Clementine教程:中文版资料挖掘全指南
需积分: 50 153 浏览量
更新于2024-07-29
收藏 6.99MB PDF 举报
Clementine是一款强大的数据挖掘工具,它采用图形化界面让用户通过一系列节点构建数据流,进行数据分析和挖掘过程。这个教程将详细介绍如何在Clementine中创建和管理数据流,以及各个节点的功能和应用。
首先,Clementine的核心是数据流(stream),它由一系列节点组成,每个节点代表一个特定的数据处理操作,如从数据源读取(变量文件节点)、计算新字段(导出节点)、筛选数据(选择节点)和展示结果(表节点)。这种设计使得用户可以通过直观地连接节点,形成一个可视化的数据处理流程,类似于脚本,便于重复使用和跨数据集应用。
在Clementine中,建立数据流的步骤包括:添加节点到数据流区域、连接节点形成逻辑顺序、设置节点选项以指定操作细节,以及执行整个数据流。数据流区域显示了节点之间的关系,帮助用户理解分析过程。
节点选项板是Clementine的重要组成部分,它包含多个子面板,如来源(Sources)用于导入数据,记录选项(RecordOps)处理记录级别的操作,如选择和合并;字段选项(Fieldops)负责数据域的修改,如过滤和导出新字段;图(Graphs)提供可视化工具,如图表和评估图表;以及建模面板,展示了诸如神经网络、决策树等建模算法。
为了个性化使用,用户还可以自定义“Favorites”项目,收藏常用的节点组合,比如针对特定类型数据(如时间序列)的快速访问设置。这样可以显著提高工作效率。
在实际操作中,向数据流中添加数据流节点是从节点选项板中选取所需功能,然后将其拖放到数据流区域中的适当位置,通过连线将它们串联起来。每一步操作都应清晰明确,确保数据处理流程的有效性和准确性。
Clementine教程强调了其图形化界面的易用性,以及如何利用节点和选项板灵活设计和执行数据挖掘任务。通过掌握这些核心概念和技术,用户可以在Clementine中高效地进行数据探索、清洗、建模和可视化,从而深入理解并提取有价值的信息。
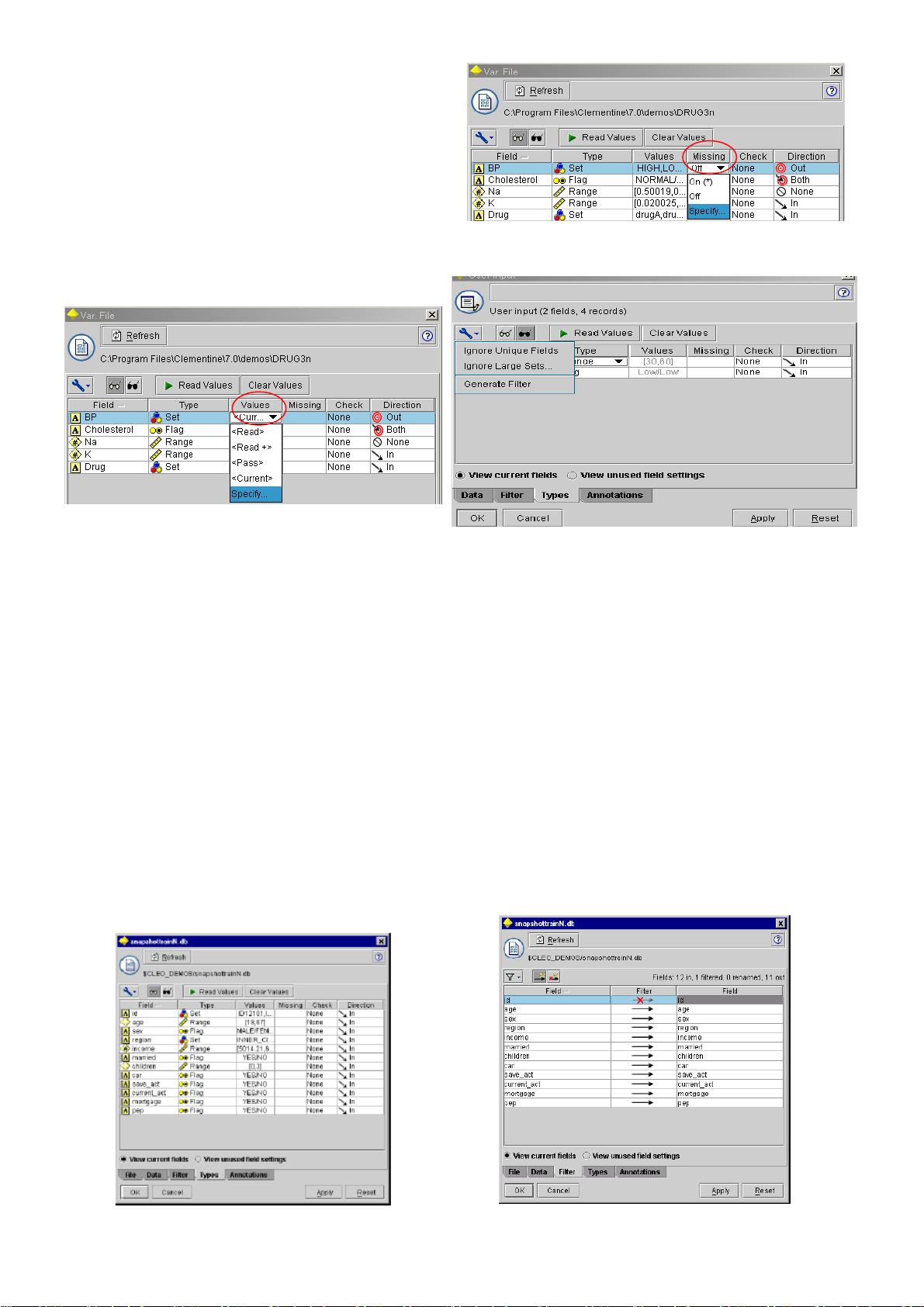
●方向(Direction):用来告知模型节点是否该字段将被
Input(预测字段)还是被 Output(被预测字段)。
Both 和 None 都是可用方向。
●遗漏值(Missing value):指定哪种变量值将当作空
格(blanks)。
●变量值检查(Value checking):在 Check 一栏中,使用
者可以设置选项来保证字段值在一定的指定范围内。
●实例化选项(Instantiation options):在 Value 一栏中,
图 4-18 遗漏值
使用者可以设置选项,是从数据集中读取数据值,还
是点击 Specify 来打开另一个对话框设置变量值。
图 4-18 实例化选项
●Ignore Unique Fields:将自动忽略只有一个值的字段。 图 4-18
●Ignore Large Sets:将自动忽略有很多成员的集合。
●使用工具菜单按钮,使用者可以建立一个 Filter 节点以丢弃已选字段。
(更多细节,参考“字段操作节点”章中的“在类型节点中设置数据类型”。)
在来源节点中设置数据类型
在来源节点中使用 Types 项目可以指定字段的一些重要属性:
●类型(Type)。用来描述给定字段的资料性质。如果一个字段的所有性质都是已知的,就被称为充分实例化(fully
instantiated)。字段的类型和字段的存储是不同的,字段类型是指资料是否被存储为字符串型、整数型、实数型、日
期型还是时间型。
●方向(Direction)。用来告知模型节点是否该字段将被 Input(预测字段)还是被 Output(被预测字段)。Both 和 None
都是可用方向。
●遗漏值(Missing value)。指定哪种变量值将当作空格(blanks)。
●变量值检查(Value checking)。使用者可以设置选项来保证字段值在一定的指定范围内。
●实例化选项(Instantiation options)。在 Value 一栏中,使用者可以设置选项,是从数据集中读取数据值,还是点击
Specify 来打开另一个对话框设置变量值。
图 6-19 从源中过滤字段 图 6-20 类型卷标选项
16
剩余107页未读,继续阅读
2011-02-07 上传
2022-06-06 上传
2008-07-21 上传
2009-04-06 上传
2015-06-23 上传
2009-06-24 上传
129 浏览量
2014-07-28 上传
2011-08-11 上传

kelvindzd
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
