Flume-Kafka-Storm数据流整合实战
"Flume+kafka+Storm整合的示例介绍及配置步骤"
在这个整合示例中,我们涉及了三个关键组件:Flume、Kafka和Storm,它们都是大数据处理和流处理的重要工具。
Flume是Apache开发的一个分布式、可靠且可用于有效收集、聚合和移动大量日志数据的系统。在本示例中,Flume被配置为通过netcat源(r1)接收telnet数据。Flume的配置文件(如a1.sources.r1.type=netcat)定义了数据来源类型,即通过telnet接口接收数据。一旦接收到数据,Flume会将其发送到配置的通道(c1)。
Kafka是一个高吞吐量的分布式消息系统,它在这里作为数据的中间存储。Flume将接收到的数据发送到Kafka,Kafka作为Storm的spout,也就是数据输入源。在Kafka的配置中,需要修改server.properties文件,并在集群中分发,确保broker.id在不同节点上不一致。为了测试,可以创建一个新的topic,并分别创建生产者和消费者来发送和接收数据。
Storm是一个实时计算系统,它能处理连续的数据流并进行低延迟的处理。在本例中,Storm从Kafka获取数据,进行有向无环图(DAG)分析。生产者类负责向Kafka发送数据,而消费者类则持续读取这些数据。编写Storm代码后,需要启动Zookeeper和Storm服务,以便协调和管理数据流处理。
整合步骤包括:
1. 下载并配置Flume,设置好flume-env.sh模板,创建并配置运行文件,启动Flume,然后通过telnet发送数据以测试Flume的接收功能。
2. 下载、解压并配置Kafka,创建topic,设置生产者和消费者,验证Kafka是否正常工作。
3. 安装并配置Storm,编写Java生产者和消费者类,打包并放入Flume的lib目录,启动Zookeeper和Storm服务。
4. 配置新的Flume代理,编写KafkaSink类,让Flume能够将数据写入Kafka。
5. 使用Flume通过telnet发送数据,由Storm进行实时处理。
这个整合流程展示了如何构建一个实时数据流处理系统,从数据的生成(telnet)到收集(Flume),再到存储(Kafka)和分析(Storm)。这种架构在大数据实时分析和监控场景中非常常见,例如日志分析、用户行为追踪等。
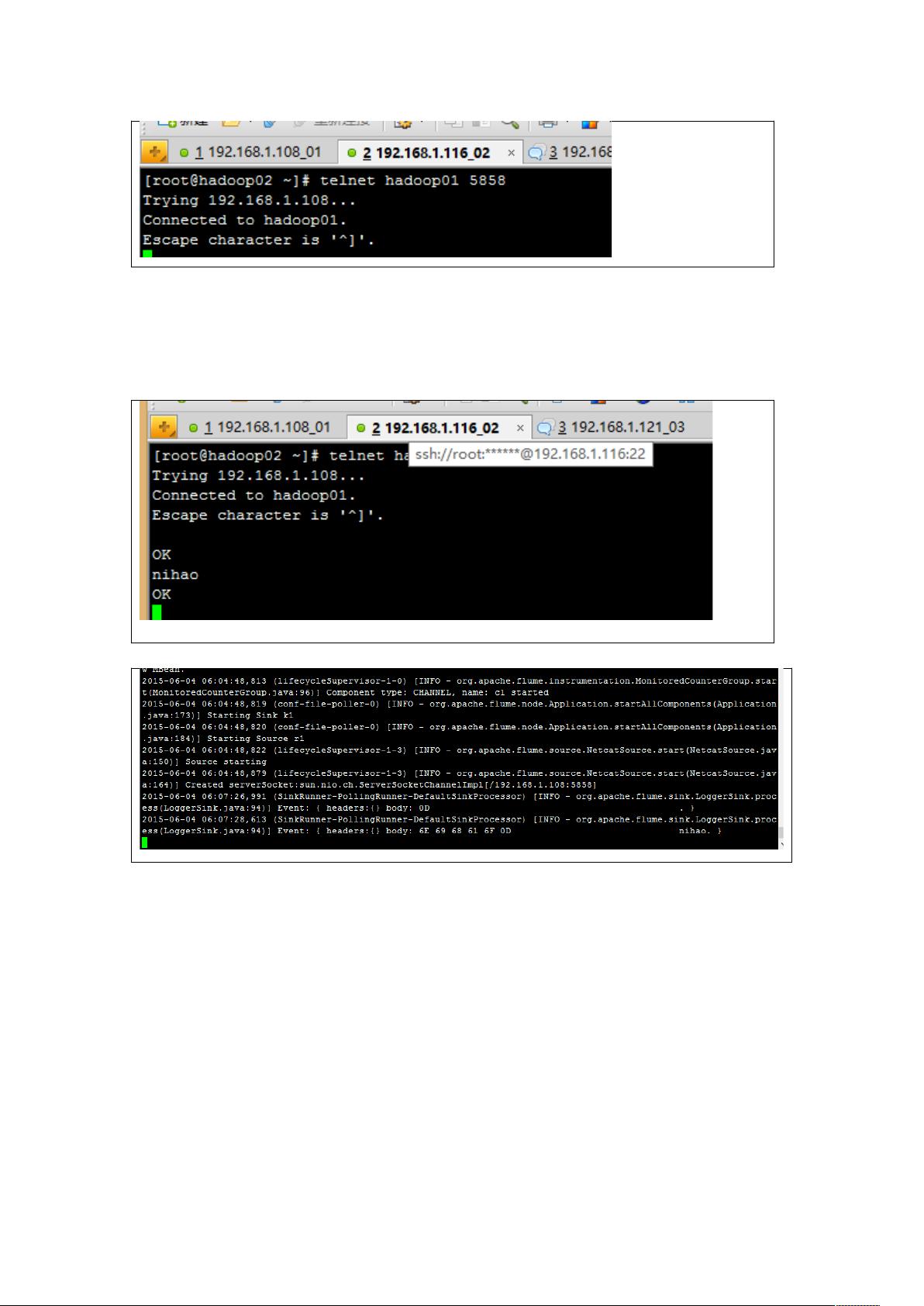
按回车。
发送数据:
' 方面接收数据情况。
Flume 测试成功!
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-06-29 上传
386 浏览量
2017-05-04 上传
点击了解资源详情
点击了解资源详情

tiantang259
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 【地产资料】XX地产 店长管理核心大纲P39.zip
- JavaEE7+Spring4 + hibernate5企业级数据校验
- ECOR1042-Project
- HTML5 Canvas星星笑脸动画.rar
- ant-pro-ui:桐乡市系统安全监管系统
- Excel模板材料存量计划表.zip
- 2014-2020年扬州大学353卫生综合考研真题
- LeapMotion-Foot-Gesture-Recognition:使用 LeapMotion 跟踪和学习基于脚的交互的库
- sample_app
- rust-spice:可在Rust上使用的NASANAIF Spice工具包
- appblog
- Time2Vec-PyTorch:复制纸张
- matlab-(含教程)基于FMM+Criminisi算法彩色图像修复matlab仿真
- Excel模板销售清单模板.zip
- 毕业设计&课设--毕业设计-销售管理系统.zip
- 参考-数值分析.zip
