Scrapy入门:创建与解析Spiders
PDF格式 | 2.28MB |
更新于2024-08-29
| 53 浏览量 | 举报
Scrapy学习笔记深入介绍了Scrapy框架的基础,特别是如何进行爬虫项目的创建。Scrapy是一个强大的Python网络爬虫框架,适用于高效地从网页抓取数据。在开始使用Scrapy之前,首先要创建一个新的项目,通过命令`scrapy startproject tutorial`,这会在指定的目录(在这个例子中是`tutorial`)中生成一个结构化的项目模板。
项目结构包括spiders文件夹,这是存放自定义爬虫代码的地方。在`spiders`目录下的`quotes_spider.py`文件中,我们定义了一个基础的爬虫类`QuotesSpider`。这个类继承自Scrapy的内置`Spider`类,因为所有的Scrapy爬虫都必须遵循这一规范。
`QuotesSpider`类包含以下关键组件:
1. `name`属性:这是爬虫的唯一标识符,确保在项目中不会出现名称冲突。在这个例子中,`name="quotes"`。
2. `start_requests()`方法:这是一个必须实现的方法,返回一个可迭代的请求列表或生成器。在这里,它定义了初始的抓取URL,如`http://quotes.toscrape.com/page/1/`和`http://quotes.toscrape.com/page/2/`。每次爬虫启动时,会按照这些URL顺序进行抓取,并在后续处理中调用`parse()`方法。
3. `parse()`方法:这是爬虫的核心逻辑,处理每个响应(`response`参数是一个`TextResponse`对象)。它首先通过`response.url.split("/")[-2]`获取当前页面的页码,并根据这个信息创建文件名。然后,它将下载的页面内容写入到本地文件中,文件名格式为`quotes-页码.html`。同时,`self.log()`方法记录了保存文件的操作,方便跟踪。
总结来说,本篇学习笔记详细讲解了如何使用Scrapy创建一个基本的爬虫,包括项目设置、爬虫类的定义及其主要方法的实现。理解这些核心概念有助于进一步深入学习和开发更复杂的网络爬虫程序。Scrapy的强大之处在于其灵活的中间件系统、下载管理器和数据存储机制,使得处理大规模数据抓取变得高效且易于维护。
Scrapy学习笔记学习笔记-Scrapy入门之创建爬虫入门之创建爬虫
Creating a project
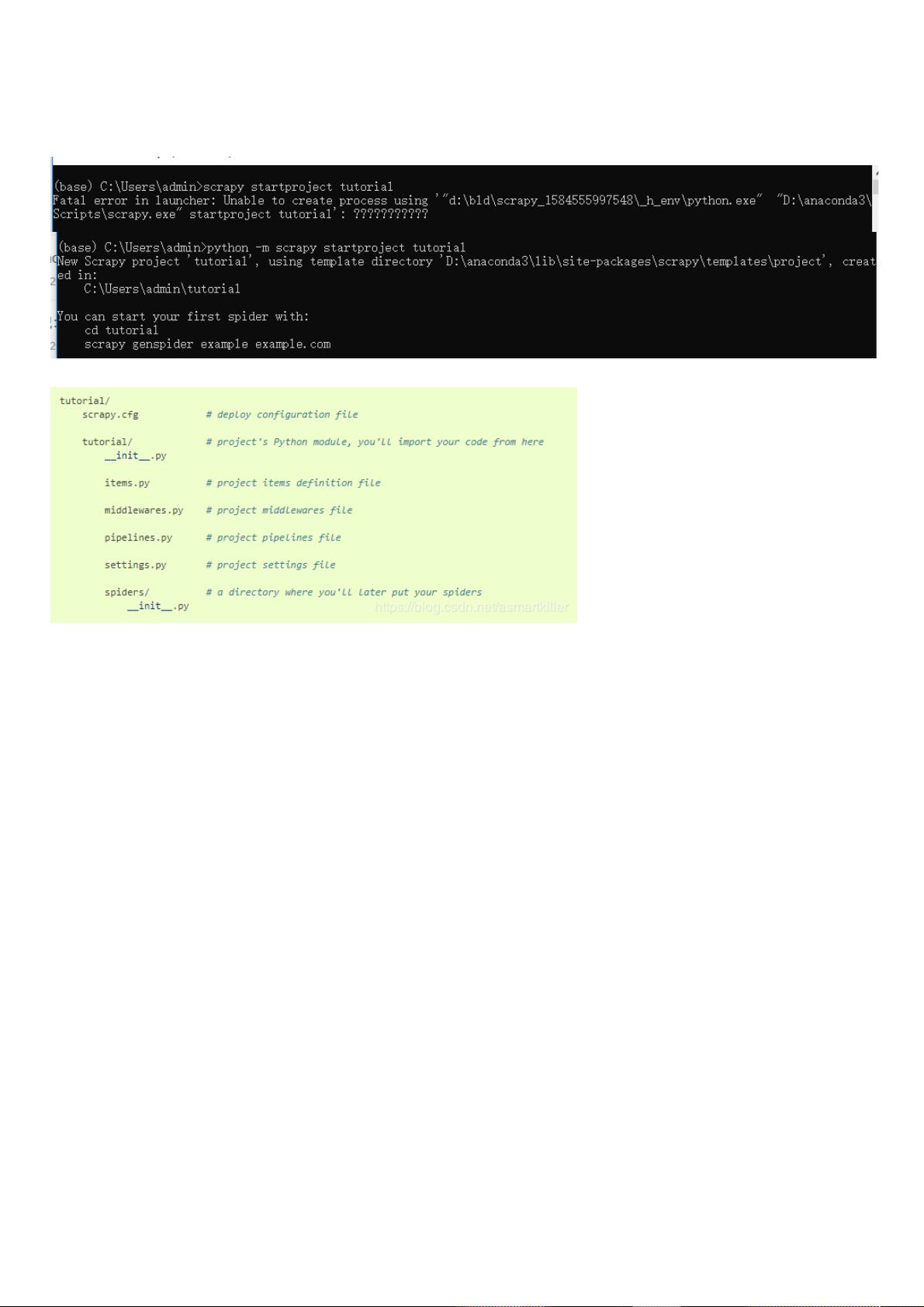
在开始抓取之前,您将必须设置一个新的Scrapy项目。 输入您要存储代码并运行的目录:scrapy startproject tutorial
Anacoda下使用
这将创建一个包含以下内容的教程目录:
Spiders是您定义的类,Scrapy用于从网站(或一组网站)中获取信息。 他们必须继承Spider的子类,并定义要发出的初始请求,可以选
择如何跟随页面中的链接,以及如何解析下载的页面内容以提取数据。
这是我们第一个Spider的代码。 将其保存在项目中tutorial/spiders目录下的一个名为quotes_spider.py的文件中:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
] for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐

196 浏览量



weixin_38631738
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 渝海QQ号码吉凶查询工具PHP源码及多样化技术项目资源
- QT串口通信数据完整性解决方案
- DTcms V5.0旗舰版MSSQL源码深度升级与功能增强
- 深入探讨单片机的整机设计与多机通信技术
- VB实现鼠标自动连点技术指南
- DesignToken2Code:Sketch插件将设计标记自动转换为SCSS代码
- 探索Android最佳实践:MVP、RxJava与热修复
- 微软日本发布Win7萌系主题包:5位萌少女主题全体验
- Scratch3.0编程启蒙源代码包:少儿教育与创造力培养
- 实现汉字简繁转换的JavaScript代码教程
- Debian环境下Alacritty终端模拟器的软件包发布
- Mybatis自动生成代码工具:快速实现代码生成
- 基于ASP.NET和SQL的选课系统开发与实现
- 全面掌握Swift开发的权威指南解析
- Java实现的HTTP代理测试工具ProxyTester
- 6至10岁儿童Scratch3.0积木编程源代码下载
