BERT模型在提取式摘要中的微调与应用
需积分: 24 96 浏览量
更新于2024-07-09
收藏 2.65MB PPTX 举报
"《Fine-tune BERT for Extractive Summarization》论文分享.pptx"
这篇PPT分享主要探讨了如何将预训练的BERT模型应用于提取式文本摘要任务。提取式摘要是一种从原始文本中挑选关键句子形成摘要的技术。
首先,让我们回顾一下BERT(Bidirectional Encoder Representations from Transformers)的基础知识。BERT模型由Google于2018年提出,它通过两个主要任务进行预训练:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。MLM的任务是遮盖输入序列中的一部分词,让模型根据上下文预测被遮盖的词,这有助于模型理解语言的内在结构。NSP则要求模型判断两个句子是否在原文本中相邻,从而增强模型对上下文关系的理解。
在BERT的输入层,包括Token Embeddings、Segment Embeddings和Position Embeddings。Token Embeddings捕捉单个词的语义信息,Segment Embeddings用于区分不同句子,而Position Embeddings则编码词在序列中的位置信息。
然而,对于抽取式文本摘要,原始的BERT模型并不直接适用,因为它设计时考虑的是句子对而非多个句子的集合。论文指出,由于抽取式摘要涉及多个句子的选取,所以需要对BERT的输入层进行改造,以适应多句文档的编码。论文提出了一个新的方法,将一个文档表示为一系列句子senti,并对每个句子赋予是否应包含在摘要中的标签(0或1)。
在方法部分,论文可能详细介绍了如何调整BERT的架构,使其能够处理多句输入并进行序列标注任务。这通常涉及到对每个句子进行二分类,即判断其是否应该出现在摘要中。通过训练这样的标注模型,可以得到一系列标记为1的句子,这些句子将组合成最终的摘要。此外,还可能涉及句子排序任务,计算每个句子作为摘要的概率,然后选择概率最高的若干句子。
在实验部分,论文可能对比了改进后的BERT模型与传统方法在抽取式摘要任务上的表现,包括ROUGE和BLEU等评估指标,以证明新方法的有效性。结果部分应该展示了这些对比实验的详细结果和分析。
这篇论文探讨了如何利用BERT的强大预训练能力来优化提取式文本摘要,通过对模型的调整以适应多句子输入,提高了摘要生成的准确性和效率。这对于自然语言处理领域的研究者和实践者来说,具有很高的参考价值。
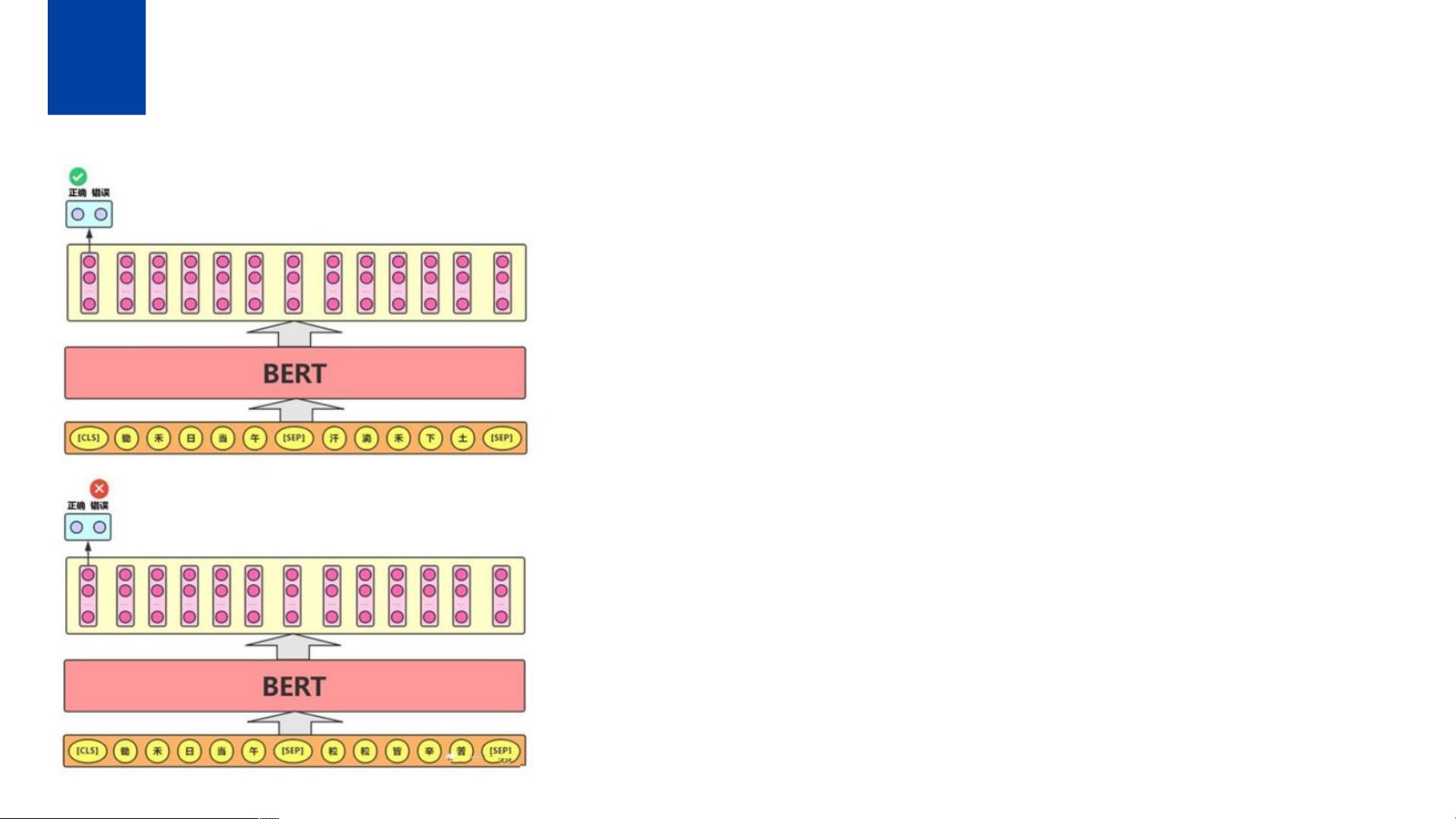
Bert 语言模型任务二: Next Sentence Prediction
背景知识
给定一篇文章的上下两句话,判断第二句话是否紧跟在第一句话之后
剩余21页未读,继续阅读
2022-08-07 上传
2023-05-19 上传
2024-01-06 上传
2024-06-03 上传
2023-08-24 上传
2021-07-22 上传
2021-05-18 上传
2013-05-14 上传

victor5027
- 粉丝: 4
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







