的工具,而是自己实现一个工具。
下面举个例子:我们有一个表达式 12.3 + abc,下面我来描述一下 DFA 的运行过程:
定义一个变量 s,来表示当前状态机所在的状态(初始时 s = START)。
输入第一个字符 1,此时 START 状态可接受这个输入 1,到达 INT 状态,则变量 s 赋值
为 INT 状态,此时可看到 INT 状态的颜色是蓝色表示当前可识别为一个合法的词法元素,
剩余19页未读,继续阅读
2022-06-21 上传
2023-06-30 上传
2023-06-10 上传
2023-12-26 上传
2023-05-18 上传
2023-12-14 上传
2023-05-11 上传
2023-06-09 上传

智慧安全方案
- 粉丝: 3788
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
