深度解析:人工智能领域关键的深度学习特性与理论
版权申诉
190 浏览量
更新于2024-06-30
收藏 2.03MB DOCX 举报
深度学习是人工智能领域的重要分支,它通过组合大量简单的非线性函数,如前馈神经网络或多层感知器(MLPs),实现对复杂数据集的有效建模和预测。这种技术的核心优势在于其深度结构,即网络包含多个隐藏层,能够自动提取并学习数据中的高级抽象特征,这是浅层模型难以比拟的。
深度学习的成功在很大程度上依赖于大数据集和高性能计算资源,特别是图形处理器(GPU)集群,它们能够处理海量参数和大规模训练。然而,深度学习并非仅仅依赖硬件,其内在的“过度参数化”特征允许模型拥有超过训练样本数量的参数,这既是挑战也是机遇,因为它可能导致无数潜在的局部最优解,但同时也需要有效的优化算法,如随机梯度下降,来找到具有良好预测性能的全局最优解。
此外,深度学习的训练过程隐含了某种形式的“隐式先验学习”,它能够在没有显式人工干预的情况下,通过自动调整模型参数,形成适应新数据集的泛化能力。这在迁移学习中尤为显著,模型能在相似任务或领域中展现出良好的性能。
深度学习理论方面,尽管实际应用中取得显著成功,但仍存在许多未解之谜。关键理论问题包括如何解释深度学习模型为何能够在有限的训练数据下表现出低预期风险。这涉及到对深度函数空间的学习能力和偏差-方差权衡的理解,以及如何分解模型的误差为近似误差和估计误差,这两个误差在深度学习中都应保持较小,以保证模型的高效性和稳定性。
前馈神经网络作为深度学习的基础模型,其架构设计至关重要。每一层神经元通过非线性激活函数进行信息处理,而隐藏层的逐层叠加使得模型能够处理高维度输入,形成强大的表征能力。通过调整网络的深度、宽度以及优化算法,深度学习模型能够在诸如图像识别、自然语言处理等复杂任务中展现出超越传统方法的性能。
总结来说,深度学习是人工智能领域的一个关键技术,其背后的关键特征包括数据规模、计算能力、深度结构、优化策略以及内在的模型学习能力。理解这些核心概念有助于我们深入探索和优化深度学习的应用,推动人工智能领域的持续进步。
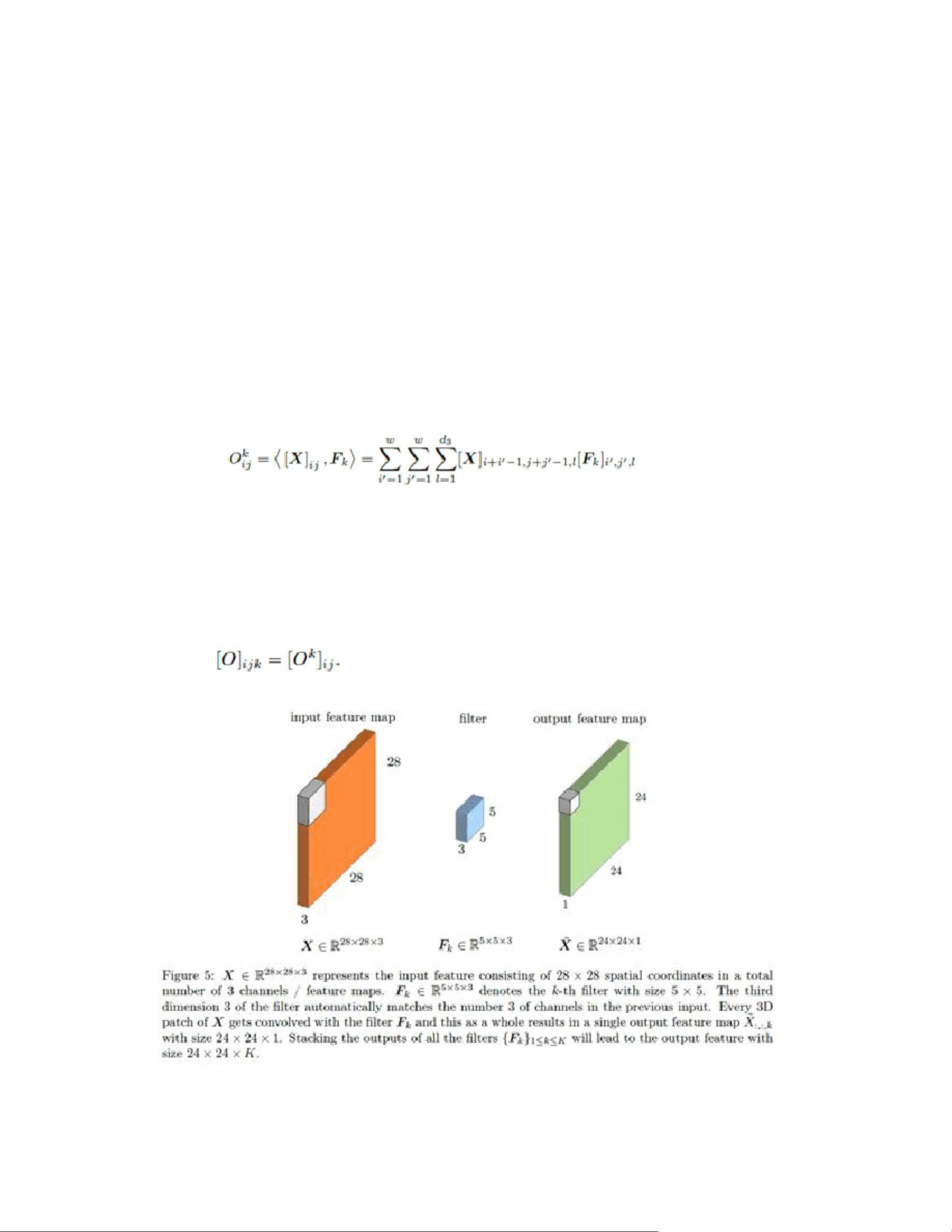
卷积神经网络( CNN)是一种特殊类型的前馈神经网络,适
用于分析具有突出空间结构的数据。 CNN 有两个构建模块,分别
为卷积层和池化层。本部分重点讨论使用 CNN 进行图像分类。
需要首先经过仿生
变换,再进行逐元非线性激活。区别在于仿生变换的具体形式。
卷积层使用一些过滤器从输入中提取局部特征。确切来说,每个
过滤器由一个三维张量表示,其中 是过滤器的大小(通常为 3
或 5), 表示过滤器的总数。 的第三维 须等于输入特征
的维度。每个滤波器 与输入特征 进行卷积,得到一个单一的
特征图
,其中
卷积过程见图 5。如果把三维张量
么每个滤波器基本都是计算它们与 中以 为索引的部分的内积
(也可以看作是卷积)。然后将得到的 打包成一个大小为
的三维张量 ,其中
和 看作是矢量,那
6

剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-05-09 上传
2023-06-12 上传
2024-06-14 上传
2023-07-22 上传
2021-10-15 上传
2023-08-16 上传

xxpr_ybgg
- 粉丝: 6753
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
