Kettle数据整合平台:从架构到实战
"kettle是Pentaho Data Integration的别名,它是一个强大的数据处理工具,专注于数据的抽取、转换和加载(ETL)过程。Kettle不仅支持各种传统数据库,如Oracle、DB2、MySQL,还兼容平面文件以及大数据环境下的Hadoop、HBase、MongoDB等数据源。它提供了Spoon、Pan和Kitchen三个客户端工具,分别用于图形化开发、执行转换和执行作业。Kettle还拥有仓库功能,支持参数、变量和日志管理,适用于数据迁移、数据库导出、大规模数据加载、数据清洗和应用集成等多种场景。"
在深入探讨Kettle架构之前,先理解其核心概念:
1. **Spoon**:作为Kettle的主要图形化开发客户端,Spoon提供了用户友好的界面,用于设计和测试ETL作业和转换。它可以构建复杂的ETL流程,同时包含对业务智能(BI)平台的语义层支持。
2. **Pan**:这是一个命令行工具,专门用于执行在Spoon中设计的转换。这使得在无图形界面的环境中也能运行数据转换任务。
3. **Kitchen**:与Pan类似,Kitchen是命令行工具,但用于执行Spoon中设计的作业。这使得可以计划和自动化作业的执行,特别是在服务器或远程环境上。
4. **Kettle Repository**:此功能允许存储和版本控制ETL作业和转换,便于团队协作和数据版本管理。
5. **Architecture**:Kettle的架构设计允许高度分布式和并行处理。它使用插件式体系结构,可以轻松扩展以支持新的数据源和操作。
6. **Transformation**:转换是Kettle中的核心组件,定义了一系列步骤来处理数据。这些步骤可以包括数据抽取、清洗、转换和加载。
7. **Steps**:Kettle提供了丰富的预定义步骤,如读取/写入数据库、转换字段、过滤数据等,开发者可以根据需求组合使用。
8. **Mapping**:映射是高级用户使用的一种技术,用于创建复杂的逻辑流,可以将多个步骤打包在一起。
9. **Arguments, Parameters, and Variables**:这些是Kettle中配置和动态化ETL流程的关键元素。参数和变量允许外部值注入,而参数则常用于作业和转换的可重用性。
10. **Job**:作业是Kettle中组织和调度转换的容器。它们可以包含多个转换,并通过条件、循环和其他控制流程结构链接它们。
11. **Lab Studies**:在学习和实践中,Kettle的实验研究部分提供了一种方法来理解和实践各种功能,帮助用户熟悉工具和最佳实践。
12. **Run Remotely**:Kettle支持远程执行作业和转换,这在多服务器或分布式环境中的部署中尤其有用。
13. **Log Management**:Kettle提供日志记录机制,确保了ETL过程的可追踪性和问题诊断能力。
Kettle作为一个全面的ETL工具,具备广泛的数据源支持、强大的开发和执行工具、灵活的架构以及良好的团队协作和管理特性,使其成为数据处理和整合的有力武器。无论是小型项目还是大型企业级解决方案,Kettle都能够满足数据处理的需求。

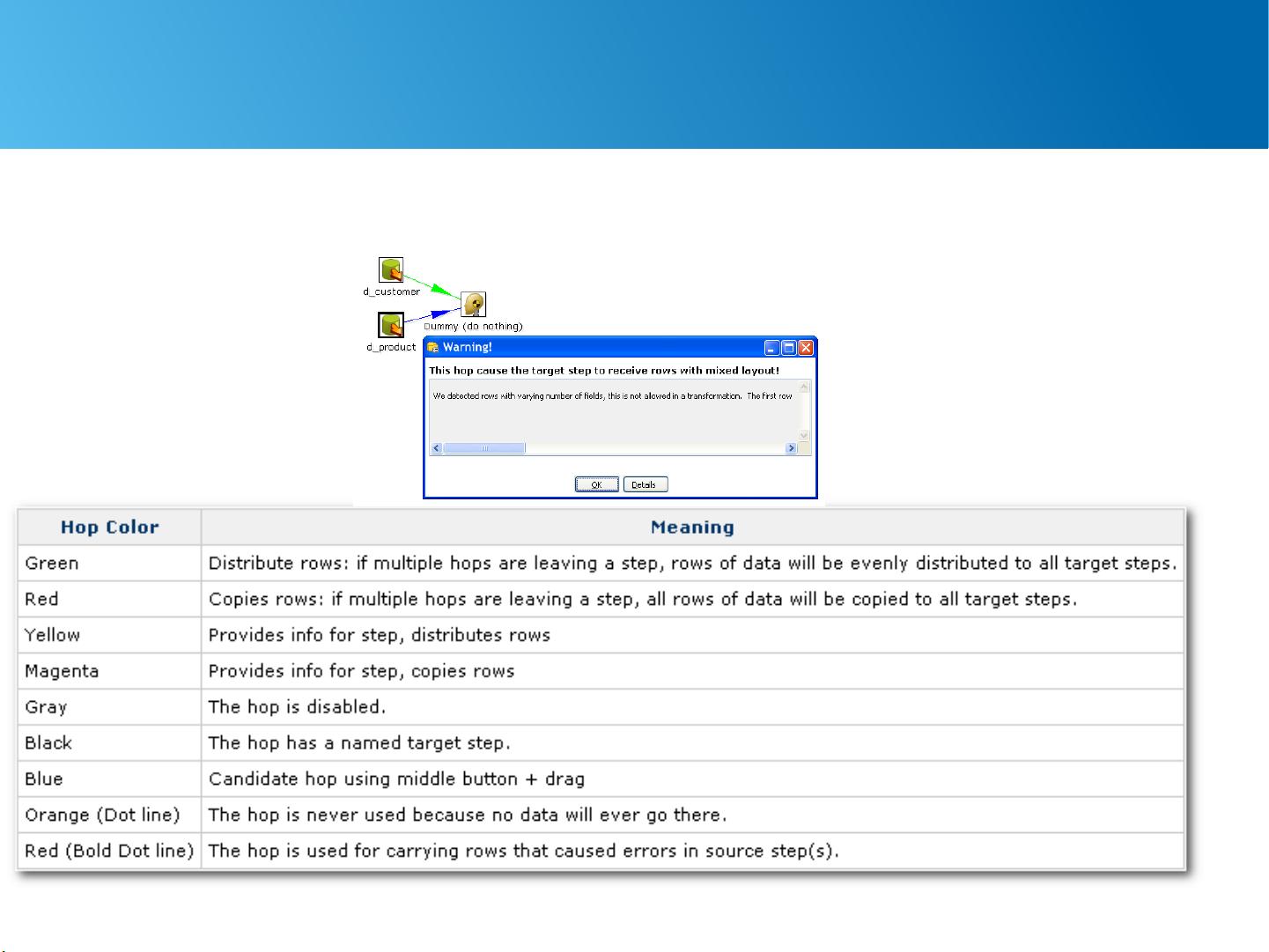
Several Concepts of Transformation
• Step
• Hop
• Mapping
• Note
– Text comments for transformation
• Row
– Lines in input stream or output stream. e.g. row[0] refers to first row values.
• Field
– The column of row. e.g. Fieldname.setValue(“lengpeng”)
• Values
– Values is a part of row, :value type contains Strings, floating point Numbers,unlimited
precision BigNumbers, Integers, Dates and Boolean, e.g. fieldname.getString()
• Input Stream
– Data stream of input step.
• Output Stream
– Data stream of output step.
- 10 -

剩余64页未读,继续阅读
2017-09-11 上传
2019-07-05 上传
2023-06-06 上传
2024-04-19 上传
2023-06-10 上传
2023-06-10 上传
2023-08-29 上传
2024-06-13 上传

lzjlzp2012
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







