"落笔云烟单字评分功能的SRS文档1及详细需求规格说明"
需积分: 0 50 浏览量
更新于2024-01-30
收藏 314KB DOCX 举报
生成的描述如下:
软件需求规格说明(SRS)是一个详细的文档,用于规定所需的系统功能和性能,以及软件系统的设计和实现约束。本文档主要针对落笔云烟软件的需求进行规定。
1. 范围:
1.1 标识:本文档的标识为SRS-1。
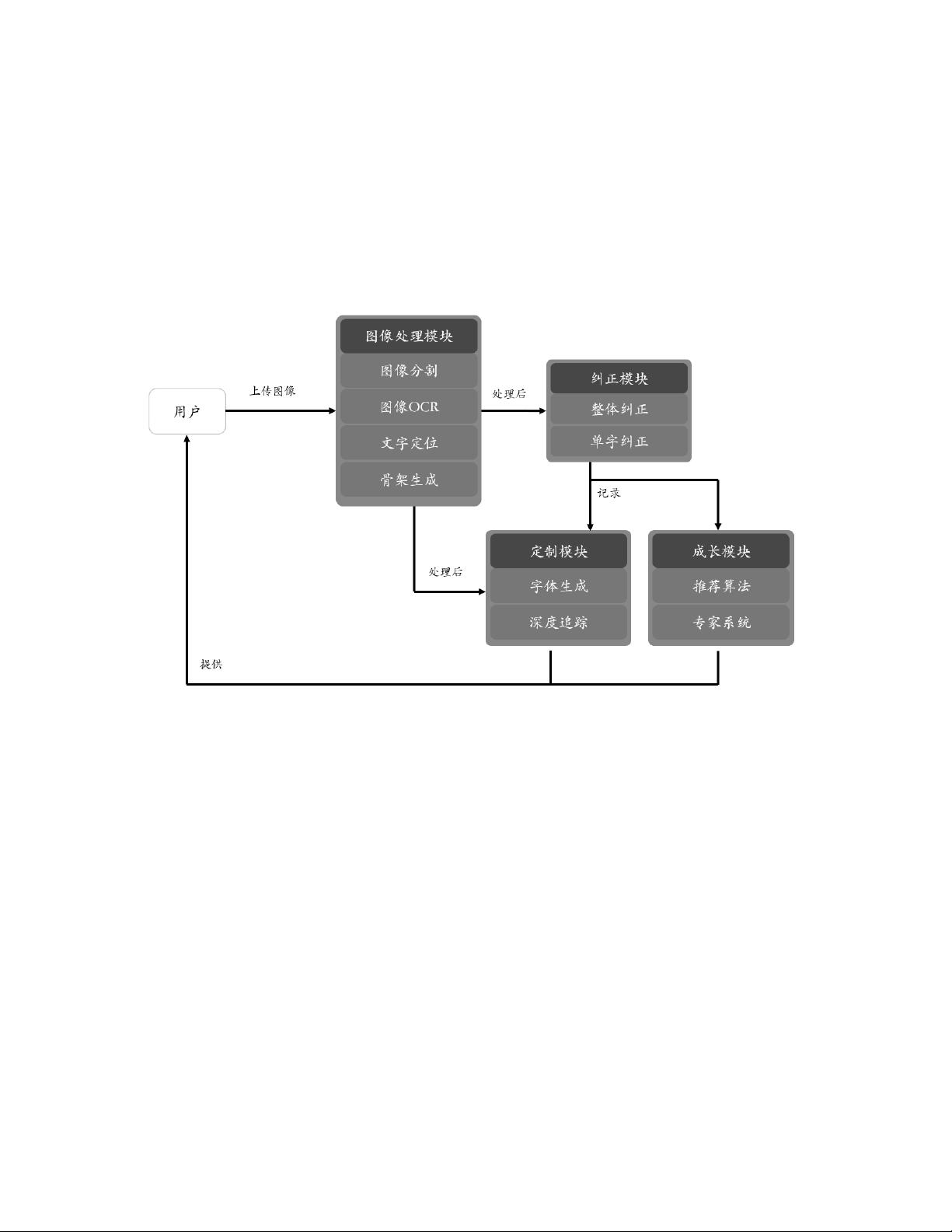
1.2 系统概述:本系统是针对字体打分和修改意见反馈的软件。用户可以上传字体文件或使用其他功能得到字体,系统会进行单字分析评价并提供修改意见反馈。
1.3 文档概述:本文档描述了软件需求规格说明的目录结构和所需的引用文件。
1.4 基线:本文档是该软件的基线版本,用于后续的系统设计和实施。
2. 引用文件:本文档引用了一些相关的文件,以便对系统需求进行详细的描述。
3. 需求:
3.1 所需的状态和方式:对系统运行的状态和使用的方式进行了定义和描述。
3.2 需求概述:对系统需求进行了整体概述,包括目标、运行环境、用户特点、关键点和约束条件等方面的描述。
3.3 需求规格:对软件系统总体功能和对象结构,以及软件子系统功能和对象结构进行了详细的规格说明。
3.4 CSCI 能力需求:对系统的能力需求进行了描述,以保证系统能够满足用户的需求。
3.5 CSCI 外部接口需求:描述了系统与外部接口的要求,以确保系统与其他系统的正常交互。
3.6 CSCI 内部接口需求:描述了系统内部各组件的接口需求,以保证系统的模块化和扩展性。
3.7 CSCI 内部数据需求:描述了系统内部所需的数据结构和数据格式要求。
3.8 适应性需求:描述了系统的适应性需求,以确保系统能够在不同的环境下正常运行。
3.9 保密性需求:描述了系统的保密性需求,以确保用户的信息不会被泄露。
3.10 保密性和私密性需求:描述了系统的保密性和私密性需求,以保护用户的隐私。
3.11 CSCI 环境需求:描述了系统的环境需求,包括硬件、软件和通信等方面的要求。
3.12 计算机资源需求:描述了系统对计算机资源的需求,包括硬件和软件等方面。
3.13 软件质量因素:描述了系统的质量因素,包括性能、可靠性、可维护性和可测试性等方面。
3.14 设计和实现的约束:描述了系统设计和实现的约束条件,以确保开发人员可以按照规定的要求进行开发。
3.15 数据:描述了系统涉及的数据要求和数据流程。
3.16 操作:描述了系统的操作流程和操作规范。
3.17 故障处理:描述了系统在故障情况下的处理机制和应对措施。
3.18 算法说明:描述了系统所使用的算法和计算方法。
3.19 有关人员需求:描述了系统实施和维护所需的相关人员和人力资源。
3.20 有关培训需求:描述了系统使用所需的培训需求,以确保用户能够正确使用系统。
3.21 有关后勤需求:描述了系统实施和维护所需的后勤需求。
3.22 其他需求:描述了系统的其他需求,如测试、审查和验证等方面的要求。
3.23 包装需求:描述了系统的包装要求,以确保系统能够安全地交付给用户。
3.24 需求的优先次序和关键程度:描述了对系统需求的优先级和关键程度的重要性排序。
4. 合格性规定:制定了系统需求的合格性规定和检验标准,以确保软件能够满足用户的需求。
5. 需求:总结了本文档中所规定的所有系统需求。
通过本文档的编写和规定,我们可以清楚地了解到落笔云烟软件的需求和功能,并能够在后续的开发和实施中进行指导和验证。同时,通过明确的需求规定,还可以提高软件质量,并减少开发过程中的错误和风险。

应用场景
1. 任何书写作品后想要评估作品美观程度的场景;
2. 任何想要练习书法,但是缺少专业老师指导的场景;
3. 任何想要改善当前的书写水准,却难以长期坚持临摹练习的场景。
目标人群
1. 任何对改善书写水平、迅速发现自身书写问题有需求的学生党、上班族;
2. 想要学习书法,但身边缺乏专人指导的书法爱好者。
3.1.4 关键点
说明本软件需求规格说明书中的关键点(例如:关键功能、关键算法和所涉及的关键技术
等)。
技术问题
1. 手写字检测时的噪声问题:在使用目标检测模型前先使用 CycleGAN 去除大部分的
图像噪声,之后使用调优后的目标检测模型检测单个手写字。
2. 用户书写的评价问题:书法是一门即包含艺术性也需兼顾结构化的领域,因此书法
的评价上不可使用单一的方式评价。本项目通过检测出的汉字骨架,结合模版汉字的骨架,
从是否缺少笔画、各笔画的差异、结构的问题三个方面进行评分。
3. 用户书写纠正:改模块分为汉字骨架识别与汉字字形纠正两部分,汉字骨架识别通
过识别出汉字的笔画信息提供给汉字字形纠正部分作为基础信息。汉字纠正部分根据识别
出的汉字骨架,通过计算用户写的汉字与模版汉字的各个笔画的区别,判断各个笔画的书
写情况。之后通过数据库中预先建模好的汉字的结构信息,匹配该汉字存在的书写缺陷及
指导建议反馈给用户。
项目数据集获取问题
目前已经具备的开放数据集:
1) 中科大手写汉字数据集 CASIA-HWDB
2) 哈工大手写识别数据集 HIT-OR3C
3) 北邮脱机手写汉字数据集 HCL2000
除此之外,项目团队在上述数据集基础上自行标注了小规模 Peanuts- HWDB 数据集,用于
项目中文本评分和字态纠正神经网络的训练测试;目前已经使用其中大约 5%的可用数据
训练模型 demo,已证实可行。
3.1.5 约束条件
列出进行本系统开发工作的约束条件。例如:经费限制、开发期限和所采用的方法与技术,
以及政治、社会、文化、法律等。
文档约束:使�⻜书�档进�团队协作,对于不同版本的�档,�动建�多�件标号来进
�版本控
制�不是使�⻜书本�的版本控制。
开发约束:在 Github 上进�多�协作,每个代码提交要有测试、code review。
代码约束:尽量思考优雅的代码实现,采用合适的设计模式,提升代码可重用性,降低代码耦
合度.
常量约束:对于系统通�常量应该有规定的�档来承载、记录。
文化约束: 对于某些特殊字体,应当对其书写方式表达一定的尊重;并严格按照中华人民共
和国常用 3500 字为基准构造数据集.
剩余32页未读,继续阅读
2022-08-08 上传
389 浏览量
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2021-03-13 上传
2024-06-10 上传

lirumei
- 粉丝: 74
- 资源: 301
 我的内容管理
展开
我的内容管理
展开







最新资源
- another-round:另一轮琐事游戏
- RabbitMQ-Demo.zip
- Story-app-2:故事应用
- c-simple-libs:简单,干净,仅标头,C库
- SoftEngG1B:软件工程项目
- 水晶动物图标下载
- 可执行剑:关于剑的游戏
- monke-lang:德蒙克的威
- 虎皮鹦鹉图标下载
- Django_Personal_Portfolio:使用Django制作的投资组合网站
- hassant5577.github.io
- shaarlo:统一Shaarlis Rss
- 4boostpag
- Công Cụ Đặt Hàng Của Express-crx插件
- 米老鼠图标下载
- AdaptableApp:CITRIS 应用程序竞赛
