深度学习驱动的MR图像超分辨率:融合多尺度信息的卷积网络
需积分: 5 37 浏览量
更新于2024-07-14
收藏 768KB PDF 举报
"本文主要探讨了在卷积网络中融合多尺度信息以实现磁共振(MRI)图像的超分辨率重建技术。"
在医疗成像领域,尤其是磁共振成像(MRI),高分辨率图像对于减少图像伪影(如部分体积效应PVE)以及提高后期图像处理步骤(如图像配准和分割)的准确性至关重要。然而,MRI的分辨率受到物理、技术以及经济等多种因素的限制。因此,提升空间分辨率是医学图像处理领域的一个重要研究方向。
传统的超分辨率(SR)方法,如稀疏编码和超分辨率卷积神经网络(SRCNN),已经在场景图像的重建上取得了显著效果。然而,这些方法在恢复低分辨率MRI图像中的精细结构信息方面仍存在不足。本文作者提出了一种新的策略,即在卷积网络中融合多尺度信息,以增强对MRI图像超分辨率重建的能力。
论文首先分析了现有学习型超分辨率方法的局限性,特别是在处理MRI图像时遇到的挑战,如信号的非线性特性、噪声水平以及不同组织间的复杂对比度。随后,作者介绍了一种新型的深度学习模型,该模型能够同时考虑不同尺度的信息,从而更好地捕捉图像的细节特征。
模型设计中,可能包括了多级卷积层和残差连接,以促进特征的多尺度提取和信息传递。此外,为了处理MRI图像的特定属性,可能还采用了特定的损失函数,如感知损失或结构相似性指数(SSIM),以优化重建图像的质量和保真度。
实验部分,作者对比了提出的多尺度融合方法与其他基础超分辨率技术在MRI图像上的表现,通过定量和定性的评估指标(如峰值信噪比PSNR和视觉质量)展示了新方法的优势。实验结果证明,融合多尺度信息的卷积网络在保留图像细节、提高边缘清晰度和减少重建误差方面有显著改进。
总结来说,这篇研究论文提出了一个创新的深度学习框架,它通过在卷积网络中融合多尺度信息,有效地提高了MRI图像的超分辨率重建能力,有助于解决低分辨率图像在医学诊断和分析中的问题,进一步推动了医疗图像处理技术的发展。
Page 5 of 23
Liuetal. BioMed Eng OnLine (2018) 17:114
e success of convolution neural networks in SR mostly depends on the contribu-
tion of the learned convolution kernels from the training samples. To investigate the
effects of different convolution kernels in SR tasks, we generated two distinct kernels
with sizes of
3 × 3
and
15 × 15
for a better visual representation. en, the two kernels
were applied to a simple low-resolution image. e convolution results and the differ
-
ence between the high-resolution and low-resolution images are shown in Fig.3. As
shown in the first row, the main difference between the high-resolution and low-resolu
-
tion images is at the edges. erefore, the task of SR is to recover detailed information,
such as edges. Furthermore, the second and third rows in Fig.3 show that convolution
operations with different kernel sizes yield varying responses along the edges, and the
strengths of the responses depend on the size of the convolution kernels. Due to the
receptive field range of the convolution kernels with different sizes, the larger convolu
-
tion kernels induce stronger responses along the edges. Consequently, these convolution
responses are extracted as multi-scale information of the convolution kernels.
Design ofmulti‑scale network architecture
Due to the forward and back propagation mechanisms in the convolution neural net-
work, we constructed a simple convolution network stacked by two convolution layers
as shown in Fig.4. Both convolution layers have only one convolution kernel. In the
convolution network, the input low-resolution images are submitted to the network
and convoluted using the following convolution layers sequentially to obtain the feature
maps. is procedure is called forward propagation. After the final convolution layer,
the errors in the feature maps and high-resolution images, and the difference images,
are computed based on the Euclidean distance of the loss layer. e difference images
are very important for adjusting the kernel parameters of the final convolution layer. All
parameters of each layer are adjusted using stochastic gradient descent.
Due to the multi-scale properties of different kernel sizes, fusing different scale con
-
volution responses is assumed to accelerate the SR procedure. In the following study, we
developed a simple MFCN as shown in Fig.5. As depicted in Fig.4, the MFCN has two
convolution layers, and each layer has only one convolution kernel. We added a fusion
layer to the network shown in Fig.5. e function of the fusion layer is simply to add
feature maps from (b) and (c). Initially, the fusion image had more details than the feature
map in (c). Moreover, compared with the difference image I in Fig.4, the difference image
(f) in Fig.5 is darker, which indicates less error between the recovered image and high-
resolution image and is beneficial for accelerating the convergence in the training phase.
erefore, it is desirable to design a convolution network that combines differ
-
ent scale information. Reconstructed images benefit from end-to-end learning of low/
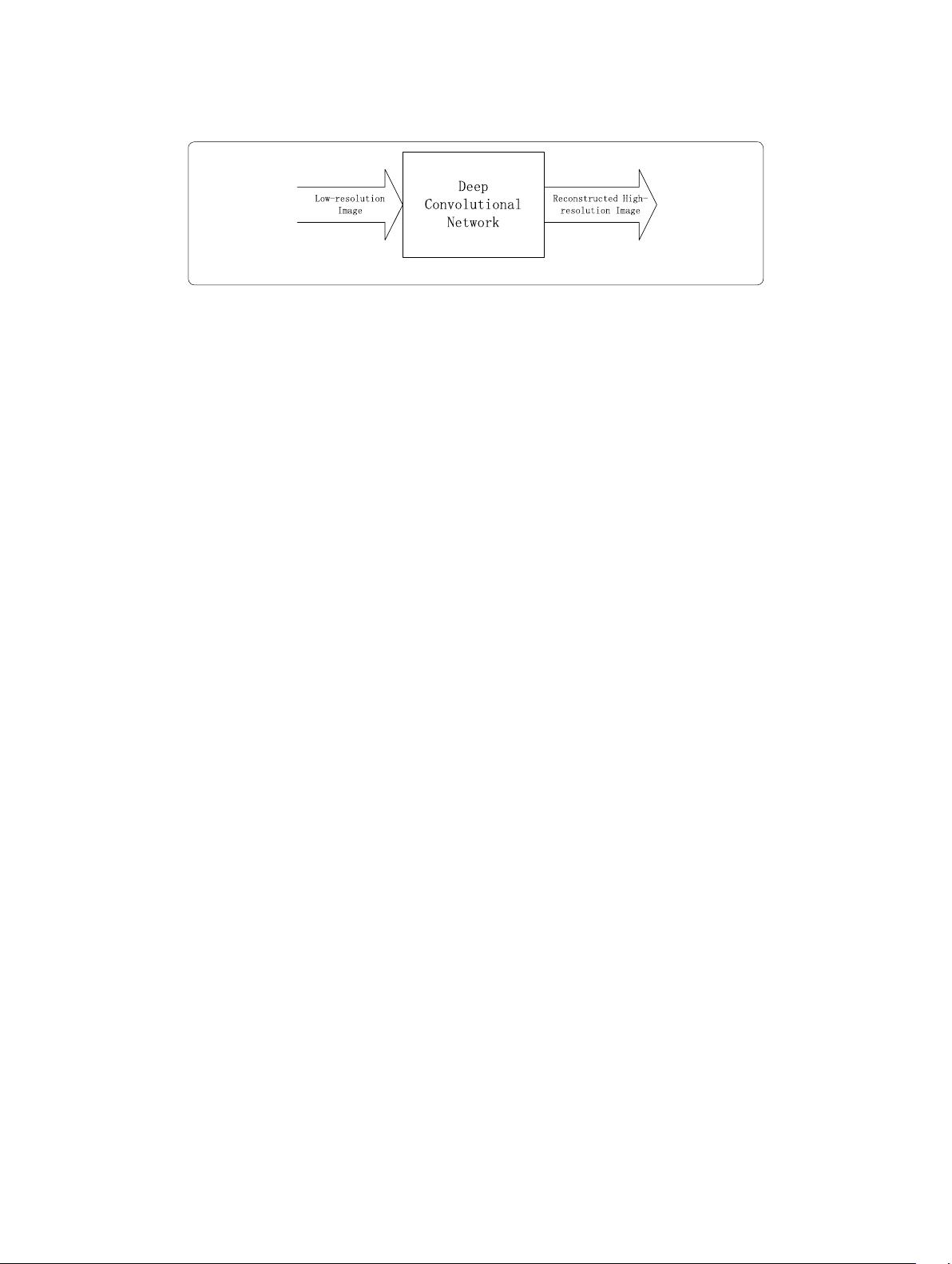
Fig. 2 Super-resolution reconstruction based on deep convolutional network
剩余22页未读,继续阅读
2021-09-25 上传
2021-09-25 上传
2021-09-26 上传
2023-02-23 上传
2021-09-26 上传
2021-09-25 上传
2021-09-25 上传
2021-02-21 上传
点击了解资源详情

weixin_38551046
- 粉丝: 5
- 资源: 928
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
