Hive与HBase整合原理与实战应用
本文将深入探讨Hive与HBase的整合实践,首先介绍两者的结构以及它们如何通过API接口实现相互间的集成。Hive是一个基于Hadoop的数据仓库工具,它提供了SQL查询接口来处理大规模数据,而HBase则是一个分布式、列式存储的NoSQL数据库,特别适合于大规模数据的实时读写。
整合原理方面,Hive与HBase的整合主要依赖于`hive-hbase-handler.jar`工具类,这个工具允许Hive通过HBase的Storage Handler进行操作。Hive Storage Handlers是Hive的核心组件,它们允许Hive与外部数据源交互,包括HBase,从而扩展了Hive的数据访问能力。
整合后的使用场景涉及多个实际操作,例如:
1. **场景一**:当需要从HBase中读取数据并进行JOIN操作,比如从HBase获取基础数据后再与Hive中的其他表进行关联分析,这时可以直接在Hive的SQL查询中使用JOIN语句,并指定HBaseStorageHandler。
2. **场景二**:周期性地加载HBase的数据到Hive表中,以便于进行离线分析或长期存储,这可能涉及到定期的INSERT或UPDATE操作,以及GROUP BY等聚合查询。
3. **场景三**:在持续更新模式下,Hive可以执行查询,更新HBase中的数据,实现实时或近实时的数据同步。
整合后的使用方法包括启动Hive时配置与HBase的连接信息,如单节点启动时添加`hbase.master`参数,集群启动时设置ZooKeeper的quorum。创建Hive表时,需指定`HBaseStorageHandler`并配置列映射和属性,如`hbase.columns.mapping`用于指定HBase表中的列名映射关系。
Hive与HBase的整合为大数据处理提供了灵活且强大的解决方案,用户可以根据实际需求选择合适的数据源和查询方式,以提高数据处理效率和分析性能。掌握这种整合技术对于处理大规模、复杂的数据场景至关重要。
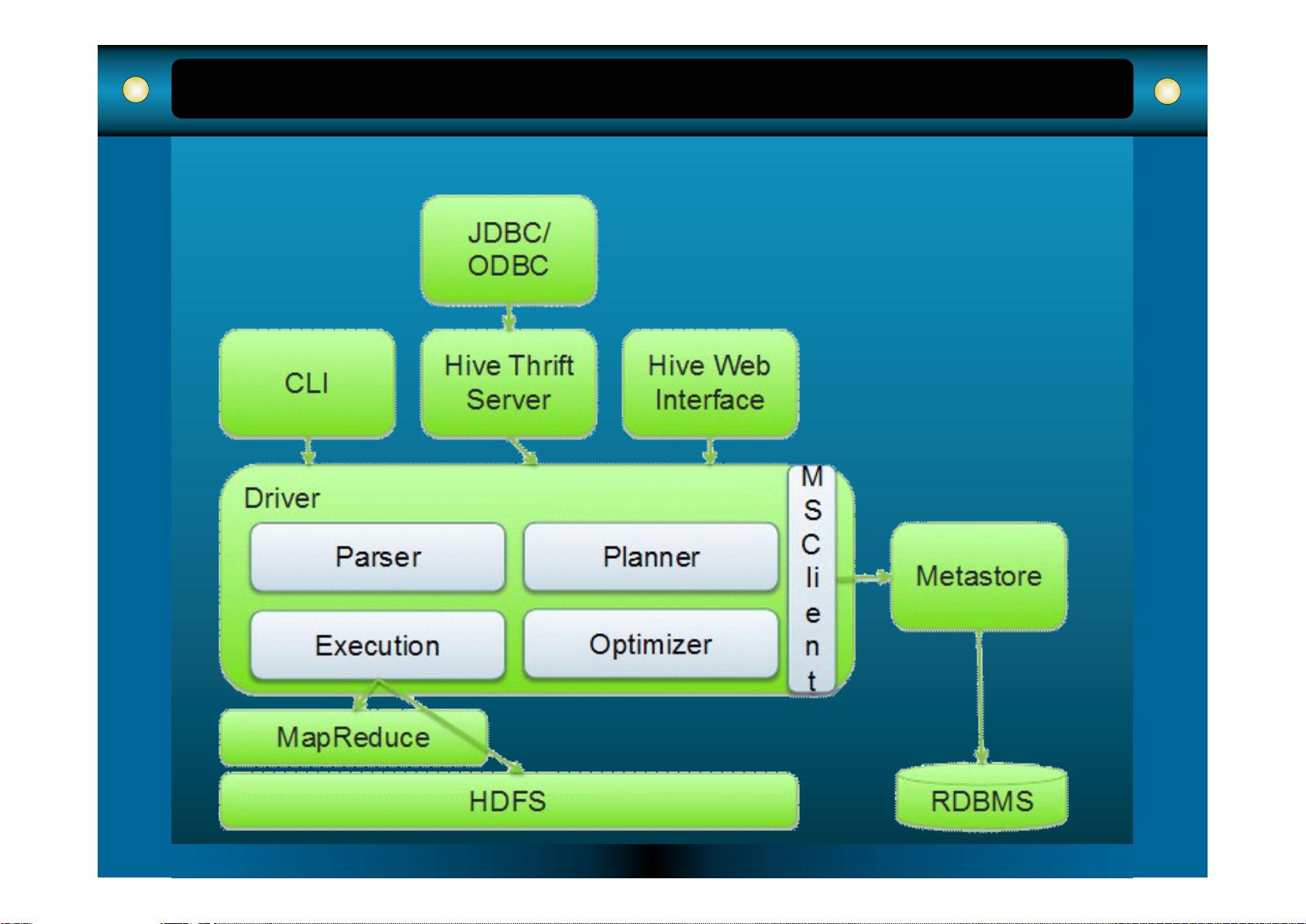
Hive
的 结 构
剩余18页未读,继续阅读
2017-11-16 上传
2019-08-09 上传
2019-08-08 上传
2024-11-22 上传
点击了解资源详情
点击了解资源详情
2017-07-03 上传
2017-10-10 上传

jackyhungvip
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
