可逆循环神经网络:降低训练内存需求的新途径
需积分: 10 122 浏览量
更新于2024-07-16
收藏 2.25MB PDF 举报
"这篇论文探讨了可逆循环神经网络(Reversible Recurrent Neural Networks)在处理序列数据时如何降低训练过程中的内存需求。通过允许隐藏层到隐藏层的转换可以逆转,可逆RNN旨在减少训练期间必须存储的隐藏状态,从而在反向传播过程中重新计算这些状态。然而,作者指出,完全可逆的RNN存在限制,因为它们无法从隐藏状态中遗忘信息。为了克服这个问题,他们提出了一种方法,即在隐藏状态中存储少量位,以实现遗忘的同时保持可逆性。这种方法在保持与传统模型相当的性能下,降低了激活内存成本,减少了10到15倍。此外,该技术也被扩展到基于注意力的序列到序列模型中,在编码器中减少了5到10倍的激活内存成本,而在解码器中减少了10到15倍。"
可逆循环神经网络(RNN)是循环神经网络的一个变体,其核心思想是使得网络的前向传播过程能够被逆转。这在理论上允许在反向传播时重算隐藏状态,而不是保存这些状态,从而显著减少了内存消耗。然而,一个完全可逆的RNN存在一个关键问题:由于其不能遗忘旧的信息,它可能无法适应长期依赖问题,这是许多RNN遇到的挑战。
为了解决这个问题,研究者提出了一个策略,即在隐藏状态中保留少量的位,以允许网络在保持可逆性的同时遗忘不重要的信息。这种方法在实践中证明是有效的,因为它能够在不牺牲性能的前提下,显著降低训练过程中的激活内存需求。在与传统RNN模型的比较中,这种可逆RNN方法成功地实现了内存成本的10到15倍的减少。
此外,这种技术也被应用于基于注意力的序列到序列模型。在这些模型中,编码器和解码器通常需要处理大量的上下文信息,因此内存效率尤其重要。应用可逆RNN的方法后,编码器的激活内存成本降低了5到10倍,解码器则降低了10到15倍。这样的改进对于处理长序列和复杂语言任务的自然语言处理(NLP)模型来说,是一个巨大的进步,因为它不仅保持了模型的性能,还显著提升了训练效率。
可逆RNN提供了一个创新的解决方案,通过引入有限的遗忘能力,克服了完全可逆网络的局限性,同时大幅度减少了内存使用,这对于大规模NLP任务的训练具有重大意义。这一研究成果为未来优化RNN训练过程和提高资源利用效率打开了新的可能性。
...
...
+
...
...
Attention
...
<SOS>
DecoderEncoder
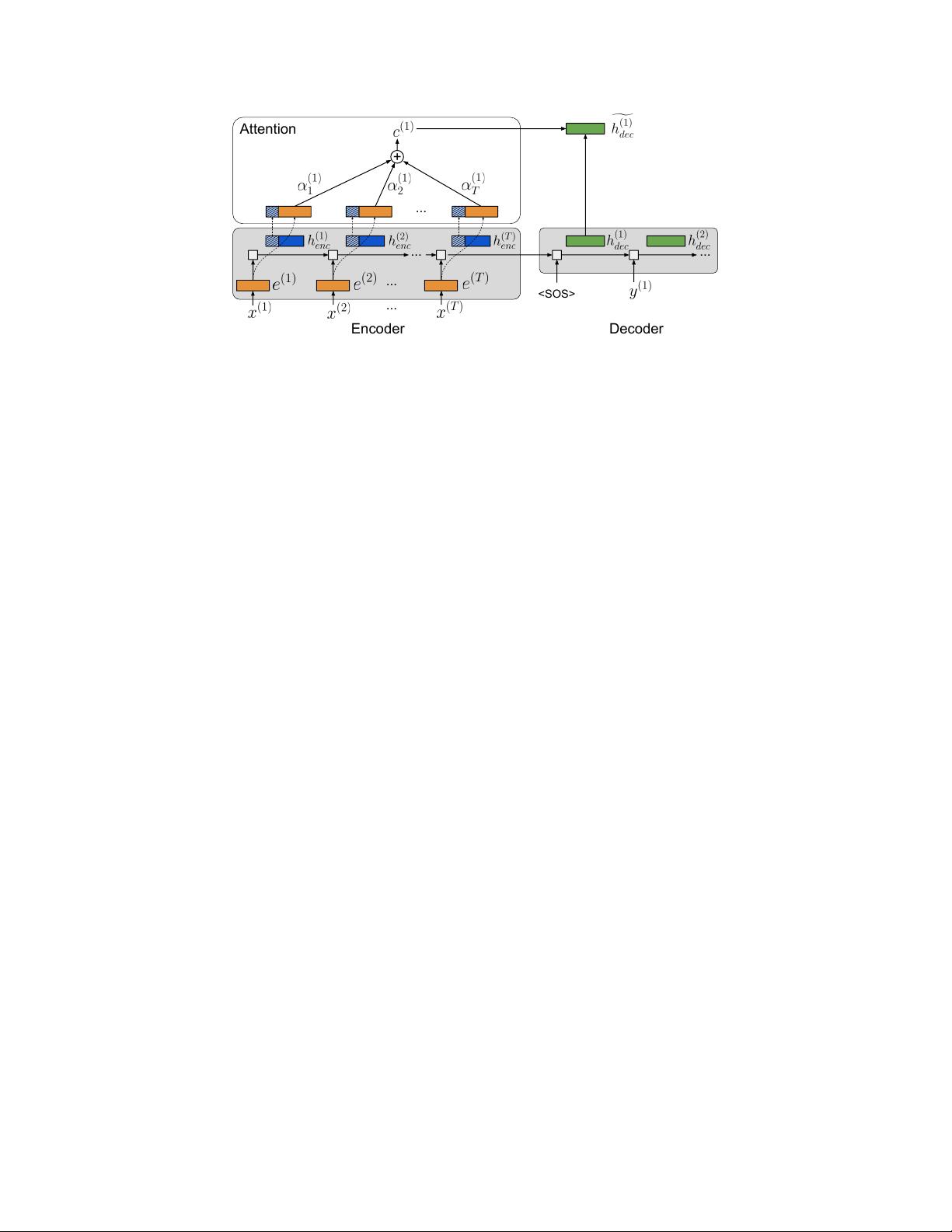
Figure 2:
Attention mechanism for NMT.
The word embeddings, encoder hidden states, and decoder hidden
states are color-coded orange, blue, and green, respectively; the striped regions of the encoder hidden states
represent the slices that are stored in memory for attention. The final vectors used to compute the context vector
are concatenations of the word embeddings and encoder hidden state slices.
5.1 GPU Considerations
For our method to be used as part of a practical training procedure, we must run it on a parallel
architecture such as a GPU. This introduces additional considerations which require modifications to
Algorithm 1: (1) we implement it with ordinary finite-bit integers, hence dealing with overflow, and
(2) for GPU efficiency, we ensure uniform memory access patterns across all hidden units.
Overflow.
Consider the storage required for a single hidden unit. Algorithm 1 assumes unboundedly
large integers, and hence would need to be implemented using dynamically resizing integer types,
as was done by Maclaurin et al.
[13]
. But such data structures would require non-uniform memory
access patterns, limiting their efficiency on GPU architectures. Therefore, we modify the algorithm
to use ordinary finite integers. In particular, instead of a single integer, the buffer is represented
with a sequence of 64-bit integers
(B
0
, . . . , B
D
)
. Whenever the last integer in our buffer is about to
overflow upon multiplication by
2
R
Z
, as required by step 1 of Algorithm 1, we append a new integer
B
D+1
to the sequence. Overflow will occur if B
D
> 2
64−R
Z
.
After appending a new integer
B
D+1
, we apply Algorithm 1 unmodified, using
B
D+1
in place of
B
.
It is possible that up to
R
Z
−1
bits of
B
D
will not be used, incurring an additional penalty on storage
cost. We experimented with several ways of alleviating this penalty but found that none improved
significantly over the storage cost of the initial method.
Vectorization.
Vectorization imposes an additional penalty on storage. For efficient computation,
we cannot maintain different size lists as buffers for each hidden unit in a minibatch. Rather, we must
store the buffer as a three-dimensional tensor, with dimensions corresponding to the minibatch size,
the hidden state size, and the length of the buffer list. This means each list of integers being used as a
buffer for a given hidden unit must be the same size. Whenever a buffer being used for any hidden
unit in the minibatch overflows, an extra integer must be added to the buffer list for every hidden unit
in the minibatch. Otherwise, the steps outlined above can still be followed.
We give the complete, revised algorithm in Appendix C.3. The compromises to address overflow and
vectorization entail additional overhead. We measure the size of this overhead in Section 6.
5.2 Memory Savings with Attention
Most modern architectures for neural machine translation make use of attention mechanisms [
4
,
5
];
in this section, we describe the modifications that must be made to obtain memory savings when
using attention. We denote the source tokens by
x
(1)
, x
(2)
, . . . , x
(T )
, and the corresponding word
embeddings by
e
(1)
, e
(2)
, . . . , e
(T )
. We also use the following notation to denote vector slices: given
a vector
v ∈ R
D
, we let
v[: k] ∈ R
k
denote the vector consisting of the first
k
dimensions of
v
.
Standard attention-based models for NMT perform attention over the encoder hidden states; this is
problematic from the standpoint of memory savings, because we must retain the hidden states in
memory to use them when computing attention. To remedy this, we explore several alternatives to
storing the full hidden state in memory. In particular, we consider performing attention over: 1) the
embeddings
e
(t)
, which capture the semantics of individual words; 2) slices of the encoder hidden
6

剩余30页未读,继续阅读
180 浏览量
169 浏览量
2021-10-29 上传
164 浏览量
2024-07-15 上传
832 浏览量
127 浏览量

hywcxq
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
