Apache Ranger权限管理深度解析:授权流程与用户操作详解
22 浏览量
更新于2024-08-28
收藏 473KB PDF 举报
Apache Ranger是Apache Hadoop生态系统中的一个重要组件,它提供了一套全面的访问控制解决方案,用于管理和监控Hadoop集群中的各种资源,包括Hive、HDFS、Kafka等。本文主要深入探讨了Ranger的核心功能和工作原理,从管理员角色到用户的权限管理,具体涉及以下几个关键点:
1. **Hive授权流程**:
- 管理员在Ranger中设置策略,为特定用户或用户组定义对Hive数据库的访问权限,比如读写操作。
- 用户通过JDBC或Beeline客户端与Hive Serve2进行交互,发起权限请求。
- 当用户请求访问时,Hive会检查当前策略是否已更新。如果没有更新,则依赖本地缓存;如有更新,Hive会调用Ranger API获取最新的策略。
- HiveServer2支持grant和revoke操作,这些操作会同步到Ranger服务,确保策略一致性,并在Ranger的审计日志中记录操作历史。
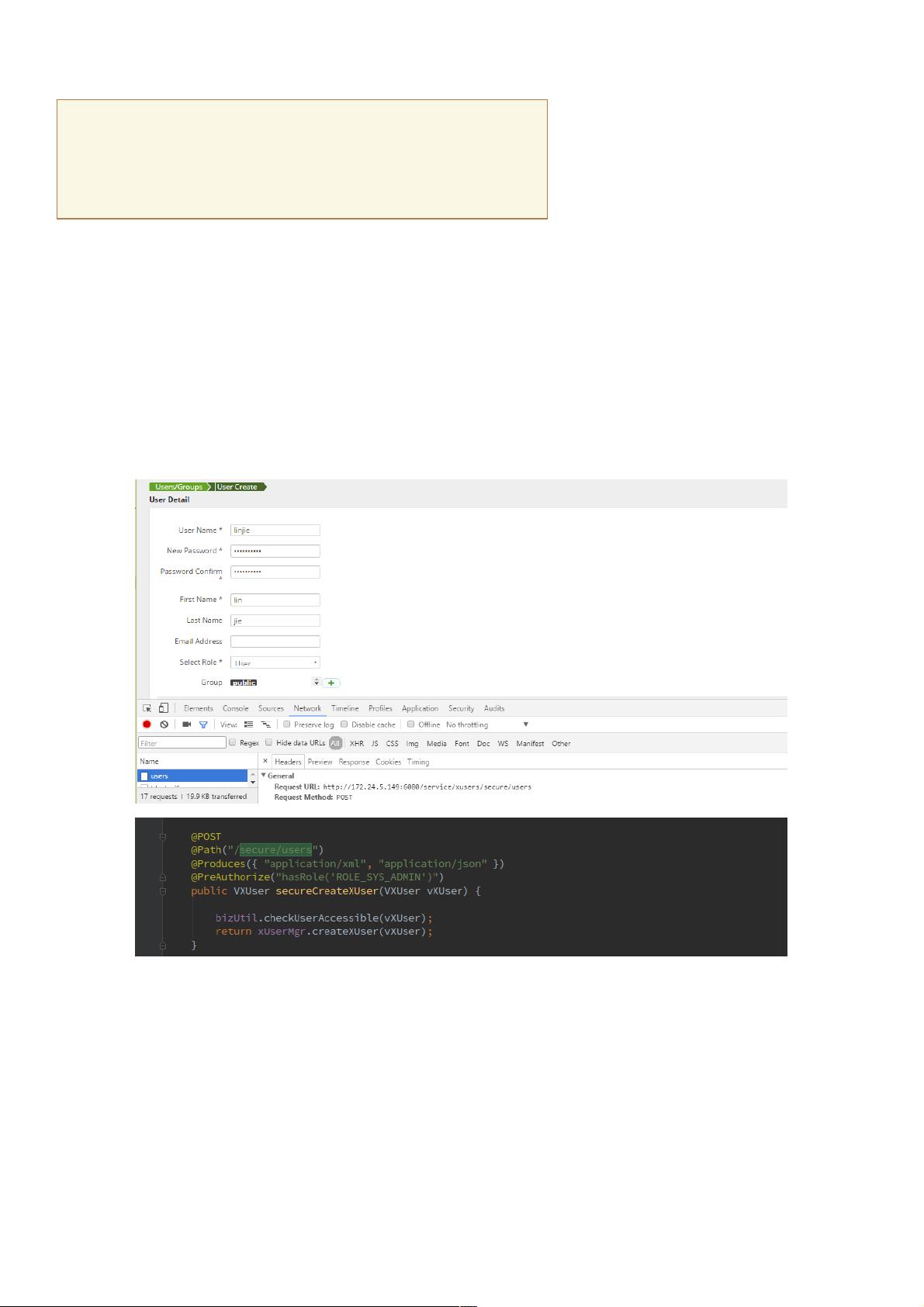
2. **Ranger用户创建流程**:
- 创建用户时,系统首先验证创建者的admin权限以及新用户的数据合法性。
- 初始化用户数据结构,如XPortalUser和XUser,分别对应于数据库中的x_portal_user和x_user表。
- 如果用户属于某个用户组,会将其信息添加到x_group_users表中。
- 操作日志(如XXTRxLog)被记录在x_trx_log数据库中,以便追踪用户权限的变化。
- 用户的角色和模块权限更新会根据XPortalUser关联到x_user_module_perm表。
3. **用户删除**:
- 删除用户时,系统会检查必要的权限,包括获取x_user、x_portal_user、x_group_users、x_perm_map和x_audit_map表的信息。
- 通过用户ID关联到x_auth_sess、x_user_module_perm、x_portal_user_role和policy对象,以确保删除操作的精确性。
Apache Ranger是一个强大的访问控制框架,通过与Hadoop组件紧密集成,实现了细粒度的权限管理,确保数据的安全性和合规性。了解和掌握Ranger的工作原理对于有效地管理和保护大数据环境中的资源至关重要。
APACHE RANGER 调研调研----ranger 原理解析原理解析
编辑推荐编辑推荐:
本文主要介绍了hive 授权流程、ranger 用户创建流程、用户删除、创建策略、删
除策略、更新策略等相关内容。
本文来自csdn,由火龙果软件Anna编辑、推荐。
1.hive 授权流程
(1) 管理员设置策略以及用户(例如一个用户对一个hive数据库相关的权限)
(2) 用户通过 jdbc beeline 去请求HiveServe2
(3)hive 权限check, 请求ranger api 获取策略是否已经更新,更新了就利用新的策略,如果没有更新利用本地缓存数据,
plugin 会30 秒访问ranger服务 更新策略
(4) hiveserver2 可以通过grant 和 revoke 去请求 ranger 服务 去更新策略
(5) check 和 grant 和 revoke 操作记录 会放到ranger 的audit 审计日志里。
2. ranger 用户创建流程
主要步骤:(1) check 是否有admin 的权限 和 创建的用户数据检验
(2) 初始化XPortalUser 和 XUser 两个数据结构对应数据库 x_portal_user, x_user,
(3) 如果有用户组信息, 将信息加入到 数据库 x_group_users 中
(4) 将操作的日志XXTRxLog 写入数据库 x_trx_log
(5) 通过XPortalUser 用户的角色 更新用户的模块权限 ,数据库对应x_user_module_perm
3. 用户删除
http://172.24.5.149: 6080/service/xusers/secure/users/delete? forceDelete=true
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-23 上传
2023-03-17 上传
2021-03-31 上传
2021-03-31 上传
2021-09-02 上传
2023-03-17 上传

weixin_38694800
- 粉丝: 4
- 资源: 1021
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
