BootMAE:提升视觉BERT预训练的自举掩蔽自编码器
91 浏览量
更新于2024-06-19
收藏 868KB PDF 举报
"自举掩蔽自编码器:视觉BERT预训练方法改进"
本文提出了一种新的视觉BERT预训练方法——自举掩蔽自编码器(BootMAE),它针对原始的掩码自编码器(MAE)进行了两项关键改进,以优化视觉Transformer模型的预训练效果。视觉BERT预训练的主要目标是学习能够捕捉图像语义信息的表示,这在后续的下游任务如图像分类、语义分割和目标检测中至关重要。
首先,BootMAE引入了动量编码器(Momentum Encoder)。这个设计是基于一个观察,即使用预训练的MAE提取的特征作为BERT预测目标能提高预训练性能。动量编码器与原始的MAE编码器并行运行,通过持续更新其表示并将其用作预测目标,进一步增强模型的学习能力。
其次,为了减轻编码器在记忆目标特定信息上的负担,BootMAE采用了目标感知解码器(Target-Aware Decoder)。在传统的MAE中,编码器可能需要存储未掩蔽区域的信息,这可能会分散其对语义建模的注意力。目标感知解码器则直接将这些目标特定信息(如未掩蔽像素的值)传递给解码器,使得编码器可以更加专注于捕获图像的全局语义,而无需保留细节信息。
实验证明,BootMAE在多个视觉任务上都表现出了显著的提升。使用ViT-B作为基础架构,在ImageNet-1K图像分类任务上,BootMAE的Top-1准确率比MAE提高了2%。在ADE20K语义分割任务上,BootMAE实现了+1.0 mIoU的提升,而在COCO数据集的目标检测和分割任务中,分别提高了1.3 box AP和1.4 mask AP。
自监督学习是机器学习领域的一个重要研究方向,尤其是对于视觉Transformer模型,预训练阶段的表现直接影响到模型在无标注数据上的学习效果和在各种下游任务中的应用性能。BootMAE通过巧妙的机制优化了这一过程,展示了其在提升模型泛化能力和学习效率方面的潜力。此研究的代码已经开源,可供研究人员和开发者进一步探索和使用。
+v:mala2255获取更多论
文
Q
输入
要素
多头
K
Self-Attention
V
FFN
∈
×
∪ ∩
∅
2
可见代币
用于像素回归的掩码
标记
用于特征预
测的掩码
标记
低级别
特征
注入
编码器
像素回归
掩模
…
特征预测器
输入线
屏蔽输入
可视补丁
可见代币
EMA更新
动量编码器
高级特征
复方甘草
酸苷
注射液
…
(a)BootMAE的培训管道
图像编码器特征预测器
像素
回归
块
(b)图像编码器块(c)特征预测块像素回归块
Q
Q
多头多头多头
K
Self-Attention
V
K 交叉
注意
V
FFN
交叉
特征
输入
要素
像素回归
损失
特征预测
损失
BootMAE for Vision BERTPretraining 5
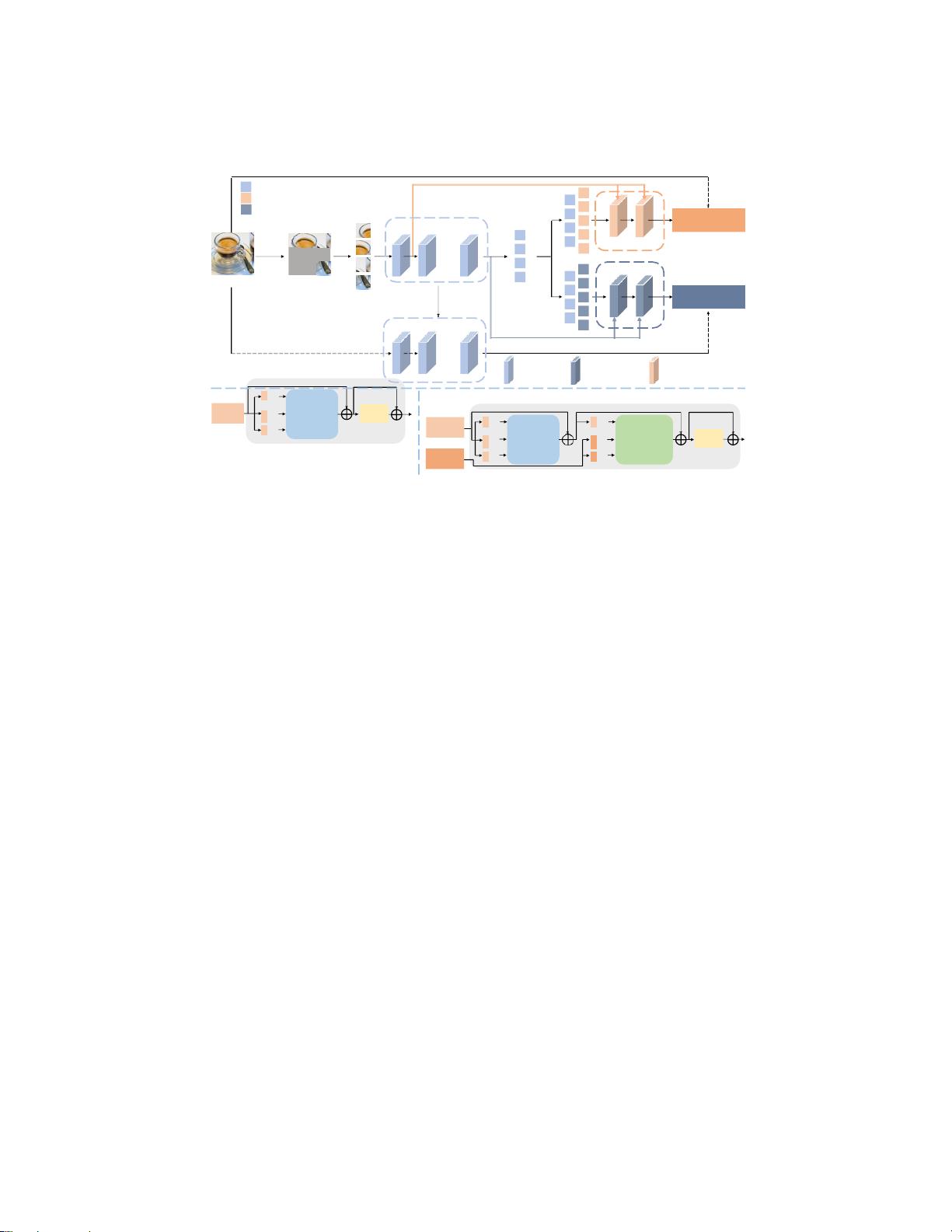
图图1:在(a)总体框架和训练管道,(b)图像编码器块,(c)特
征预测器块像素回归器块中说明我们的BootMAE的细节
3
方法
在本节中,我们将详细介绍我们的Bootstrapped MAE框架。如图1所示,
我们的框架包含四个组件:1)编码器网络,专注于学习结构知识; 2)像
素回归器解码器网络,旨在根据来自编码器的结构知识和来自可见补丁
的上下文信息预测掩蔽区域的丢失像素,即,在这种情况下是像素值或
低级特征; 3)特征预测器解码器网络尝试在给定来自编码器的相同结构
知识和可见块的上下文信息的情况下对掩蔽区域进行特征预测,即,在
这种情况下是高级特征信息;以及4)特征注入模块,其在每个解码器层
中将每个自己的上下文信息显式地和连续地馈送到回归器和预测器中。
在使用我们的BootMAE进行自我监督预训练后,我们采用编码器网络进
行各种下游任务。
形式上,假设输入图像为XR
H×W
×C
,
其中
H
和
W
表示图像高度和
图像宽度,
C
表示通道数,我们首先将其分割为不重叠的块。这导致
N
=
H W/P
2
块,其中
P
表示每个块的分辨率。 以这种方式,图像由多
个补丁X
=
{
x
1
,
x
2
,
···
,
xN
}
表示,
其中
xn
∈
R
P
C
表示从图像补丁整形
的向量。此后,大部分,比如说
Nm
块被随机采样以被掩蔽,并且留下
剩余的
Nv
块
可见,
N
=
Nm
+
Nv
。
设
M
是
屏蔽图
的
指数
集
,
Xv
=
{
xk
|
k
∈
/
M}
表
示
可解
集,
Xm
=
{
xk
|
k
∈
M}
表示
掩码面片的集合,我们有X
=
X
v
X
m
和
X
v
X
m
=
.通常,每个片与指示每个片
剩余21页未读,继续阅读
281 浏览量
8431 浏览量
215 浏览量
2024-11-05 上传
2024-11-05 上传
2024-11-05 上传
254 浏览量
137 浏览量
109 浏览量

cpongm
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java编码规范详解:提升代码质量
- Struts实战指南:构建高效Web应用
- 技术管理20年:从启蒙到感悟
- 串口通信实验:理解MFC下的Windows串口编程
- C++编程基础与学习笔记
- 嵌入式Linux开发全攻略:从入门到精通
- 互联网搜索引擎:工作原理与系统构建深度解析
- iBATIS SQL Maps开发详解:快速上手与优化策略
- Spring源代码深度解析:IoC容器与关键模块详解
- 24小时速成Visual C# 2008编程全指南
- 精通Symbian OS C++智能手机开发实战指南
- Windows CE编程疑难解答与资源分享
- DataGuard学习教程:从基础到高级
- 三层楼企业网络组建:VLAN划分与通信实现
- 安全入门:挑选示波器测试探头的全面指南
- 贪婪算法与最优化问题:从货箱装船到最短路径
