Linux内核链表数据结构详解
"深入分析Linux内核链表的数据结构"
在Linux内核中,链表是一种核心的数据结构,用于高效地管理内存和数据组织。本文深入探讨了Linux内核中的链表实现,包括单链表、双链表和循环链表等不同类型,并详细介绍了Linux 2.6内核链表数据结构的实现。
一、链表数据结构概述
1. 链表的基本概念
链表是一种动态数据结构,与数组相比,它允许在运行时动态地添加和删除元素,而无需预先确定数组大小。每个链表节点由两部分组成:数据域(存储实际数据)和指针域(指向下一个节点)。根据指针的组织,链表可分为单链表、双链表和循环链表。
2. 单链表
单链表只包含一个指针域,即next指针,指向下一个节点。遍历单链表只能从头到尾,不支持双向遍历。
3. 双链表
双链表拥有前驱指针(prev)和后继指针(next),支持双向遍历。若首节点的前驱指针指向尾节点,尾节点的后继指针指向首节点,就形成了循环链表。
4. 循环链表
循环链表的最后一个节点的next指针指向链表的第一个节点,形成一个闭合的环。这使得从链表的任何位置出发,都可以遍历整个链表。
二、Linux 2.6内核链表实现
1. 基本链表结构
Linux内核的链表实现位于`<include/linux/list.h>`头文件中,定义了一个名为`list_head`的结构体,用于表示链表节点。`list_head`包含两个指针成员,`next`和`prev`,分别指向链表的下一个和上一个节点。
```c
struct list_head {
struct list_head *next, *prev;
};
```
2. 链表操作函数
内核提供了一系列宏和函数来操作链表,如`list_add()`用于在链表末尾添加节点,`list_del()`用于删除节点,`list_empty()`检查链表是否为空等。
3. RCU(Read-Copy-Update)链表
在Linux 2.6内核中引入了RCU机制,用于在多处理器系统中实现非阻塞的链表操作。RCU链表允许读者在链表更新时继续执行,从而提高了并发性能。
4. HASH链表(hlist)
HASH链表提供了一种更高效的数据查找方法,特别适用于大量数据的快速查找。它使用哈希函数将节点分散在多个链表中,以降低查找复杂度。
三、链表在Linux内核中的应用
Linux内核广泛使用链表来组织数据,例如设备驱动模型中的设备列表、内存管理中的页面链表等。内核中的链表不仅用于简单的线性数据结构,还可以构建复杂的树形结构,如红黑树等。
总结来说,Linux内核的链表数据结构是其核心组件之一,它通过高效的数据组织和操作,实现了内存管理、设备驱动、进程调度等关键功能。理解并熟练掌握链表的使用对于深入理解和调试内核代码至关重要。
深入分析 Linux 内核链表的数据结构
一、 链表数据结构简介
链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连
接成一条数据链,是线性表的一种重要实现方式。相对于数组,链表具有更好
的动态性,建立链表时无需预先知道数据总量,可以随机分配空间,可以高效
地在链表中的任意位置实时插入或删除数据。链表的开销主要是访问的顺序性
和组织链的空间损失。
通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,
指针域用于建立与下一个节点的联系。按照指针域的组织以及各个节点之间的
联系形式,链表又可以分为单链表、双链表、循环链表等多种类型,下面分别
给出这几类常见链表类型的示意图:
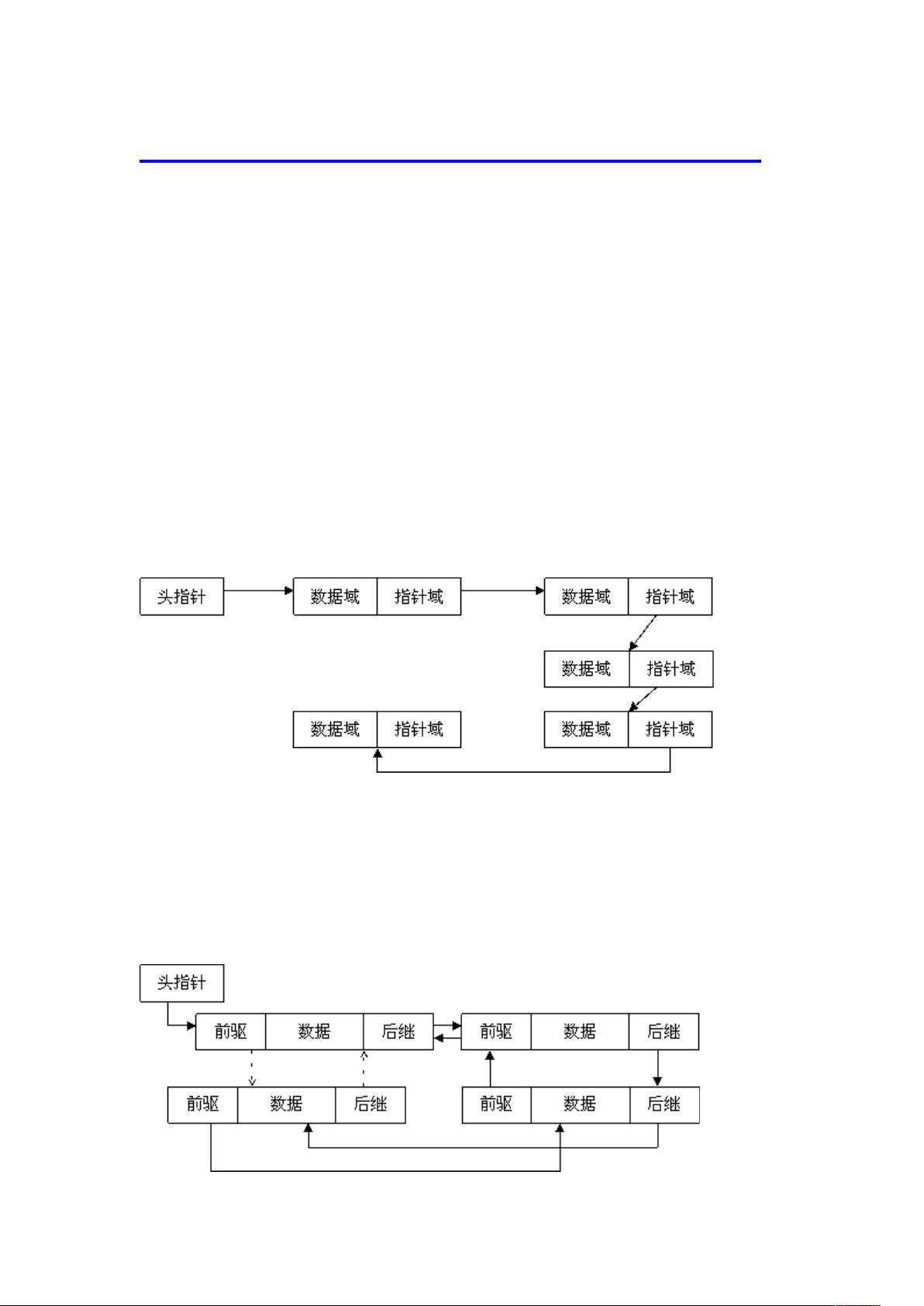
1. 单链表
图 1 单链表
单链表是最简单的一类链表,它的特点是仅有一个指针域指向后继节点
(next),因此,对单链表的遍历只能从头至尾(通常是 NULL 空指针)顺序
进行。
2. 双链表
图 2 双链表
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
135 浏览量
132 浏览量
2019-09-21 上传
2022-02-23 上传
103 浏览量
2013-04-04 上传
284 浏览量
2009-04-04 上传

q123456789098
- 粉丝: 314
 我的内容管理
展开
我的内容管理
展开







最新资源
- Juicy-Potato:Windows本地权限提升工具新秀
- Matlab实现有限差分声波方程正演程序
- SQL Server高可用Alwayson集群搭建教程
- Simulink Stateflow应用实例教程
- Android平台四则运算计算器简易实现
- ForgeRock身份验证节点:捕获URL参数到共享状态属性
- 基于SpringMVC3+Spring3+Mybatis3+easyui的家庭财务管理解决方案
- 银行专用大华监控视频播放器2.0
- PDRatingView:提升Xamarin.iOS用户体验的评分组件
- 嵌入式学习必备:Linux菜鸟入门指南
- 全面的lit文件格式转换解决方案
- 聊天留言网站HTML源码教程及多功能项目资源
- 爱普生ME-10打印机清理软件高效操作指南
- HackerRank问题解决方案集锦
- 华南理工数值分析实验3:计算方法实践指南
- Xamarin.Forms新手指南:Prism框架实操教程
