青云QingStor对象存储2.0:企业级存储与大数据解决方案详解
需积分: 10 127 浏览量
更新于2024-09-10
收藏 806KB DOCX 举报
青云QingStor对象存储2.0产品白皮书深入解析了青云的下一代对象存储解决方案,旨在为企业提供一个高效、可靠且可扩展的存储平台。该产品定位在应对海量非结构化数据的存储需求,特别适用于现代企业的多元化场景。
首先,QingStor对象存储通过其易用性,支持多种访问方式,如浏览器、RESTful API、NFS、FTP和S3接口,使得数据管理变得简单高效。无论是企业内部的网盘和文档管理,还是与办公自动化(OA)系统的协同工作,都能得到顺畅的处理,确保信息的高效流通和团队协作。
在Web和移动应用领域,QingStor凭借高可扩展性,能够应对互联网和移动互联网带来的大流量和数据爆发。它不仅兼容结构化数据的存储,还能轻松处理非结构化数据,确保应用的高性能运行,适应业务的快速增长。
对于大数据存储与分析,QingStor以其无限扩展的存储能力及通用的S3协议兼容性,无缝融入Hadoop、Hive、Spark等大数据生态系统,帮助企业灵活地存储和分析海量数据,驱动决策优化。
此外,产品的安全性得到了充分保障,拥有完备的安全机制,保护数据免受未经授权的访问。同时,作为一个开放的异步数据处理平台,它支持多样化的数据迁移策略,使得数据迁移过程更加便捷。管理门户的统一设计则提供了全生命周期的对象管理,简化了运维流程。
硬件配置方面,白皮书中详细列出了产品规格,包括但不限于存储容量、I/O性能、吞吐量等关键指标,确保用户可以根据实际需求选择合适的配置。整体而言,QingStor 2.0对象存储是企业数据存储和分析的理想选择,其全面的功能和卓越的性能能满足现代企业对数据存储的多样化需求。性能测试数据显示,该产品在处理大量并发请求和数据读写任务时表现出色,证明了其在实际环境中的高效表现。
总结来说,青云QingStor对象存储2.0是一款功能强大、易于使用且高度可扩展的企业级存储解决方案,为企业数据管理、应用运行和大数据分析提供了坚实的基石。
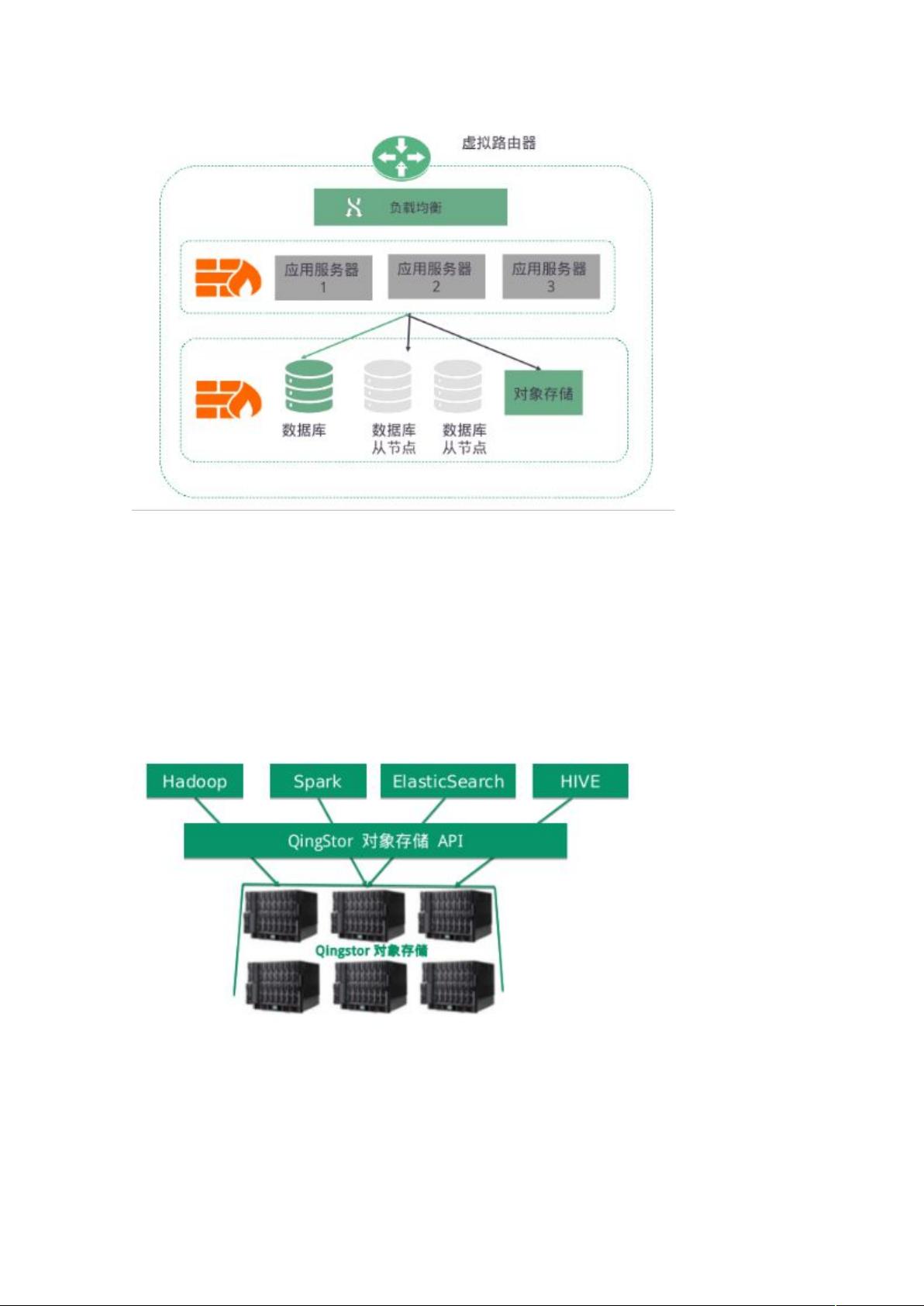
场景三:大数据存储&分析
当海量的数据持续的从各种地方产生时,企业要解决的第一个重要的难题是数据要存储在
什么地方,然后是怎么灵活高效的存取这些数据来进行各类的计算分析,QingStor 对象存储
拥有的无限可扩展的数据存储能力和通用 S3 协议标准的支持,让
Hadoop、Hive、Spark、ElasticSearch 等大数据生态系统可以无缝的接入,提供的数据不
动&计算并行的能力让数据产生的价值可以在各种业务及分析系统中顺畅流动,持续的挖掘出
数据隐藏的价值来为企业经营管理中的各类决策服务。
场景四:数据统一存储平台
企业的数据按存取频率可分为实时、近线和离线三种类型,通常会用不同的存储系统来应
对这三种数据,但当数据量快速增长,不但给每个独立系统的运维管理带来极大的挑战,也难
以用简单的方式对各类数据进行分析挖掘,QingStor 对象存储独特的异构集群统一架构,不
但实现了使用统一的调度框架管理、调配和扩展各种存储资源,而且依然提供统一的
剩余12页未读,继续阅读
2021-05-14 上传
2020-02-21 上传
2023-05-24 上传
2024-10-15 上传
2023-05-24 上传
2023-04-05 上传
2023-08-06 上传
2023-08-05 上传

weixin_42106117
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
