Python爬虫实战:架构、模块与实例解析
"本文将深入探讨Python爬虫实例的实现,重点围绕爬虫技术架构及其关键组成部分进行详细讲解。首先,我们将介绍爬虫的基本工作流程,包括程序入口函数——爬虫调度段,这个函数负责启动整个爬虫过程,并通过URL管理器、HTML下载器、HTML解析器和HTML输出器等核心模块协同工作。
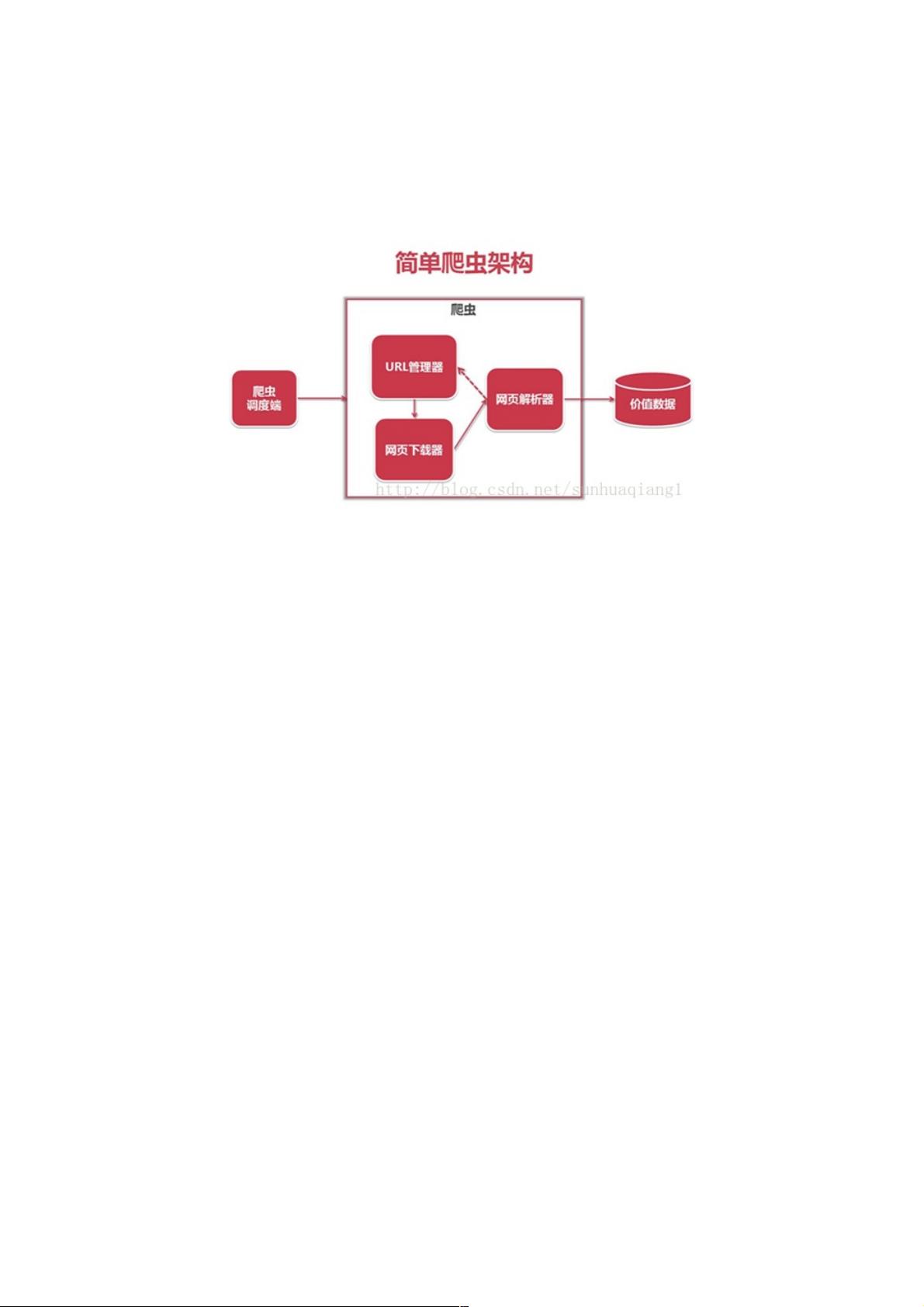
1. **爬虫技术架构**
- 爬虫通常由几个关键组件构成:程序入口函数、URL管理器、HTML下载器、HTML解析器和数据处理模块(这里提到的HTML输出器可能是指数据存储或展示的部分)。这些模块共同协作,形成一个完整的爬虫工作流程。
2. **程序入口函数与爬虫调度段**
- 代码中的`craw` 函数是爬虫的核心,它接收起始URL(root_url),并按照以下步骤执行:
- 初始化URL管理器、HTML下载器、HTML解析器和HTML输出器。
- 在循环中,当URL管理器有新的待抓取URL时,会获取新URL并下载HTML内容。
- 解析下载的HTML内容,提取新的URL并更新URL管理器,同时收集有用的数据。
- 如果达到预设的抓取次数(这里是10次),则停止循环;如果遇到异常,则输出错误信息并输出已抓取的数据。
3. **关键模块详解**
- **URL管理器**:负责管理爬虫要抓取的URL列表,添加新URL并检查是否有待抓取的URL。
- **HTML下载器**:用于从网络上下载指定URL的HTML内容,这是获取网页数据的第一步。
- **HTML解析器**:解析下载的HTML,提取出需要的信息,如链接、文本、图片等。
- **HTML输出器**:处理解析后的数据,可能是存储到数据库、文件或进行格式化输出,以便后续分析或展示。
4. **实战示例**
- 文档提供了一个简单的Python爬虫框架,通过导入自定义的类(如`maya_Spider`)中的各模块,展示了如何整合这些组件来实现一个基本的爬虫功能。
总结,本文提供了Python爬虫实例的详细实现,包括技术架构和关键模块的介绍,适合初学者和有一定基础的读者参考和实践。通过这个实例,你可以理解爬虫的工作原理,以及如何在实际项目中应用这些模块。"
python爬虫实例详解爬虫实例详解
主要为大家详细介绍了python爬虫实例,包括爬虫技术架构,组成爬虫的关键模块,具有一定的参考价值,感
兴趣的小伙伴们可以参考一下
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器、HTML下载器和HTML解析
器。
爬虫简单架构爬虫简单架构
程序入口函数程序入口函数(爬虫调度段爬虫调度段)
#coding:utf8
import time, datetime
from maya_Spider import url_manager, html_downloader, html_parser, html_outputer
class Spider_Main(object):
#初始化操作
def __init__(self):
#设置url管理器
self.urls = url_manager.UrlManager()
#设置HTML下载器
self.downloader = html_downloader.HtmlDownloader()
#设置HTML解析器
self.parser = html_parser.HtmlParser()
#设置HTML输出器
self.outputer = html_outputer.HtmlOutputer()
#爬虫调度程序
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print('craw %d : %s' % (count, new_url))
html_content = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_content)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 10:
break
count = count + 1
except:
print('craw failed')
self.outputer.output_html()
if __name__ == '__main__':
#设置爬虫入口
root_url = 'http://baike.baidu.com/view/21087.htm'
#开始时间
print('开始计时..............')
start_time = datetime.datetime.now()
obj_spider = Spider_Main()
下载后可阅读完整内容,剩余3页未读,立即下载
2024-01-12 上传
2023-08-20 上传
2023-05-26 上传
2023-06-06 上传

weixin_38674569
- 粉丝: 3
- 资源: 970
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
