数据结构实验报告:线性链表操作与算法实现
需积分: 0 136 浏览量
更新于2024-06-30
收藏 1.43MB DOCX 举报
"这篇实验报告主要讲述了数据结构中的线性链表操作,包括删除多余结点和合并链表两个算法。作者张梦瑶是地球科学学院地理信息科学专业的学生,在指导教师刘刚的指导下,通过实验加深了对数据结构和算法的理解。实验涉及线性链表的基本操作,如插入、删除和查找,以及算法设计和流程图的建立。"
在数据结构中,线性链表是一种常用的数据结构,它的每个元素(称为结点)包含数据域和指针域,指针域指向下一个结点。实验的第一个目标是理解和实现线性链表的基本操作,这有助于掌握链式存储的特性和C语言编程技巧。
**删除多余结点的算法**是线性链表操作的一个重要实例。这个算法的目标是消除链表中数据域值相同的重复结点,保留其中的一个。实现这个算法的关键在于使用三个指针:`p`、`r`和`q`。`p`指针在外层循环中遍历整个链表,`q`始终指向`p`的前一个结点,而`r`则用于暂存`p`的下一个结点。在内层循环中,当`p`和`q`指向的结点数据域值相等时,删除`q`指向的结点(即当前重复的结点),并通过更新`q`和`r`来保持链表的连续性。这一过程持续到`p`遍历完整个链表为止。
关键代码如下:
```c
// 删除值相同的多余节点,list为传入链表
void DeleteSameNode(LinkList list) {
LinkList p, r, q;
p = list->link; // 跳过头结点
while (p != NULL) {
q = p; // q 指向当前被比较结点(值可能与 p 所指结点值相同)的前一
// 省略具体删除操作...
}
}
```
**合并链表的算法**涉及到两个线性链表X和Y的合并。这个算法要求合并后的链表仍然保持线性顺序,即X和Y中的元素按原顺序排列。实现方法通常包括遍历两个链表,将元素逐一添加到新的链表末尾,或者使用一个指针跟踪合并后的链表头部。
这个实验报告通过实际操作和代码实现,帮助学生掌握了线性链表的基本操作和算法设计。它不仅提升了学生的编程能力,也深化了他们对数据结构和算法分析的理解,为解决实际问题提供了理论和实践基础。关键词包括线性链表、堆栈、二叉树、图以及算法,显示了实验的广泛覆盖和深度。
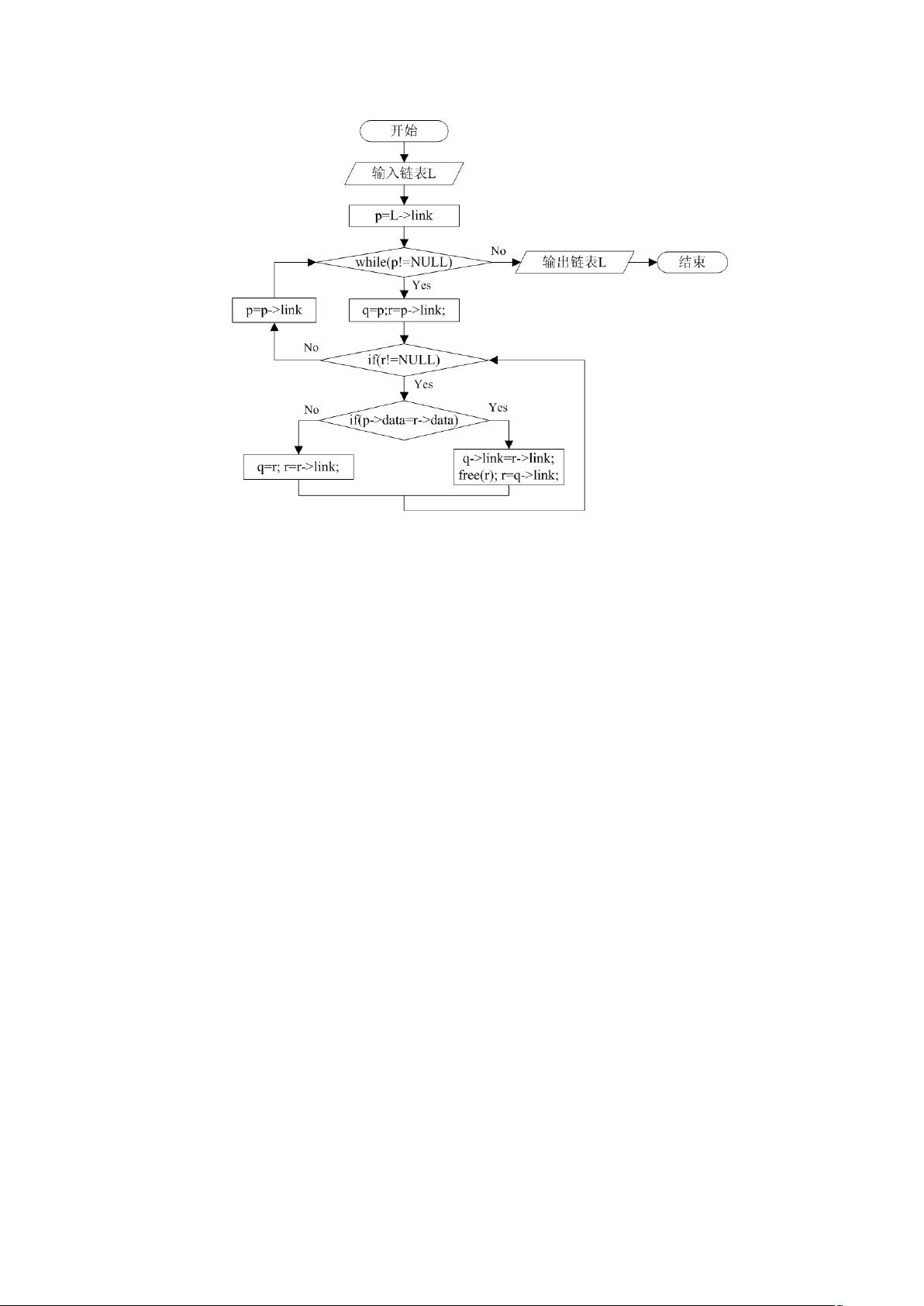
图 1 删除多余结点算法流程图
1.3.2 关键代码
实现该算法的核心代码如下:
//删除值相同的多余节点,list 为传入链表
void DeleteSameNode(LinkList list)
{
LinkList p,r,q;
p=list->link;//跳过头结点
while(p!=NULL)
{
q=p; //q 指向当前被比较结点(值可能与 p 所指结点值相同)的前一个结点
r=p->link; //r 总是指向当前被比较的结点,值相同则该结点被删除
while(r!=NULL)
{
if(p->data == r->data) //值相同,删除该节点,指针指向下一个节点
{
q->link=r->link;
free(r);
r=q->link;
}
else //值不相同,指针直接指向下一个节点
{
q=r;
r=r->link;
}
}
p=p->link;//分析下一个结点是否存在值相同的多余结点
}
剩余29页未读,继续阅读
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2023-12-18 上传
2020-05-06 上传
2021-02-11 上传
2022-12-23 上传
点击了解资源详情
点击了解资源详情

首席程序IT
- 粉丝: 41
- 资源: 305
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
