Transformer Pytorch代码进行详细解读,介绍其实现。(28字)
需积分: 0 45 浏览量
更新于2024-01-11
收藏 4.4MB PPTX 举报
Transformer PyTorch代码的解读。这个课件详细介绍了Transformer模型的原理和实现细节,并通过PyTorch框架实现了一个完整的Transformer模型。Transformer模型是一种用于自然语言处理任务的深度学习模型,自提出以来,已经在机器翻译、语言建模和文本生成等领域取得了很大的成功。
首先,课件从Transformer模型的输入和输出方式介绍了Transformer的整体架构。Transformer模型使用了一种称为自注意力机制的方法来捕捉输入序列中的上下文信息。自注意力机制能够对输入序列中的每个位置进行加权,使得模型能够在不同位置之间建立长距离的依赖关系。此外,Transformer模型还引入了一种称为位置编码的方法来标识不同位置的单词。
接着,课件详细介绍了Transformer模型的编码器和解码器部分。编码器由多层相同的编码器层组成,每个编码器层包含了一个多头自注意力机制和一个前馈神经网络。多头自注意力机制能够将输入序列进行多个子空间的映射,并同时学习不同子空间的表示。前馈神经网络则能够对每个位置的隐藏表示进行非线性变换。解码器也由多层相同的解码器层组成,不同的是解码器还引入了一个另外的自注意力机制,用于对编码器输出的隐藏表示进行加权求和。
随后,课件详细介绍了Transformer模型的训练过程。训练过程主要包括了损失函数的定义和反向传播的实现。Transformer模型使用了一种称为交叉熵损失函数来衡量模型输出与真实标签的差异。在反向传播过程中,模型通过计算损失函数对模型参数的梯度,并通过梯度下降算法来更新模型参数。此外,课件还介绍了一种称为学习率调度器的方法来自适应地调整学习率。
最后,课件介绍了Transformer模型的应用案例。其中包括了机器翻译、语言建模和文本生成等任务。对于机器翻译任务,Transformer模型能够将一个源语言句子翻译成一个目标语言句子。对于语言建模任务,Transformer模型能够预测给定上文下一个单词的概率分布。对于文本生成任务,Transformer模型能够根据给定的上文生成一个符合语法和语义规则的下文。
综上所述,本课件详细介绍了Transformer PyTorch代码的实现细节,并通过示例代码展示了Transformer模型在自然语言处理任务中的应用。通过学习本课件,读者可以更好地理解Transformer模型的原理和实现方法,并可以将其应用到自己的研究和工程项目中。
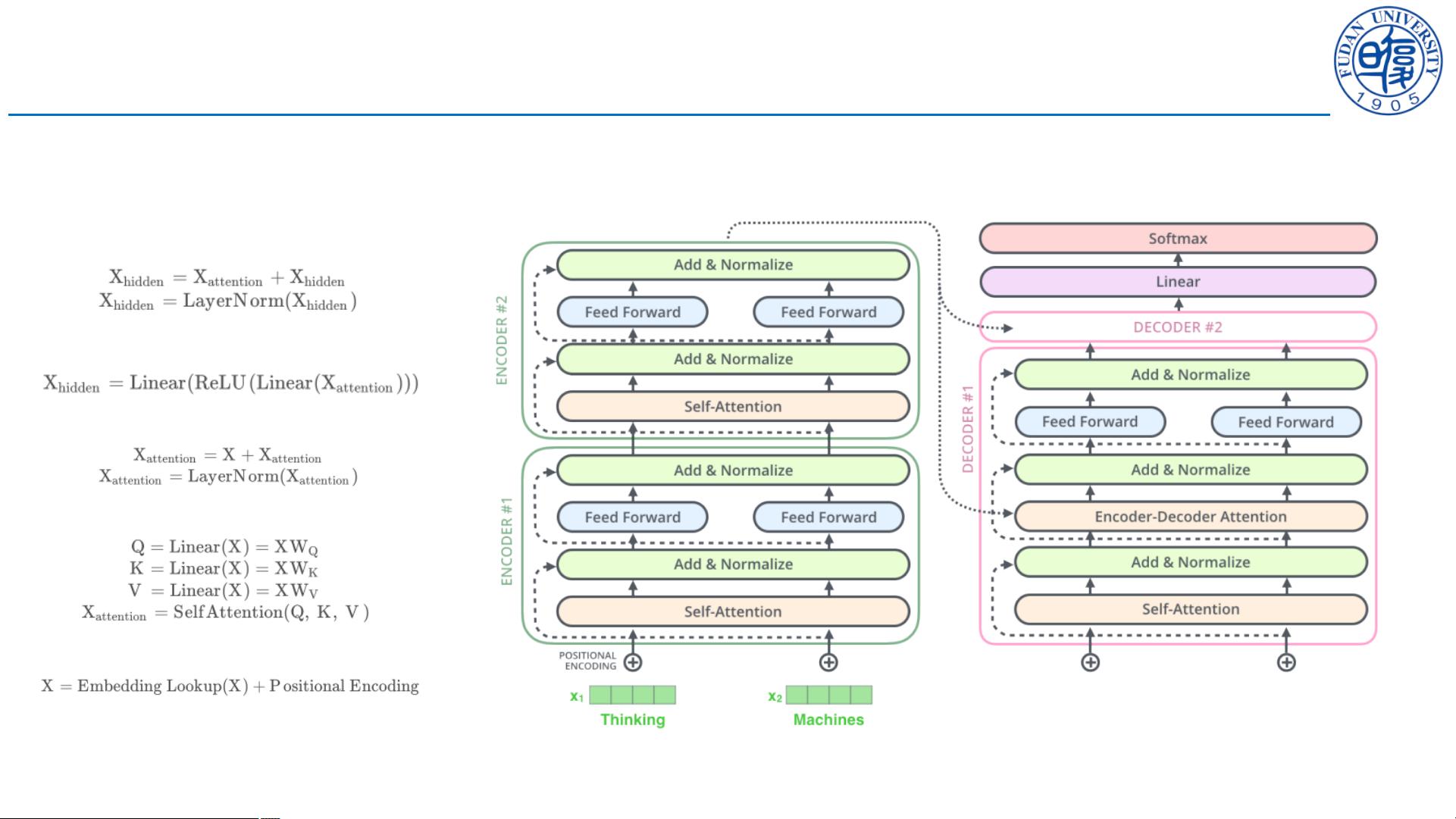
Transformer 工作流程
4
编码过程
剩余17页未读,继续阅读
2019-04-04 上传
2021-10-20 上传
2022-11-17 上传
2023-10-13 上传
2022-04-26 上传
2023-08-26 上传
2021-06-18 上传


_Meilinger_
- 粉丝: 819
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- linux项目工程资料-基于交叉编译的Linux发行版 .zip
- 基于neo4j社交兴趣推荐系统源码.zip
- AirwavesSmar.MetricsSeo.gaSrtCe
- MatthewBrown-GIS.github.io:这是我的个人作品集网站(当前正在进行中)
- Công cụ đặt hàng của eorder-crx插件
- BookStore.zip
- iMessage-Panda-sticker:动画PNG示例iOS 10的iMessage贴纸,挥舞着熊猫!
- Day10
- 藏匿处:存放缓存的地方
- Porovnání cen-crx插件
- ColdStartChallenge2021_Challenge1:回购2021年ColdStart挑战赛的第一个挑战
- pg-aa:具有ES6生成器API(pgco)的postgres包装器
- UG4LuaAutoComplete:LuaAutoComplete 的专有改编
- SL2021:Repositório– Livre 2021软件
- Manu-Auto-Correct:所以已经是总统先生
- library-example-task:基于一组要求的需求实现的库的实现
