Facebook上的Spark调优实践
需积分: 9 114 浏览量
更新于2024-07-18
收藏 2.53MB PDF 举报
"Spark调优在facebook的实践"
Apache Spark 是一个流行的大数据处理框架,尤其在处理大规模工作负载时表现出色。Facebook作为全球最大的社交媒体平台,每天需要处理大量的数据,因此对Spark进行优化至关重要。本实践主要关注Spark的几个关键方面,包括驱动程序(Driver)、执行器(Executor)的扩展性、外部洗牌(External Shuffle)服务的优化以及应用程序的调优,以确保高效运行。
首先,Apache Spark在Facebook的应用场景主要集中在大规模的批处理工作负载上,每天有成千上万的作业运行,并且在数千个节点上运行。这些作业处理的数据量庞大,压缩后达到数百TB,同时运行着数十万个任务,这就对Spark的可扩展性和性能提出了极高的要求。
**Spark架构**
Spark的核心架构包括集群管理器(Cluster Manager)、执行器(Executor)和驱动程序(Driver),以及用于数据交换的洗牌服务(Shuffle Service)。执行器在工作节点(Worker Node)上运行,负责执行任务;驱动程序则协调整个作业,分配任务给执行器,并通过洗牌服务处理数据的重新分布。
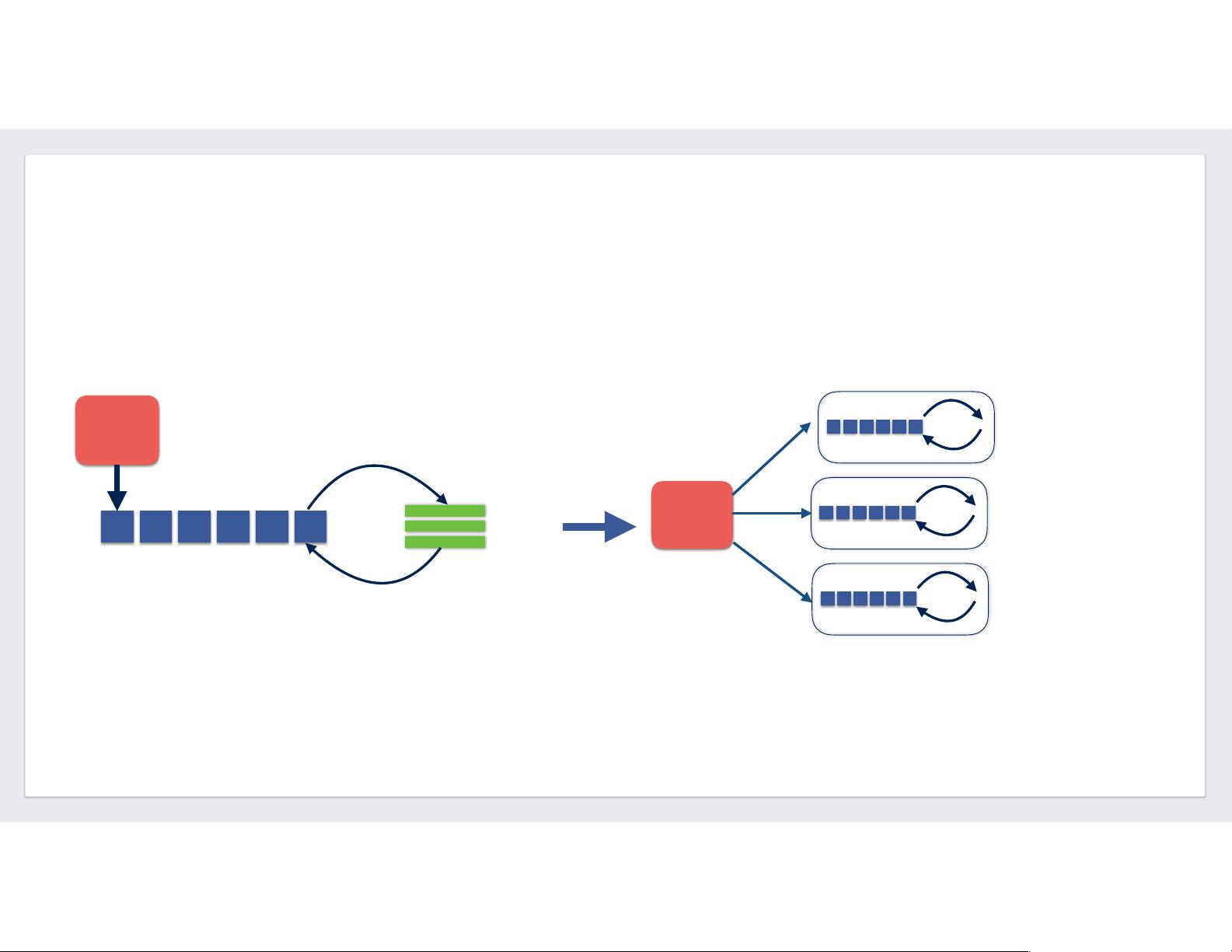
**Spark Driver的扩展性**
为了更好地利用资源并适应多租户环境,Facebook采用了动态执行器分配(Dynamic Executor Allocation)。当作业需要更多资源时,驱动程序会向集群管理器请求更多的执行器,而在执行器空闲超时(如2分钟)后会释放它们。动态分配可以通过以下配置启用:
```properties
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.executorIdleTimeout=2m
spark.dynamicAllocation.minExecutors=1
spark.dynamicAllocation.maxExecutors=2000
```
这样的设置可以有效地提高资源利用率,避免资源浪费。
**Spark Executor的扩展性**
随着工作负载的增加,Executor的数量也需要相应增加。Facebook可能采用了多线程事件处理器以提升Executor的并发处理能力,这有助于在单个Executor内部实现更高的吞吐量。
**Scaling External Shuffle Service**
外部洗牌服务是Spark优化的关键部分,它将洗牌数据存储在持久化存储中,而不是在Executor内存中,从而减轻了Executor的压力,提高了作业的容错性。通过扩展这个服务,Facebook能够处理大规模的洗牌操作,这对于大数据处理至关重要。
**应用程序调优**
除了基础架构的优化,Facebook还会对应用程序本身进行调优。这包括但不限于:优化数据读取策略,减少 shuffle 操作,调整任务粒度,优化数据序列化和反序列化,以及选择合适的调度策略等。
**工具支持**
为了管理和监控这些大规模作业,Facebook可能使用了一系列工具,如Spark自带的监控工具Spark UI,以及可能的自定义监控和日志分析系统,以便实时了解作业状态,快速定位问题。
总结来说,Facebook在Spark调优上的实践涉及到多个层次,从整体架构到具体组件,再到应用程序的每个细节,全方位地提升了大数据处理的效率和稳定性。这种深度优化策略对于任何处理大规模数据的企业或组织都具有很高的参考价值。
Dynamic Executor Allocation
Cluster!
Manager
Task Queue
Scheduler
Worker Node
shuffle!
service
shuffle!
service
shuffle!
service
Executor
Request !
Executor
Release!
Executor
•
Better Resource utilization
•
Good for multi-tenant environment
spark.dynamicAllocation.enabled = true!
spark.dynamicAllocation.executorIdleTimeout = 2m
spark.dynamicAllocation.minExecutors = 1
spark.dynamicAllocation.maxExecutors = 2000
剩余31页未读,继续阅读
2021-04-17 上传
2021-04-29 上传
2017-02-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

郭俊JasonGuo
- 粉丝: 122
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
