
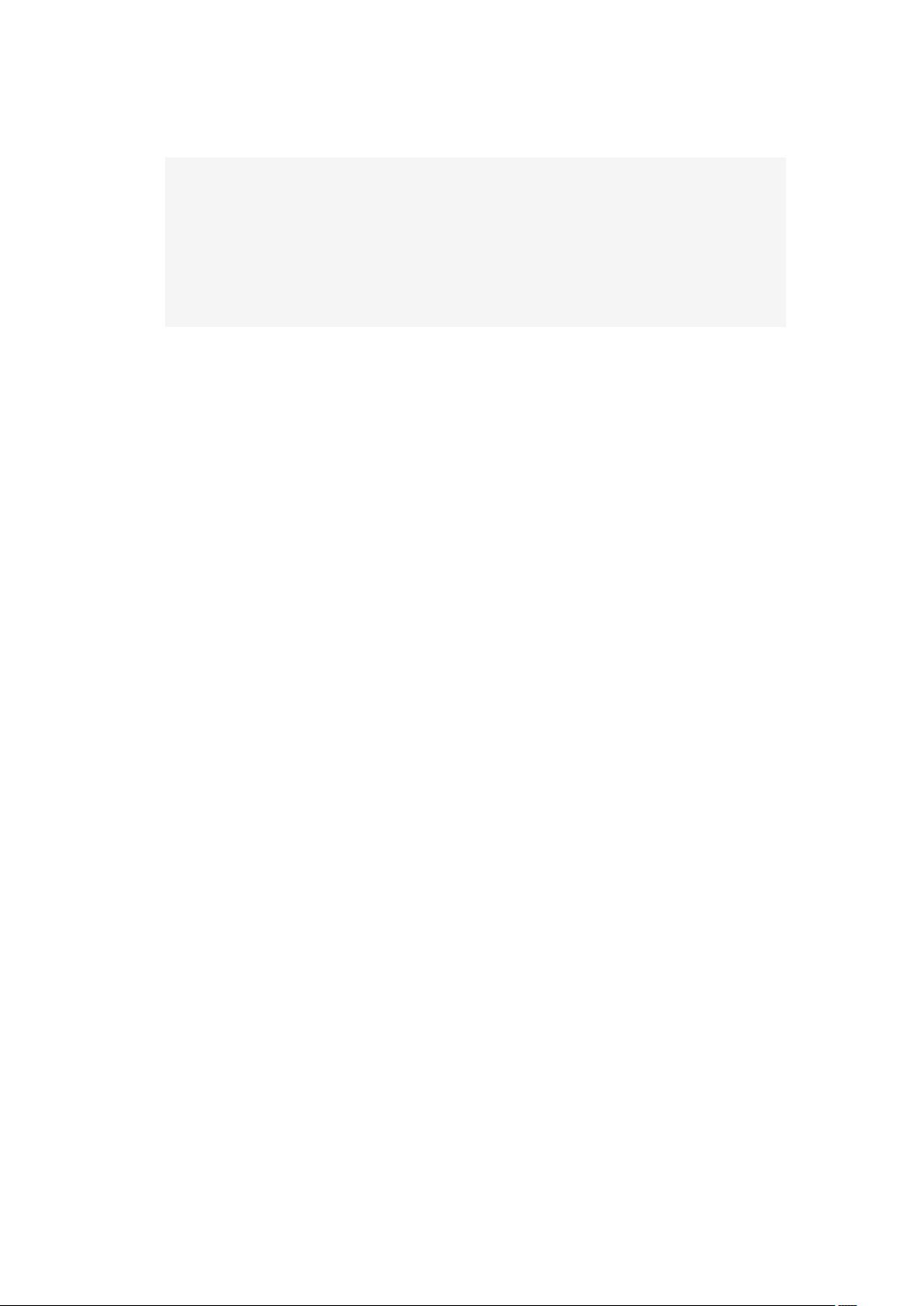
每次我们需要获取最新评论的项目范围时,我们调用一个函数来完成(使用伪代码):
1. FUNCTION get_latest_comments(start, num_items):
2. id_list = redis.lrange("latest.comments",start,start+num_items - 1)
3. IF id_list.length < num_items
4. id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
5. END
6. RETURN id_list
7. END
这里我们做的很简单。在 Redis 中我们的最新 ID 使用了常驻缓存,这是一直更新的。但是我们
做了限制不能超过 5000 个 ID,因此我们的获取 ID 函数会一直询问 Redis。只有在 start/count 参数
超出了这个范围的时候,才需要去访问数据库。
我们的系统不会像传统方式那样“刷新”缓存,Redis 实例中的信息永远是一致的。SQL 数据库
(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个
评论页是不会麻烦到硬盘上的数据库了。
➢ 2、删除与过滤
我们可以使用 LREM 来删除评论。如果删除操作非常少,另一个选择是直接跳过评论条目的入口,
报告说该评论已经不存在。
有些时候你想要给不同的列表附加上不同的过滤器。如果过滤器的数量受到限制,你可以简单的
为每个不同的过滤器使用不同的 Redis 列表。毕竟每个列表只有 5000 条项目,但 Redis 却能够使用
非常少的内存来处理几百万条项目。
➢ 3、排行榜相关
另一个很普遍的需求是各种数据库的数据并非存储在内存中,因此在按得分排序以及实时更新这
些几乎每秒钟都需要更新的功能上数据库的性能不够理想。
典型的比如那些在线游戏的排行榜,比如一个 Facebook 的游戏,根据得分你通常想要:
- 列出前 100 名高分选手
- 列出某用户当前的全球排名
这些操作对于 Redis 来说小菜一碟,即使你有几百万个用户,每分钟都会有几百万个新的得分。
模式是这样的,每次获得新得分时,我们用这样的代码:
ZADD leaderboard <score> <username>
你可能用 userID 来取代 username,这取决于你是怎么设计的。
得到前 100 名高分用户很简单:ZREVRANGE leaderboard 0 99。
用户的全球排名也相似,只需要:ZRANK leaderboard <username>。
➢ 4、按照用户投票和时间排序
剩余16页未读,继续阅读

有只风车子
- 粉丝: 36
- 资源: 329
 我的内容管理
展开
我的内容管理
展开







最新资源
- 中国微型数字传声器:技术革新与市场前景
- 智能安防:基于Hi3515的嵌入式云台控制系统设计
- 手机电量低时辐射真增千倍?解析手机使用谣言
- 56F803型DSP驱动的高精度大功率超声波电源控制策略研究
- ARM与GPRS结合的远程监测系统设计
- GPS与RFID技术结合的智能巡检系统设计
- CPLD驱动的低功耗爆炸场温度测试系统设计
- 基于FPGA的智能驱动控制系统:可扩展设计与工业网络协议
- 基于ATmega128和CH374的嵌入式USB接口设计
- 基于AT89C52的温度补偿超声波测距仪:高精度设计与应用
- MSP430F448单片机在交流数字电压表中的应用
- 提升变频器应用效率的12项实用技巧
- STM32F103在数字电镀电源并联均流系统中的应用
- PSpice仿真下的升压开关电源设计:拓扑分析与CCM稳定性提升
- 轻巧高效:MSP430主导的低成本无线传感器网络节点设计
- FPGA在EDA/PLD中实现LVDS接口的应用解析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


