Python Django MySQL:从零构建资讯网站——爬虫抓取与数据库存储
45 浏览量
更新于2024-08-29
收藏 505KB PDF 举报
"该资源是一篇关于使用Python、Django框架和MySQL数据库从零开始构建资讯类网站的教程。作者提供了完整的源代码,并在GitHub上进行了分享。在这一部分,作者将专注于创建一个爬虫来抓取指定资讯网站的新闻详情页内容,并将其存储到数据库中。爬取的目标网站是育儿在线,涉及的页面包括列表页和详情页的URL。"
在这个教程中,作者首先介绍了其目标,即建立一个爬虫来抓取同类资讯网站的新闻详情,并将这些信息存储到数据库中。为了实现这一目标,作者选择了Python作为主要编程语言,利用了Django作为Web开发框架,以及MySQL作为数据库管理系统。此外,还提到了其他技术标签,如Go、SQL,但它们在这个特定教程中可能不是直接相关的。
接着,作者展示了如何在Django项目结构中创建一个新的目录`spider`,并在其中创建一个名为`newsspider.py`的Python文件,这是爬虫的主要代码所在。在`newsspider.py`中,首先设置了环境变量以加载Django项目的设置,并导入了所需的库,包括`os`、`django`、`re`、`datetime`、`Detail`和`Tags`模型(假设这些都是Django项目的自定义模型),以及`requests`和`lxml`的`etree`模块,用于网络请求和HTML解析。
然后,作者定义了一个名为`getdetailbyspider`的方法,该方法使用`requests.get`发送HTTP GET请求获取网页内容,并使用`lxml.etree`解析HTML。这个方法的目标是从网页的HTML结构中提取新闻的详细信息,如标题、内容等。作者使用XPath表达式来定位包含特定信息的HTML元素,例如,`//div[(@class="content")]`用于找到内容区域,然后遍历每个匹配的元素以提取标题和其他细节。
教程的下一步很可能是解析获取到的HTML内容,提取出具体的数据,如发布时间、作者、内容等,并将这些信息存储到Django项目的`Detail`和`Tags`模型对应的数据库表中。这通常会涉及到使用Django的ORM(对象关系映射)来创建、读取、更新和删除数据库记录。
通过这种方式,作者逐步引导读者了解如何结合Python的网络爬虫技术和Django的数据库管理功能来构建一个能够自动获取和存储网络数据的系统。这个教程对于想要学习Web开发、爬虫和Django集成的初学者来说是非常有价值的资源。它不仅提供了实践项目,还有源代码可以参考和学习,有助于加深理解并鼓励动手实践。
python+django+mysql 从零搭建资讯类网站从零搭建资讯类网站10
系列文章将记录本人从零开始搭建资讯类的网站,所有源码都开放哦!欢迎互相讨论学习!
源码下载地址:https://github.com/wuqiwenpk/babyteach
本系列文章导航:https://github.com/wuqiwenpk/babyteach/blob/master/README.md
本篇目的本篇目的
通过爬虫爬取同类资讯网站新闻详情页,并保持内容到数据库中。
本次爬虫测试目标为
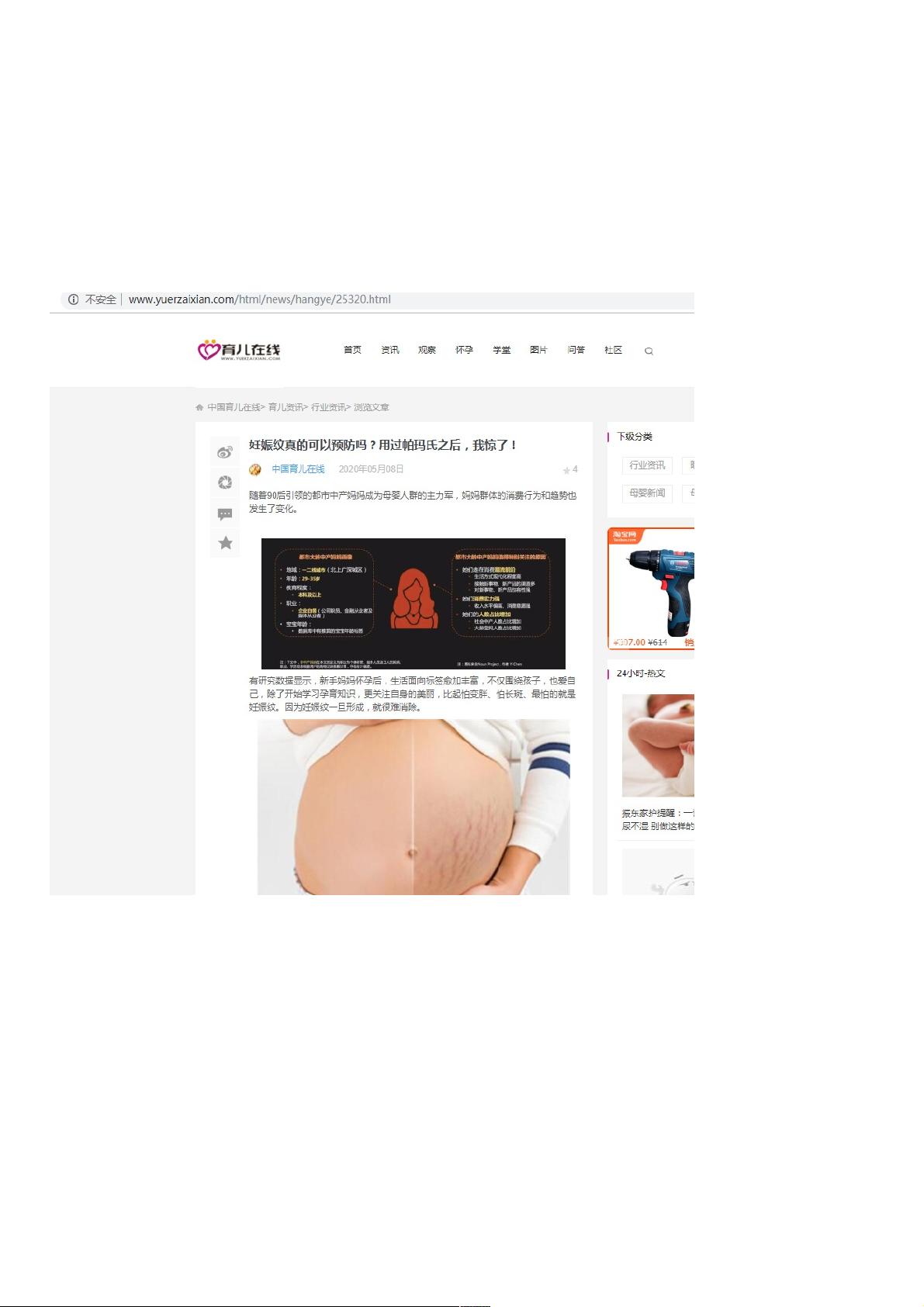
列表页:http://www.yuerzaixian.com/a/1171.aspx
爬取详情页:http://www.yuerzaixian.com/html/news/hangye/25320.html
本文将用到python解析库lxml、requests库对目标网页进行爬虫解析
(注:本系列所有爬虫操作仅用于学习用途)
1、在、在DjangoProject/babyteach下创建新目录下创建新目录spider
并添加py文件:newsspider.py
下载后可阅读完整内容,剩余4页未读,立即下载
2021-01-20 上传
2023-04-10 上传
2021-10-25 上传
2023-05-31 上传
2016-08-12 上传
2024-08-13 上传
2022-11-27 上传
2022-11-27 上传

weixin_38534352
- 粉丝: 5
- 资源: 982
 我的内容管理
展开
我的内容管理
展开







最新资源
- MyEvent-Mobile
- 无标题留言本
- vut-fit-iis:IIS(信息系统)类VUTBUT FIT项目-电子医疗卡信息系统
- forrust:非常笨拙,尚未用于时间序列预测的软件包
- pdfjs-viewer-shortcode:用于 WordPress 的 PDF.js 查看器短代码插件的更新 GitHub 存储库
- R-seauxClient-Server:它用于学校!
- ANN_scratch:在没有任何库的情况下实现ANN
- agent-authorisation-api
- Modal-Popup_
- culture-project:使用Gatsby和React重建我喜欢的网站的项目
- DrawableBug:Issue #172067 DrawableCompat#setTintList 的演示不适用于 Lollipop 及以上版本
- C# 进程间通信 Windows消息通讯,SendMessage
- Blog-AvadaMedia
- QianFeng_Study:这是我在前锋的书房
- skyhubv3
- minion-translator-app:此应用使用有趣的翻译API将英语翻译为Minionese
