CASIA的phrase-based SMT模型与自然语言理解研究
自然语言理解宗成庆的讲义主要围绕自然语言处理(Natural Language Processing, NLPR)中的一个重要议题——机器翻译展开。自然语言理解是指计算机对人类语言的理解和生成,这在信息技术领域中具有深远影响,因为它涉及到如何让计算机有效地处理和利用大量的自然语言信息。
该讲义的核心内容包括机器翻译技术,尤其是基于短语的统计机器翻译(Statistical Machine Translation, SMT)。短语基模型是SMT的一种流行策略,它假设句子可以被分解为有意义的短语,这些短语之间的翻译可以单独学习。CASIA的中文到英文SMT系统采用了这种模型,通过使用带变量的模板和不同的回溯算法来提高翻译质量。其中,翻译模型(pT(c|e))负责计算源语言(中文)到目标语言(英文)的概率,语言模型(pL(e))用于预测目标语言的语法结构,而扭曲模型(pD(e,c))则衡量翻译结果与原文之间的差异。
讲义详细介绍了系统架构,包括三个主要组件:翻译模型、语言模型和解码器。翻译模型负责根据源语言和目标语言的关联性生成翻译,语言模型确保生成的句子符合目标语言的统计规律,而解码器则是执行搜索策略,寻找最佳的翻译序列。CASIA的系统展示了如何将这些组件整合,以实现高效的机器翻译过程。
在CASIASMT系统中,短语翻译模型(PhraseTranslationModel)是一个关键部分,它通过匹配源语言中的短语并找到最合适的对应目标语言短语,实现了从中文到英文的转换。系统的性能证明了短语基模型相对于其他模型的优势,特别是在大规模平行文本数据的支持下,能够提供更准确的翻译结果。
宗成庆的《自然语言理解》讲义深入剖析了自然语言理解在机器翻译领域的应用,特别是短语基SMT模型在CASIA系统中的实践,这对于理解和开发现代语言处理技术,以及推动人工智能发展具有重要的参考价值。

NLPR
NLPR, CASIA 2006-5-9 宗成庆:《自然语言理解》讲义
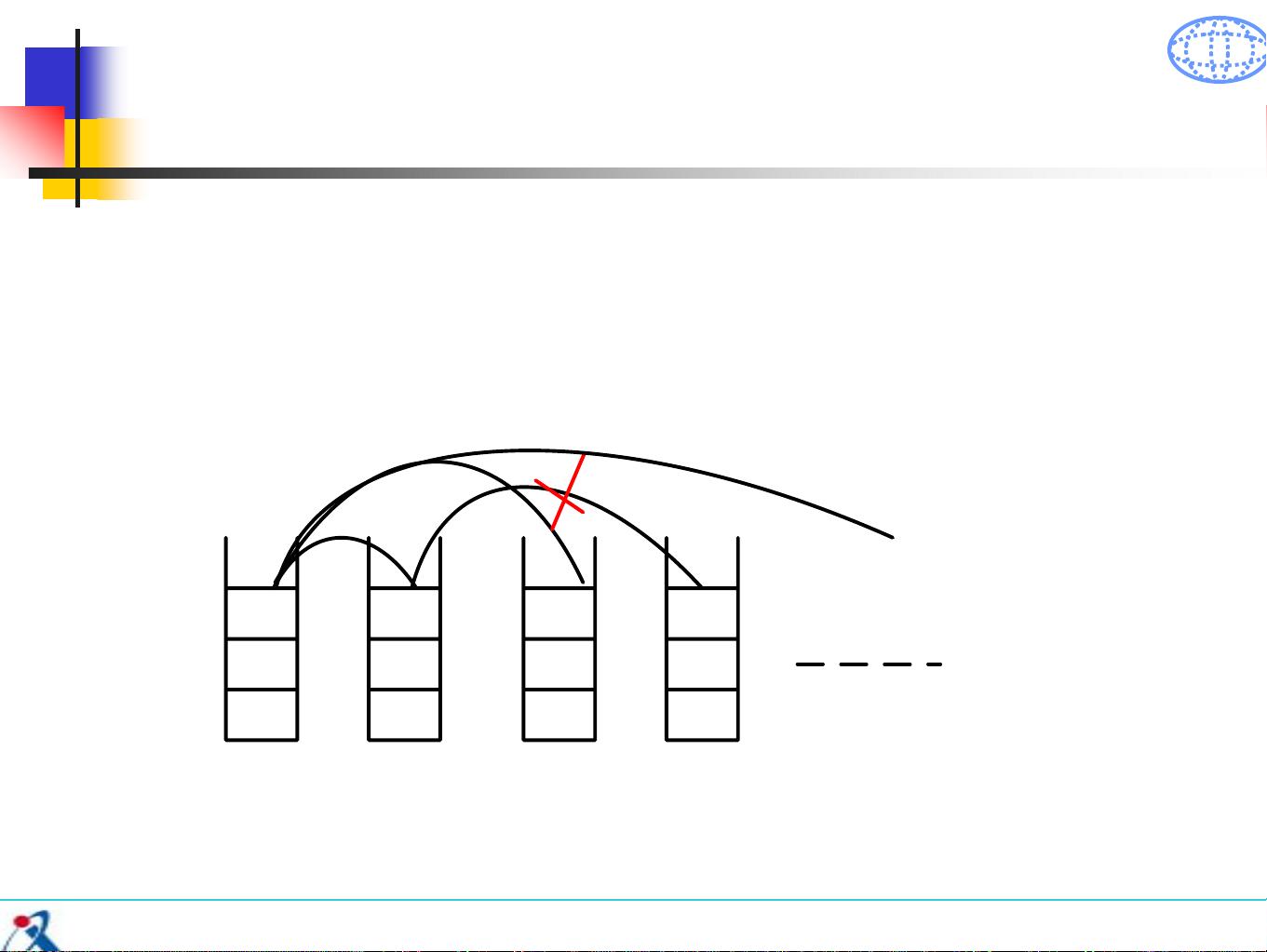
Beam-search for decoding
-Look up possible phrase translations [Koehn, 2003]
Different ways to
segment words into
phrases
Different ways to
translate each phrase
10.3.2 CASIA SMT System
10.3.2 CASIA SMT System
China with
North Korea has diplomatic
relationships
diplomatic relationships
has diplomatic relationships
China has the diplomatic relationships with North Korea
中国 与
北朝鲜
有外交关系
剩余49页未读,继续阅读
239 浏览量
314 浏览量
2018-10-08 上传
260 浏览量
235 浏览量

绿蚁新醅酒红泥小火炉
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ubuntu/Mac工作站的Ansible自动化配置手册
- 掌握核心,JAVA初级面试题解析大全
- 自我测试指南:成功方法与技巧大公开
- ReactSortableHOC实现动画化可排序的触摸友好列表
- SAE开源平台:整合Spring与SMS通讯功能
- 温尼伯公交信息实时查询系统开发
- JAVA实现的可部署仓储管理信息系统详解
- ArquitecturaClass软件:探讨JavaScript的架构设计
- 掌握React项目构建与部署的capstone3指南
- 详细解读车辆购置附加费征收办法
- Java实现学生成绩管理系统的设计与功能
- 易语言实现的MDB网络数据库模块源码解析
- 艺佰设计提供清新企业Discuz模板下载
- 掌握Python中的MLEnsemble实现高效集成学习
- Java实现读取搜狗细胞词库scel文件教程
- 探索城市星球的崛起:Nature & Science精选论文
